Yann LeCun's Anti-Consensus Judgement: Large Language Model Path is Wrong, JEPA World Model is the Only Solution to AGI
 05/06 2026
05/06 2026
 538
538
Editor | Key Points Editor
When it comes to opponents of the LLM route, Li Feifei and Yann LeCun are undoubtedly two prominent figures.
Recently, Yann LeCun elaborated in detail on the technology channel Welch Labs his reasons for opposing relying solely on large language models (LLMs) to achieve AGI, and explained the technical details of world models based on the Joint Embedding Predictive Architecture (JEPA).
As one of the main proponents of deep learning, Yann LeCun believes that purely autoregressive large language models and generative AI cannot achieve artificial general intelligence (AGI). The vast majority of human intelligence comes from unsupervised learning about the real world. If AI only generates text through verbatim prediction or images through pixel-by-pixel prediction, it cannot truly grasp the inherent operational rules of the physical world.
Based on this judgement, Yann LeCun attempts to advance a research and development direction different from mainstream generative large models: by constructing a JEPA architecture that makes predictions in an abstract representation space, to compensate for the lack of cognitive and reasoning capabilities in AI.
We have compiled the main information from this interview, and the following are the key points:
1. Large language models pursue reproduction, while world models emphasize prediction
In Yann LeCun's view, AI's ability to perform physical reasoning is on a much higher level.
Generative large models are based on reproduction logic. Essentially, the model is reproducing the statistical patterns in the training data, and its main task is to imitate, as long as the output results are visually or grammatically reasonable.
World models, on the other hand, are based on prediction logic, and the model's main task is reasoning. It must accurately judge the physical outcomes of actions when faced with unknown environments. The ultimate goal of AI is to possess true common sense and become an intelligent agent capable of autonomous planning and action.
2. Large language models have inherent flaws; only world models can lead to AGI
Yann LeCun believes that current generative large language models are constrained by autoregressive mechanisms. The system is merely calculating the next most likely character or pixel, without establishing a cognitive understanding of the internal logic of things on a global level. As the output content increases, errors will continue to accumulate, ultimately leading to output results that severely deviate from objective facts. Simply relying on increasing the number of model parameters cannot solve this structural problem, as the probabilistic statistical process itself cannot be directly transformed into rigorous causal reasoning capabilities.
In contrast, world models establish a predictive mechanism within the system that reflects real-world logic. This enables AI to accurately predict the physical consequences of different action routes at an abstract level before actually performing tasks. This ability to internally deduce and make decisions based on objective laws changes the current situation where machines can only passively respond to static data, endowing AI with the foundational cognition to actively intervene in reality, which is a necessary condition for machines to acquire artificial general intelligence.
3. The JEPA world model technical route abandons pixel-level prediction and shifts to a mathematical representation space
Mainstream generative models attempt to reconstruct every visual detail of images or videos. Due to the unpredictable random interference information in the physical world, such attempts often lead to the model generating blurry images or consuming extremely large computational resources.
Unlike models that focus on visual generation effects, the main feature of the JEPA architecture is the elimination of useless environmental details. Through structures such as Siamese Networks, it compresses input information into highly generalized mathematical representations. This means that the model no longer needs to fully restore the environment but instead directly predicts the movement patterns and development trends of things at an abstract level.
JEPA has currently been used to enhance machine vision and physical reasoning capabilities. Researchers have used models like V-JEPA to enable robots to learn to understand the interactions between objects without relying on massive amounts of manually annotated data.
4. Overcoming the Representation Collapse challenge, world models are on the verge of a technological breakthrough
Why is the development of AI that makes predictions in abstract spaces facing difficulties? The main obstacle is that the model is prone to entering a state of representation collapse. In this state, the model outputs constant, incorrect results to forcibly match the prediction target.
To solve this problem, Yann LeCun's team adopted technical strategies such as Barlow Twins. By maximizing the information differences between different features, the model is forced to learn real and effective environmental information. With the maturation of representation learning technology, the field of JEPA-based world models is on the verge of a technological breakthrough moment that will lead to large-scale expansion.
