DeepSeek's Image Recognition Debut Rocks the AI World: I Pushed Its Limits with 12 Tricky Images
 04/30 2026
04/30 2026
 608
608
DeepSeek Completes the Final Piece of the Puzzle!
Five days after DeepSeek's V4 update rocked the tech world, Chen Xiaokang, a DeepSeek researcher responsible for multimodal capabilities, posted this on X, along with the caption:
Now, we see you.
(Image credit: Leitech)
Yes, that's exactly what it means.
While everyone was still marveling at V4's pricing and coding capabilities, DeepSeek suddenly launched its image recognition mode, finally delivering on the multimodal capabilities that had been a hot topic across the internet for a whole year.
The pace of updates genuinely makes one wonder if Liang Wenfeng, to avoid being memed by netizens for negligence, locked the development team in the server room overnight.
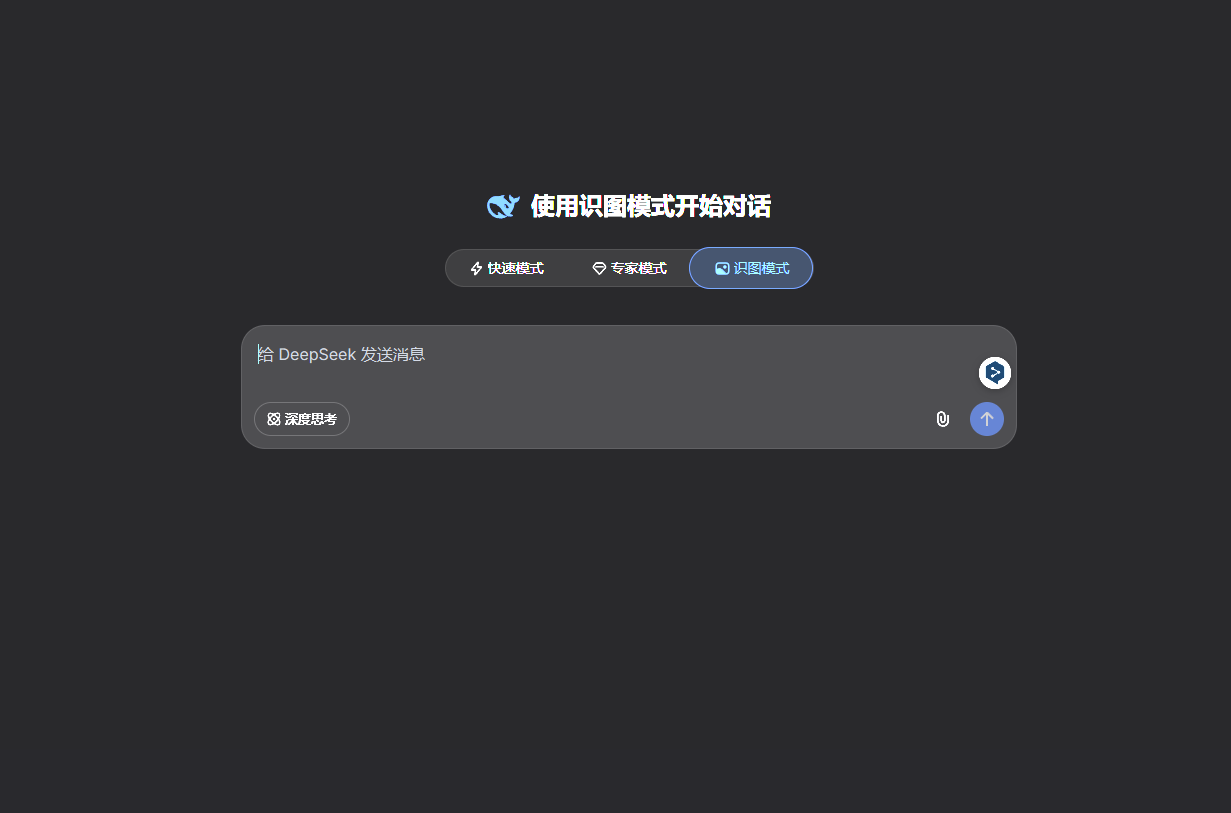
It's important to note that this test was not a full-scale rollout but a small-scale grayscale test. Only some users could see it in DeepSeek's official app or web version. In addition to the existing Quick Mode and Expert Mode above the input bar, a new Image Recognition Mode button would appear, labeled "Image Understanding Function Beta Test."
(Image credit: Leitech)
Unfortunately, none of my colleagues were selected for the grayscale test—zero out of all DeepSeek's official draws!
Fortunately, I turned out to be the chosen one among thousands.
Given this coincidence, I'd feel guilty not putting DeepSeek through its paces. I carefully selected 12 images to show exactly what DeepSeek can—and cannot—see.
Strong Understanding, Knowledge Base Needs Updating
Without further ado, let's dive into image description testing.
I prioritized this because it represents one of the most practical applications of visual understanding in real-world scenarios.
Take our daily lives, for example: when encountering an unfamiliar plant on the street, searching for a clothing match, or staring at a foreign-language menu abroad, the first instinct is now to take a photo and ask AI, "What is this?"
This "see-and-ask" interaction essentially tests the model's visual understanding capabilities.
For this test, I prepared three images: a cosplayer photo, a museum exhibit, and a complex event scene.

