DeepSeek V4: Praised but Underutilized - Models Are Merely Tickets, Codex Represents the Ultimate Challenge
 05/07 2026
05/07 2026
 582
582
Models must vie for supremacy, but the competition among Agent frameworks is even more intense.
The atmosphere within the AI community last year, when DeepSeek V3 was unveiled, starkly contrasts with this year's scene.
Back then, discussions were fervent, reminiscent of the global ChatGPT craze. Social media buzzed with real-world tests, benchmarks, and cost analyses. For the first time, many overseas developers took a Chinese large-scale model company seriously. Both domestic and Silicon Valley firms realized that, beyond OpenAI, Anthropic, and Google, other teams could achieve similar model performance.
More crucially, it was also more cost-effective. DeepSeek's impact transcended technology; lower training costs, aggressive engineering optimizations, and superior inference cost-effectiveness prompted the entire industry to rethink the competitive dynamics of large models. Many hailed it as the true 'Open AI'.
Two weeks ago, when DeepSeek V4 was launched, the industry showed keen interest. Many developers immediately conducted tests and comparisons, but the overall market sentiment was notably more subdued. Over the past two weeks, ordinary users who relied on Doubao or ChatGPT continued to do so, while among developers, many who used Codex or Claude Code did not switch to GPT-5.5 or Claude 4.6/4.7 simply because DeepSeek V4 was cheaper.
Image Source: YouTube
When developers discuss AI today, they rarely mention model names like GPT-5.5, Claude 4.6, or DeepSeek V4. Instead, they focus more on Agent frameworks such as Codex, Claude Code, OpenClaw, OpenCode, and Hermes.
Indeed, over the past year, the AI industry's competitive focus has gradually shifted from model capabilities to AI's actual output value. On this front, DeepSeek V4 still lacks its own Codex.
DeepSeek V4 is impressive, but models are receiving less attention
'I tried the same operation on opencode, and the speed in deepseek v4 pro high mode was surprisingly slow. The same task took only 20 minutes in codex 5.5 med mode but 2 hours in v4 pro,' X user Ayush Jaipuriar recently commented.
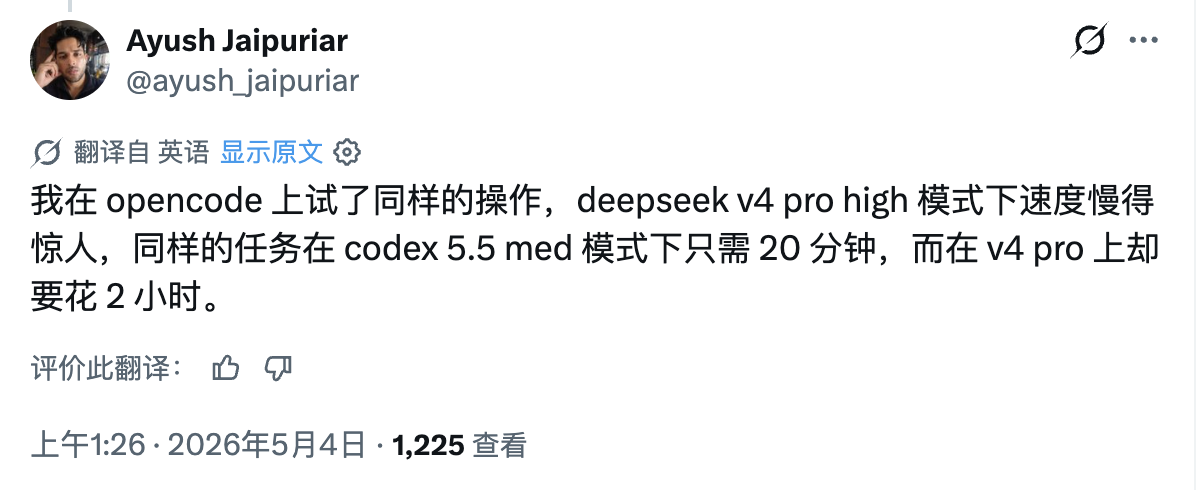
Image Source: X
It should be noted that DeepSeek V4 is undoubtedly a powerful model. Compared to last year's V3, V4 has demonstrated significant improvements in code capabilities, reasoning abilities, long-context understanding, and multi-turn comprehension, particularly in Chinese scenarios, complex logical reasoning, and long-context tasks. Meanwhile, amidst price hikes across various large models domestically and internationally, V4 is one of the few that has reduced its prices.
However, the issue is that, in 2026, benchmark test results are increasingly unable to reflect AI's performance in real-world work. Last year, whenever a new model was released, social media discussions immediately centered on surpassing MMLU scores, setting new records on SWE-Bench, or improving human evaluation scores.
This is not to say that benchmark tests are entirely worthless, but developers clearly care less about them now. The reason is simple: everyone has seen too many models that perform well in tests but are impractical in real use. Many benchmarks are akin to exams, but real-world work environments are far more complex than exams, and actual performance often outweighs price advantages.
Semiconductor and AI analysis firm SemiAnalysis recently conducted a horizontal test covering GPT-5.5, Opus 4.7, and DeepSeek V4, pointing out that DeepSeek V4 is currently the lowest-cost alternative to top-tier closed-source models, but its capabilities have not yet reached a leading level.