The following is the transcript of Yann LeCun's interview:
1. Searching for a new architecture to replace LLMs: JEPA
Host: Yann LeCun, a legendary figure in artificial intelligence, has raised one billion US dollars to explore alternative approaches to artificial intelligence. Unlike large language models, Yann LeCun's method is neither language-based nor generative, and by design, it does not output text, images, or videos. Instead, he proposes the JEPA solution.
JEPA is not a single AI model but a new architecture or framework for training AI models. In many successful cases of artificial intelligence and machine learning, models are trained by predicting output Y given input X. For example, large language models receive input text X and are trained to predict the next text Y that appears; image classifiers receive input images X and are trained to predict the corresponding labels Y.
But JEPA does not work this way. In JEPA, input X and output Y are separately input into models called encoders. These encoders return a digital vector or matrix, commonly referred to as an embedding. Subsequently, a third model called a predictor predicts the embedding of Y based on the embedding of X.
Why might this be a better way to build AI systems? Do you think JEPA or world model-based approaches will one day replace LLMs? Or are they actually solving different problems?
Yann LeCun: Initially, they solve different problems, but ultimately, they will indeed replace LLMs. Because although LLMs are very good at processing language, they do little else. In areas where language itself is the foundation of reasoning, they perform very well compared to mainstream generative language AI methods.
Host: JEPA exists on an alternative path of joint embedding architectures. Interestingly, Yann LeCun has played a significant role in the development of both paths.
In the first part of this two-part interview series, we will explore this alternative path to JEPA. We will delve into why Yann LeCun chose to abandon generative architectures when they were just emerging in the field of language and explore the inspiration he gained in solving the problem of representation collapse that has plagued joint embedding architectures for years. Finally, we will take an in-depth look at the JEPA architecture itself. In the second part, we will delve into how JEPA is implemented and see how these models actually perform compared to the methods driving LLMs.
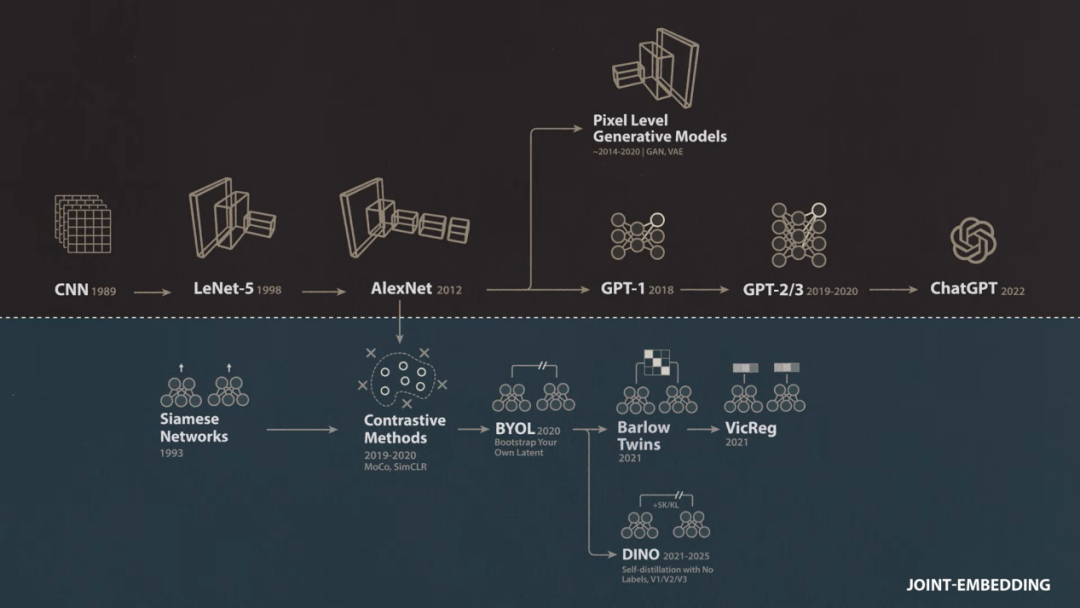
Yann LeCun foresaw this transformation back in the 1980s. At that time, most people in the AI field were busy building expert systems that were explicitly programmed rather than learning from data, and he pioneered convolutional neural networks. Twenty-five years later, when deep learning began to rise and dominate AI, the breakthrough deep learning model AlexNet was found to be strikingly similar to the convolutional networks proposed by Yann LeCun in the 1990s.