(Image credit: Leitech)
Prompt: Please describe this image in detail, within 250 words.
For the first image, DeepSeek responded as follows:

(Image credit: Leitech)
Indeed, DeepSeek not only described the entire scene in detail but also identified the character and accurately reconstructed elements like background and lighting. This description could directly generate a highly similar image using a text-to-image model.
Keep in mind, this was without Thinking Mode enabled.
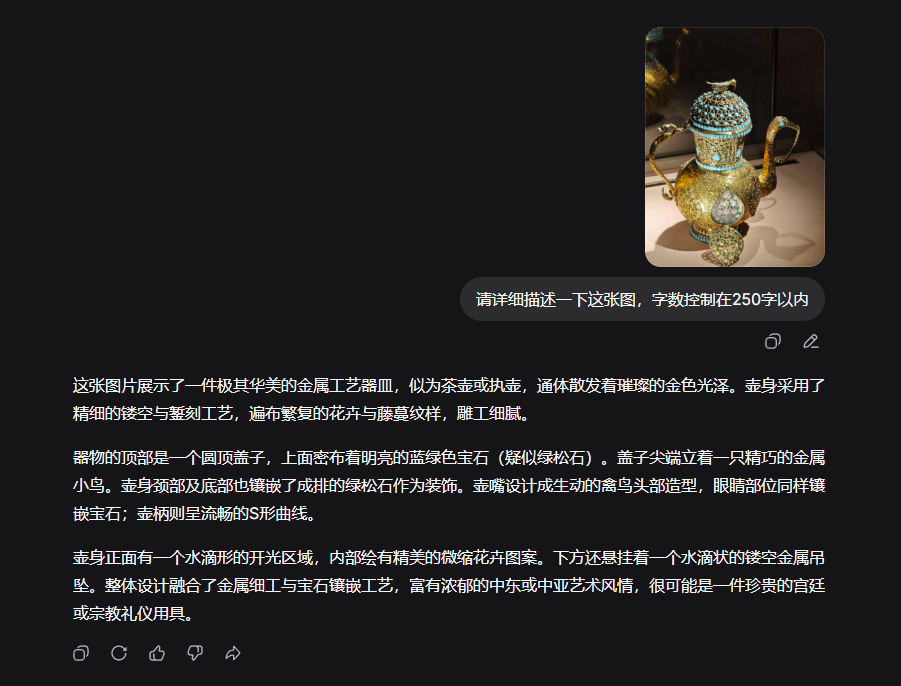
For the second image, DeepSeek's response was:
(Image credit: Leitech)
Without Thinking Mode, the response focused purely on visual description without analyzing the object. However, the description was quite accurate, noting the item's strong Middle Eastern or Central Asian artistic style, suggesting it might be a precious royal court (palace) or religious artifact. (Note: " royal court " left untranslated as it refers to a specific cultural context)
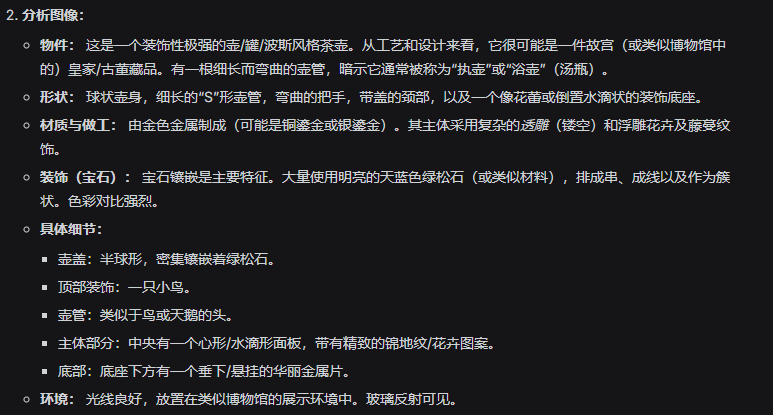
What if I enable Thinking Mode?
Now it begins analyzing, first dissecting the object, defining what it is, its characteristics, and its environment.
(Image credit: Leitech)
Then it concludes that the style resembles Hindustani art from the Qing Dynasty.