However, as deep learning continued to advance rapidly in the 2010s, Yann LeCun and other researchers became increasingly concerned because this AI approach relied too heavily on labeled training data. AlexNet was trained through supervised learning on the massive and carefully annotated ImageNet dataset, and it was trained to match the labels assigned to each image by human annotators. In contrast, children can learn highly generalizable representations of concepts like 'dog' with very few explicitly labeled examples.
As manual labeling of data became a bottleneck for supervised learning, interest in alternative methods grew. Reinforcement learning, which allows models to learn by interacting with the environment rather than from labeled data, underwent several revivals in the mid-2010s, highlighted by Google DeepMind's breakthrough performances in Atari games and the highly complex game of Go. Meanwhile, Yann LeCun and others explored unsupervised methods of learning from unlabeled data, including a variant known as self-supervised learning, where labels are directly derived from the data itself.
Yann LeCun: Around 2015, I started showing a slide in the machine learning community that later became a meme. I said on it that if intelligence is like a cake, then self-supervised learning is the main body of the cake, supervised learning is the icing on the cake, and reinforcement learning is just the cherry on top. At that time, people were almost crazy about reinforcement learning, so I was trying to tell them that this method was too inefficient and would never take us to a level close to human or animal intelligence. As it turned out, the success of self-supervised learning happened much faster in the text and language domains than in more natural modalities like vision.

2. The dilemma of generative models in the visual domain
Host: Yann LeCun is referring here to the success achieved by training large language models (LLMs) by predicting the next token. OpenAI was founded in 2015 and initially focused on reinforcement learning, creating OpenAI Gym and Universe and demonstrating impressive performance in complex video games.
While the company was mainly focused on reinforcement learning, people like Ilya Sutskever and Alec Radford began to take an interest in a new neural network architecture called Transformer from Google. It was originally designed for language translation, but during experimentation, Radford tried an interesting modification. Instead of having the Transformer convert one language into another, he turned to a simpler self-supervised method: the training text was broken down into sequences, the Transformer received everything except the last token, and was trained to predict what the last token was.
Radford and his OpenAI colleagues trained their Transformer on a massive internal dataset containing 7,000 books. This stage is now known as pre-training, and subsequently, they further trained the model on specific language tasks using standard supervised learning.
This two-stage training method was highly effective, setting new state-of-the-art (SOTA) results on nine language benchmarks, including high school-level reading comprehension, outperforming architectures specifically designed for each individual task. Radford's model, now known as GPT-1, although not attracting much public attention at the time, was a huge breakthrough that freed models from reliance on manually annotated data and enabled unprecedented levels of scalability.
Other researchers at OpenAI quickly grasped the importance of this research, and the team fully committed to this approach, aggressively scaling up to GPT-2 in 2019, launching GPT-3 in 2020, and releasing ChatGPT in 2022. In 2012, AlexNet was trained on about one million samples, while by 2020, GPT-3's training sample size had reached hundreds of billions.
Interestingly, this newly emerged training paradigm fully aligned with Yann LeCun's predictions from a few years earlier: a broad self-supervised pre-training phase, followed by supervised learning, and finally reinforcement learning, shaping the raw next-token prediction model into a practical AI assistant. However, although these self-supervised generative methods achieved clear breakthroughs in the language domain, the situation was much more ambiguous when it came to image and video data.
Yann LeCun: I have been researching the visual domain. The initial idea was to use a generative architecture to train a system to predict what would happen in a video, essentially training the subsequent development of the video at the pixel level.
Host: In the years leading up to the success of GPT-1, researchers including Yann LeCun had attempted to apply the same self-supervised generative methods to video. In the most direct implementation, the neural network received RGB pixel values from a series of video frames and then predicted the pixel values of the next frame, just as GPT models predicted the next token in language.
However, when we used these models to predict the next frame, the results were blurry, and this blurriness intensified dramatically in longer-term predictions. Large language models are autoregressive; when ChatGPT answers a question, it generates one token at a time and feeds the newly generated token back into the input at each step to produce the next output. If we try to apply this autoregressive method to a next-frame video prediction model, the results will quickly degenerate into a blurry void.
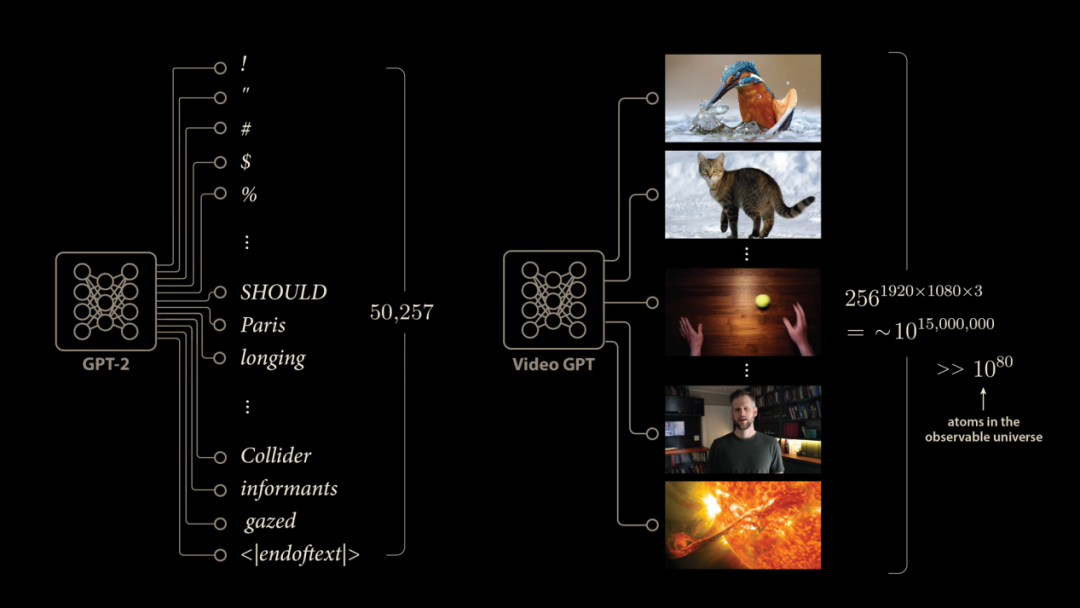
The blurry frames produced by generative video prediction methods are not much of a mystery. Although language is complex and unpredictable, it pales in comparison to video. Language models use a fixed-size vocabulary, such as GPT-2, which has 50,257 discrete outputs corresponding to the next possible generated token. This fully enumerated method does not work in the video domain.
For full HD video, in the most general case, each pixel can take 256 discrete values, and we have 1920×1080×3 colored pixels. This means that the next frame of video may have approximately 10^15 million possible outcomes, which makes the number of atoms in the observable universe pale in comparison. Therefore, it is impossible for video prediction models to provide discrete outputs for every possible next frame, as language models do. Instead, many generative video methods of that era had the network directly output pixel intensity values, and the enormous challenge faced by this approach was how the model could learn to handle uncertainty.
If we compare an LLM learning to complete the sentence 'The ball bounced towards xx place' with a neural network predicting the next frame of a video of a bouncing sphere, the problem becomes clear. In the LLM training case, the model would see various examples in the training set, and since the model has independent outputs for each token, it can basically update these probabilities independently.
But our video model does not have it so easy. If the dataset contains videos of a ball starting to move along the same path and then bouncing in various directions, the best the model can do to handle this ambiguity is to predict the average of these outcomes, since it is forced to directly predict a single output frame for a given input. When we average the pixel values of the video, what we end up with is a blurry, faded, chaotic scene.
Although this is just the most naive approach, and people have tried many image prediction strategies over the past few decades with varying degrees of success, these naturally occurring challenges prompted researchers like Yann LeCun to pose an interesting question: Do our models really have to be generative? During the critical pre-training phase of the GPT example, whether the model possesses generative capabilities is actually unimportant.