(Image credit: Leitech)
What exactly is Qing Dynasty Hindustani style? According to Wikipedia, this refers to Central Asian Islamic jade art introduced during Emperor Qianlong's reign in the 18th century, primarily originating from the Mughal Empire in North India.
Coincidentally, I visited a Mughal Empire exhibition, and DeepSeek's identification was correct.

(Image credit: Leitech)
For the third image, DeepSeek responded:
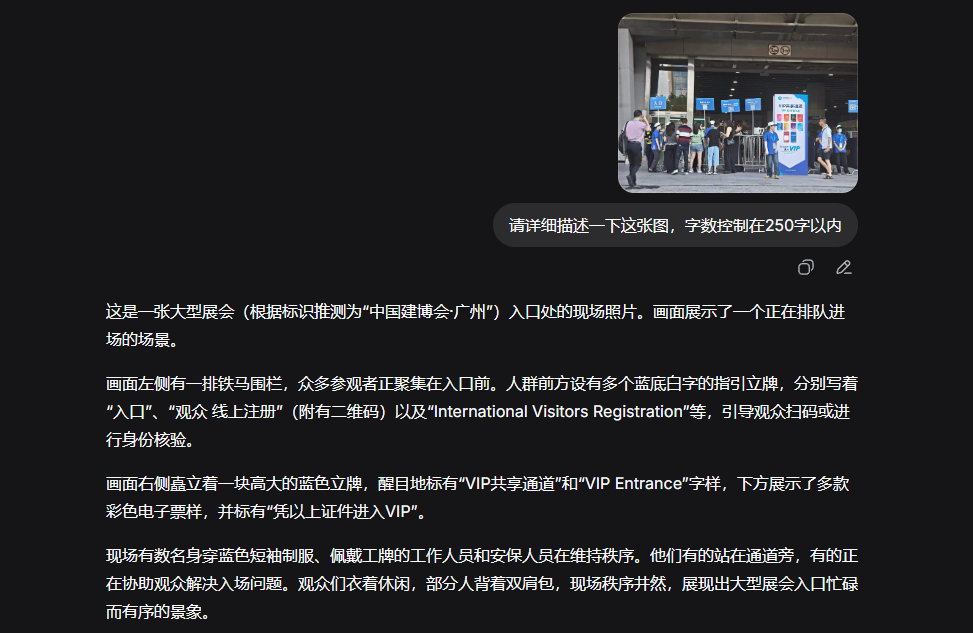
(Image credit: Leitech)
Beyond visual description and text recognition, it confidently identified this as an event scene from the China International Building Decorations Fair in Guangzhou. Its image understanding capabilities proved solid.
Of course, those were straightforward cases. How does it handle more recent information?
For this, I prepared three recent images. Prompt: Identify the objects in the image and explain your reasoning, within 200 words.
(Image credit: Leitech)
For the first image, DeepSeek responded:
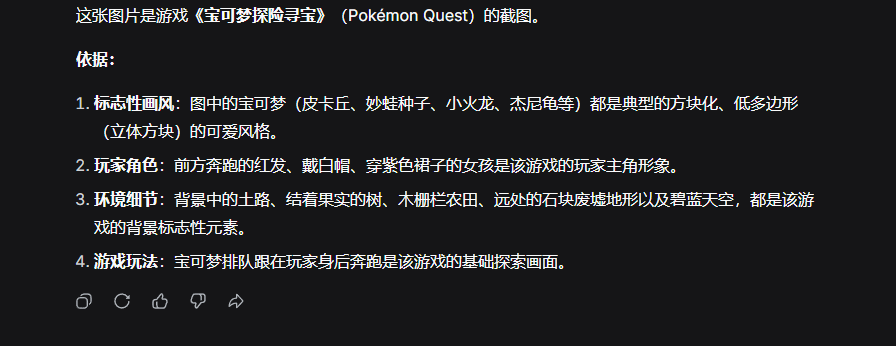
(Image credit: Leitech)
Well... at least it recognized Pokémon information, but the game "Pokopia" was too new to be in DeepSeek's knowledge base.
For the second image, DeepSeek responded:

(Image credit: Leitech)
This time, it accurately identified a Football Manager 2024 tactics diagram sourced from 3dm.
For the third image, DeepSeek responded:
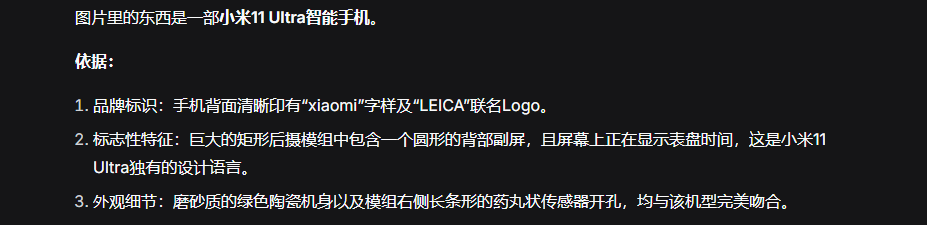
(Image credit: Leitech)
Clearly, it lacked the latest product information but logically deduced the model as Xiaomi 11 Ultra based on the secondary screen. DeepSeek's image recognition demonstrated strong logical reasoning.
Logical Challenges Remain Unsolved
Next, let's test element recognition.
This essentially evaluates the AI's visual perception—some challenges might stump even humans.
Hey, let's see if DeepSeek is colorblind too.
Such images abound online, so I sourced test cases directly from Google.

(Image credit: Leitech)
First test: Prompt: How many tigers are in this image?
Surprisingly, DeepSeek began self-debating, repeatedly denying its previous counts. After twice identifying six tigers, it firmly concluded seven.

(Image credit: Leitech)
The issue? There are actually 10 tigers—quite embarrassing.
Second test: Prompt: Hidden numbers exist in this image. How many are there, and what are they?

(Image credit: Leitech)
This image had previously stumped all AI models, and DeepSeek was no exception.
The same applied to the third image. Such inverse-color, fragmented images remain formidable challenges for visual understanding.

(Image credit: Leitech)
Finally, three visual logic puzzles. Previous tests showed DeepSeek-V4 performed average in logic challenges—let's see how it handles visual logic.
Reportedly, these are sample questions from civil service exams. Let's have DeepSeek solve them.
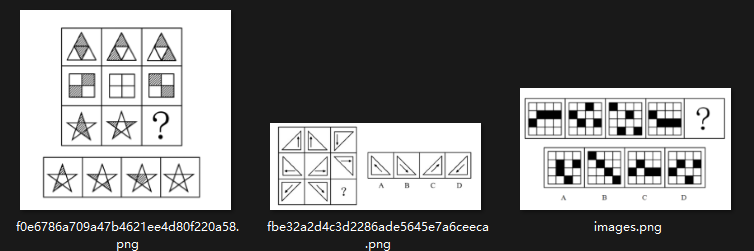
(Image credit: Leitech)
For the first puzzle, it pondered for three full minutes.

(Image credit: Leitech)
The answer was incorrect (correct answer: D). The pattern: when the first two cells are single white/black, the third is white; when double white/black, the third is black.
The second puzzle also proved incorrect.
Unexpectedly, after six minutes of deep thought, it correctly solved the third puzzle!

(Image credit: Leitech)
After two retries, I confirmed it could reason through this, albeit using arithmetic patterns—a breakthrough nonetheless.
Civil service exam preparers, you now have a new tool.
Conclusion: Image Recognition Is Just the Appetizer—Major Multimodal Updates Ahead
After comprehensive testing, I've grasped DeepSeek's current image recognition capabilities.
While its basic recognition accuracy remains high and reasoning follows a clear logic, its knowledge base lacks sufficient information, and it struggles with highly challenging tests.
At least it no longer endlessly debates without conclusion.
In my view, this image recognition serves as transitional appetizer—more akin to a visual understanding module mounted on DeepSeek-V4's framework than true native multimodal capabilities.
However, it proves the DeepSeek team has achieved breakthroughs in visual understanding, clearly paving the way for upcoming native multimodal features. Once this shortcoming (weakness) is addressed, (Note: " shortcoming " left untranslated for cultural context) the landscape of Chinese AI models will undoubtedly transform again.
Those who haven't qualified yet needn't worry—at current performance levels, Doubao and QianWen remain sufficient alternatives.

DeepSeek Visual Understanding Multimodal
Source: Leikeji
Images in this article are from: 123RF Royalty-free Image Library
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