After pre-training for 'predicting the next token,' we obtain an inherently excellent auto-completion model. What truly matters are the internal representations and features the model learns to address the prediction task. It is these internal representations that enable the pre-trained model to be rapidly adapted into a powerful AI assistant. Next-token prediction in language serves as a proxy indicator of intelligence, and this approach has proven remarkably effective. But are there other signals and methods that can be used to learn the robust internal representations (Representations) required for building intelligent systems?
3. Introduction of Joint Embedding Architectures
Yann LeCun: Meanwhile, around 2017-2018, we began to realize that the best systems for learning image representations were non-generative. They do not perform reconstruction.
You input an image, pass it through an encoder, and then attempt to guide this encoder to extract as much information as possible under certain constraints. For example, you take two images of the same scene or capture an image and then damage or transform it in some way. You run both through the encoder and tell the system that whatever is extracted, the representations of these two images should be identical because they semantically represent the same thing. I
have been researching this idea of joint embeddings (Joint Embedding) since the 1990s. It's not a new concept; we previously called it Siamese Neural Networks (Siamese Neural Net).
Moderator: The Siamese networks mentioned by Yann LeCun were developed by him and his collaborators in the early 1990s at Bell Labs, initially to create systems for detecting fraudulent signatures.
The system works by inputting a pair of signature images into two identical copies of a neural network. These network copies are not trained to generate any data; instead, they output numerical vectors known as embedding vectors (Embedding Vectors).
The network copies are trained on two types of samples: positive samples contain a reference signature and a non-fraudulent signature, both from the same person; negative samples contain a reference signature and a fraudulent signature. For fraudulent samples, the networks are trained to produce embedding vectors with the greatest difference; for positive samples, they generate embedding vectors with maximized similarity. When a new signature appears, we can pass it through the network to compute an embedding vector and compare it with the vector generated by the reference signature. If the similarity is insufficient, the signature will be detected as a forgery.
By jointly embedding signatures, Siamese networks learn highly useful internal representations of signature images. Notably, this process does not require learning to predict or generate any actual signature images. Just like the GPT-based approach, joint embeddings offer a potentially viable solution to the video blurring problem.
Yann LeCun: You take an image, input it into an encoder, and then attempt to guide this encoder to extract as much information as possible with specific attributes. For example, you take two images of the same scene or obtain an image and then damage or transform it. You run both through the encoder and tell the system that whatever is extracted, the representations of these two images should be identical because they semantically represent the same thing.

4. Overcoming Representation Collapse in Joint Embeddings
Moderator: So the idea here is that we avoid the video blurring problem seen in generative models. By using a joint embedding architecture, we map damaged or transformed copies of images or videos to similar embedding vectors. Ideally, this trained model will learn useful internal representations of images or videos that we can repurpose for other tasks, just as GPT models learn internal representations during pre-training and are eventually fine-tuned to behave as AI assistants.
However, this joint embedding (Joint Embedding) strategy has a significant problem. Since we train the network to make the original image or video as similar as possible to the damaged version, the network may find a trivial solution where it simply returns the same embedding vector regardless of the input. If the network learns to output a vector of all ones for any input, it will return all ones for both damaged and undamaged views of the same image, thereby maximizing the produced similarity but actually learning nothing useful. This problem is known as representation collapse (Representation Collapse).
In Yann LeCun's original Siamese Network (Siamese Network) approach, the team used what is now known as contrastive learning (Contrastive Learning) to avoid representation collapse and provided the network with positive and negative samples during training. This contrastive method has proven equally applicable to images and videos. We can train the network to output similar embeddings for different views of the same underlying image or video while outputting different embeddings for different images or videos.
Although these contrastive methods have achieved success in the image and video domains, they face difficulties when scaled up, often requiring massive computational resources and large libraries of negative samples to learn meaningful representations. Yann LeCun argues that in the worst case, the number of contrastive samples may grow exponentially with the increase in representation dimensionality.
By the late 2010s, Yann LeCun and others had clearly recognized that using generative models to fully reconstruct images and videos was not an effective path for self-supervised learning. However, there was no direct solution in the industry at the time to address the representation collapse problem, which also hindered joint embedding architectures from learning internal representations as powerful and general as those of large language models.
Yann LeCun: It was clear that reconstruction was not a good idea for signals like images and videos. Then I had an epiphany because the method we were using to train joint embedding architectures at the time was somewhat of a hack. Until I did some research with several postdoctoral colleagues at Meta, particularly Adrien Bardes, who proposed a technique called Barlow Twins. This technique is based on an old idea from the fields of computational neuroscience and machine learning. Geoffrey Hinton had also explored similar ideas, namely that the system needs some measure of information content and attempts to maximize it. The renowned theoretical neuroscientist Horace Barlow had done some pioneering foundational research in this area.
Moderator: Here, Yann LeCun is referencing the work of Horace Barlow. In 1961, Barlow hypothesized that neurons in the visual systems of animals and humans operate by reducing redundant information among themselves. In 2020, Yann LeCun's postdoctoral researcher Stephane Deny, based on his knowledge of Barlow's research, proposed applying Barlow's ideas to the output end of networks as a way to avoid representation collapse.
In the joint embedding architectures we are discussing, embedding vectors are generated by artificial neurons in the final layer of the network. If the embedding vector has a length of 128, then the output layer of each network contains 128 neurons. If you pass a diverse batch of images and observe the traversal process, the first neuron might activate strongly on photos of dogs but not on photos of cats.
In the joint embedding approach, the network receives distorted views of the same batch of images, with the core goal of making the embedding representations generated from the same underlying image similar. Therefore, we want the output of the first neuron in the second network to be highly consistent with the output of the first neuron in the first network. A standard architecture would simply measure and maximize the similarity between these two vectors, but this extremely easy (note: ' extremely easy ' should likely be 'easily' in proper English, but I've kept it as is to match the original text's structure) leads to the network simply outputting the same value for all inputs, i.e., representation collapse.
After introducing Barlow's hypothesis, the team chose to reduce redundancy between the outputs of different neurons by calculating the cross-correlation (Cross-Correlation) between the output vectors of the two networks. The calculation process involves scaling each vector and taking their dot product, ultimately yielding the Pearson correlation coefficient (Pearson Correlation Coefficient). To reduce redundancy, we want this correlation to approach zero.
By arranging the neuron outputs of the two encoders vertically and horizontally, respectively, we calculate the correlation between all neuron pairs and construct a matrix. Since the core idea of the joint embedding architecture is to produce similar outputs for different distorted versions of the same image, we want corresponding neurons in the two encoders to be highly correlated while hoping that the correlations between elements corresponding to different neurons on the non-diagonal are zero. Ideally, this cross-correlation matrix should resemble an identity matrix (Identity Matrix).
Yann LeCun and his collaborators thus designed a new loss function to measure the deviation between the cross-correlation matrix and the identity matrix. This new method, known as Barlow Twins, produced remarkable results. It successfully learned robust internal representations of the training images while perfectly avoiding the trap of representation collapse. The team employed various methods to verify the quality of these internal representations.
Just as early self-supervised pre-training allowed GPT-1 to surpass purely supervised models, the most important benchmark test for visual tasks at the time was classification accuracy on the ImageNet dataset. The original AlexNet in 2012 achieved 59.3% accuracy on the validation set. To intuitively compare self-supervised Barlow Twins with fully supervised models, the team used a linear probing (Linear Probe) method, where they added a layer of neurons to the output of a frozen Barlow Twins encoder and performed classification training using supervised learning. The results were striking: the model achieved 73.2% accuracy on ImageNet, a full 10 percentage points higher than the fully supervised AlexNet.
However, between 2012 and 2021, fully supervised methods themselves made significant progress. For example, Google's team applied the Transformer architecture to image classification in 2020, setting a new record of 88.6%. Therefore, by 2021, although self-supervised learning had made rapid strides in visual tasks, its overall performance still slightly lagged behind the top fully supervised methods. The generative pre-training paradigm that had driven rapid progress in large language models in the language domain remained difficult to implement for images and videos.
Yann LeCun: It turns out we chose the right path. After that, we released a simplified version of Barlow Twins called VICReg, which performed equally well. Meanwhile, our colleagues in Paris were also exploring similar routes, which eventually evolved into the DINO series. This is also a JEPA technique, and the facts are very clear: joint embeddings have significant advantages for self-supervised learning of image representations.
Moderator: The DINOv3 paper released in August 2025 marks a significant turning point in the visual domain. It utilizes a joint embedding architecture to achieve an extremely high image accuracy of 88.4%, closely approaching the current industry's state-of-the-art level.
As the authors state in the paper, this is the first time self-supervised learning has achieved results comparable to supervised models in image classification tasks. DINOv3's ability to learn representational knowledge without any human-labeled intervention is astonishing. It outputs an embedding vector for each image patch (Patch) it analyzes. If you extract an embedding vector from the hand region of a test image and compare its similarity with other parts of the image, DINO can precisely and perfectly segment the hand from a complex background. This ability applies equally to any object, such as a ball, cat, or book.
After the string of successes with Barlow Twins, VICReg, and DINOv1, Yann LeCun condensed these ideas into a monumental 60-page position paper in 2022 titled 'A Path Towards Autonomous Machine Intelligence.' Unlike his previous papers, which focused on specific technical details of machine learning, this article adopts a first-principles-based global perspective to deeply explore how we should truly build intelligent machines. The paper first sharply points out that current AI methods are still far from human learning capabilities. For example, a teenager can become proficient at driving with only about 20 hours of practice.
Yann LeCun: This is basically the direction Tesla is striving toward. However, they are still far from truly achieving Level 3 to Level 5 autonomous driving. Yet a 17-year-old can learn to drive with just a few hours of practice. How is this achieved? Shouldn't we figure out the hidden intelligence behind this? My core hypothesis is that this secret lies in world models (World Models).
5. World Models: Toward Autonomous Machine Intelligence
Moderator: Yann LeCun's heavily invested assertion is that the most critical missing piece in modern AI is precisely world models—models capable of making accurate predictions about how the physical world operates. As he explained in his 2022 paper, common sense can essentially be viewed as a collection of world models that tell intelligent agents what is possible, what is reasonable, and what is absolutely impossible. With these world models, animals can acquire new skills with minimal trial and error. They can predict the consequences of their actions, enabling them to reason, plan, explore, and conceive entirely new solutions to complex problems. Yann LeCun further argues that joint embedding architectures provide the most solid foundational basis for constructing such world models.
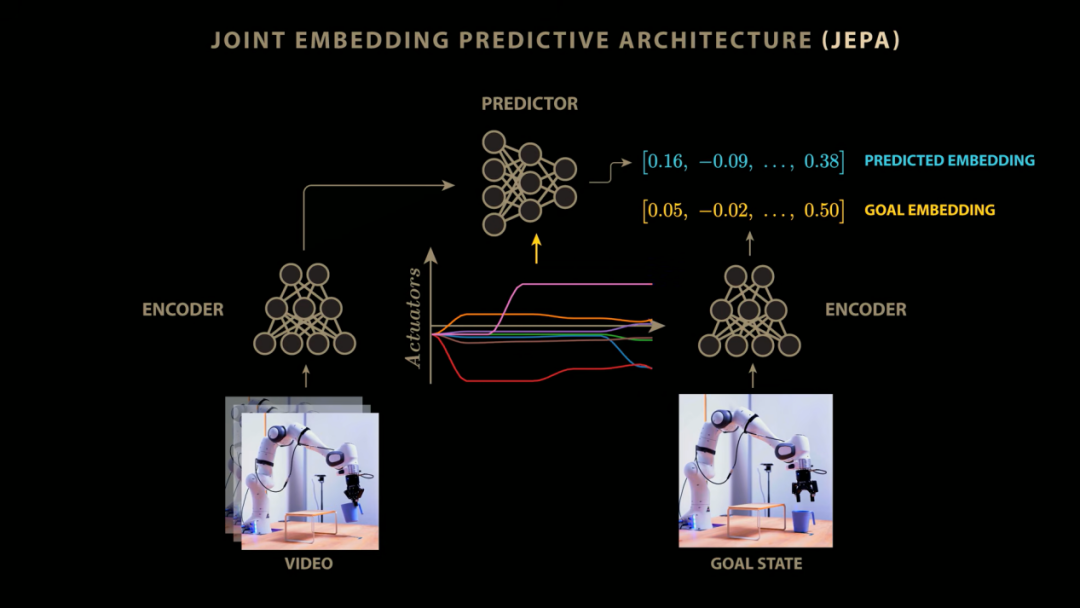
Yann LeCun: JEPA stands for Joint Embedding Predictive Architecture (Joint Embedding Predictive Architecture). Its operational mechanism involves first obtaining the current observed state of the world, then obtaining the next observed state, and processing them sequentially through an encoder. Subsequently, a predictor attempts to predict the state at time t+1 based on the state at time t. You can also intervene and regulate the prediction process by inputting specific action commands, giving you a complete world model.
Host: Let's take a concrete example. Instead of using a traditional generative architecture to predict the vast array of pixel values in the next frame of a video one by one, we can map the current and next frames of the video into a compact embedding space. Then, we train a predictor model to directly predict the embedding of the next frame given the current video embedding. Under this implementation mechanism, the JEPA architecture successfully frees the model from the burdensome and inefficient task of predicting a massive number of pixels, allowing the predictor to focus entirely on analyzing the core, salient features in the scene that have been filtered by the encoder. Yann LeCun presents an excellent thought experiment here.
Yann LeCun: If you train a model to predict what will happen next in dashcam footage, a traditional generative model would waste its precious computational resources on predicting the random swaying of leaves on the roadside—content that is inherently unpredictable yet occupies a significant number of moving pixels in the frame.
Host: As Yann LeCun mentioned earlier, we can further broaden the application boundaries of JEPA by introducing action conditioning. In the research on V-JEPA2, the team input the specific action signals received by a robotic arm as constraints into the JEPA model. When observing a continuous sequence of images of the robotic arm and its environment, JEPA not only predicts the embedding representation of the next frame through training but also processes the control signals sent to the robotic arm simultaneously. This enables the predictor to deeply learn and accurately predict how various control commands will actually alter the spatial position of the robotic arm in future embedded images.
This fully learned world model can then be directly used for complex planning and precise control of robots. Given an image representing a target state (e.g., moving a cup off a platform), the image is passed through a next-frame encoder to generate the embedding of the target state. Based on this, the system can use a control algorithm to rehearse and explore in the world model, testing various hypothetical action interventions and ultimately reverse-engineering an optimal sequence of actions that guides the model's predicted state to perfectly match the target state. As Yann LeCun has evaluated, this is indeed a fresh remaking of a classic old idea using cutting-edge architecture.
Yann LeCun: You build a powerful model that can accurately provide the world state at the next time step based on the current world state and the control actions you envision taking. Once you have this model, you can predict the final outcome of any arbitrary sequence of actions in a virtual space and calculate an optimal operational path through mathematical optimization to achieve a specific goal. This is very classic Optimal Control theory, with its historical origins traceable to the Soviet Union in the late 1950s and Western academia in the early 1960s.
Host: This is indeed an extremely classic core concept in control theory.
Yann LeCun: Yes. But the less classic part of this architecture is that you need to train this model from scratch using the most cutting-edge machine learning techniques. Even more disruptively, you have to let the network learn a highly abstract representation of the input state on its own and complete the model's learning loop within this abstract state space. This is precisely the essence of JEPA.
Let me put forward a controversial viewpoint that might offend many of my Silicon Valley colleagues. I simply cannot understand how you could even conceive of building an advanced agent system without endowing it with the fundamental ability to predict the consequences of its own actions. Variational autoencoders (VAEs) cannot do this, and neither can the currently popular large language models, which lack a world model. They simply cannot predict the consequences of their outputs before acting; they blindly generate tokens and take actions, then, as a certain French king once said, 'After me, the deluge.'
If you truly want to build safe and reliable agent systems, they absolutely must possess the ability to predict the consequences of their actions. Only then can they reasonably plan sequences of actions to complete complex tasks while strictly ensuring that safety boundaries are not breached. In such systems, reasoning has evolved into a rigorous search and deduction process rather than simple autoregressive prediction. This is the entire core concept and ultimate value of world models.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