Moreover, the way Token costs are calculated is unreasonable; a more reasonable approach is to consider the cost of completing a task. Developer and former media person Wang Boyuan mentioned on X that a problem that could not be solved after much effort using a second-tier domestic model was resolved in one try with Codex. Developer Chi Jianqiang, founder of Mowen Xidong, also encountered situations where Claude Code failed twice, but Codex succeeded in one attempt.
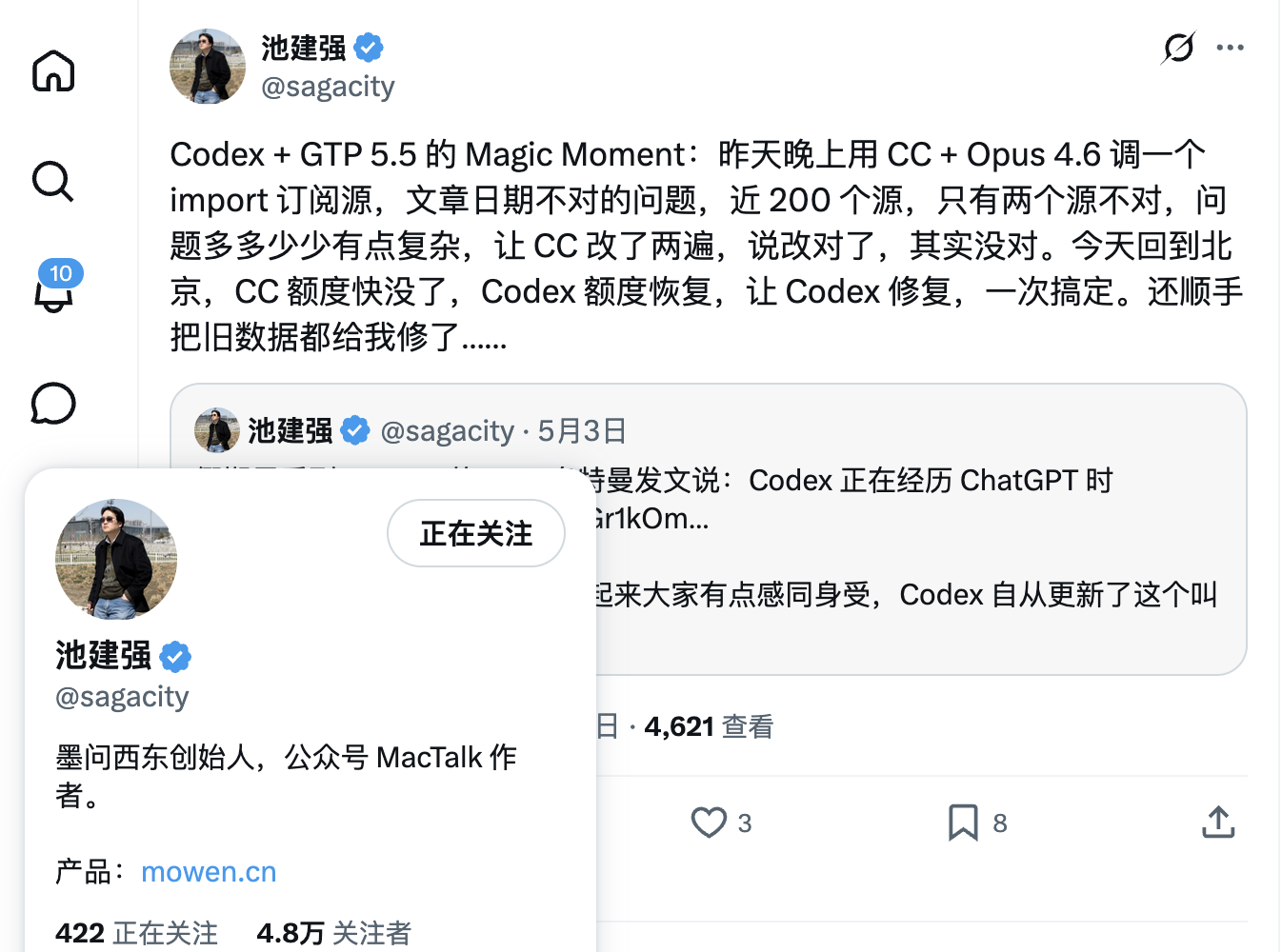
Image Source: X
It is evident that actual model costs cannot be simply compared based on 'official Token pricing.' Not to mention the results, the actual Token usage varies. Moreover, a key upgrade of GPT-5.5 this time is 'efficiency,' allowing it to complete the same task with fewer Tokens.
Therefore, even though there are ways to use third-party models like DeepSeek V4 on Claude Code or Codex, considering factors such as stability, effectiveness, and time, most people still stick to the official default models: Claude Code uses Claude 4.x, and Codex uses GPT-5.x.
Especially in coding scenarios, what developers face daily is whether AI can participate in the entire software engineering process. For example, can it understand the entire project structure, continuously modify dozens of files, call the terminal by itself, automatically fix bugs, continue trying after errors, and maintain context stability over a long time?
These challenges test not just 'model capabilities' but also require a complete AI work system. Developer Vladimir, after using 14.43 million Tokens of DeepSeek V4, stated that V4's intelligence level is close to GPT-5.2/GPT-5.3, but the biggest issue is that it often ignores agents files, and in practical use, tools and the Harness framework must be enforced.
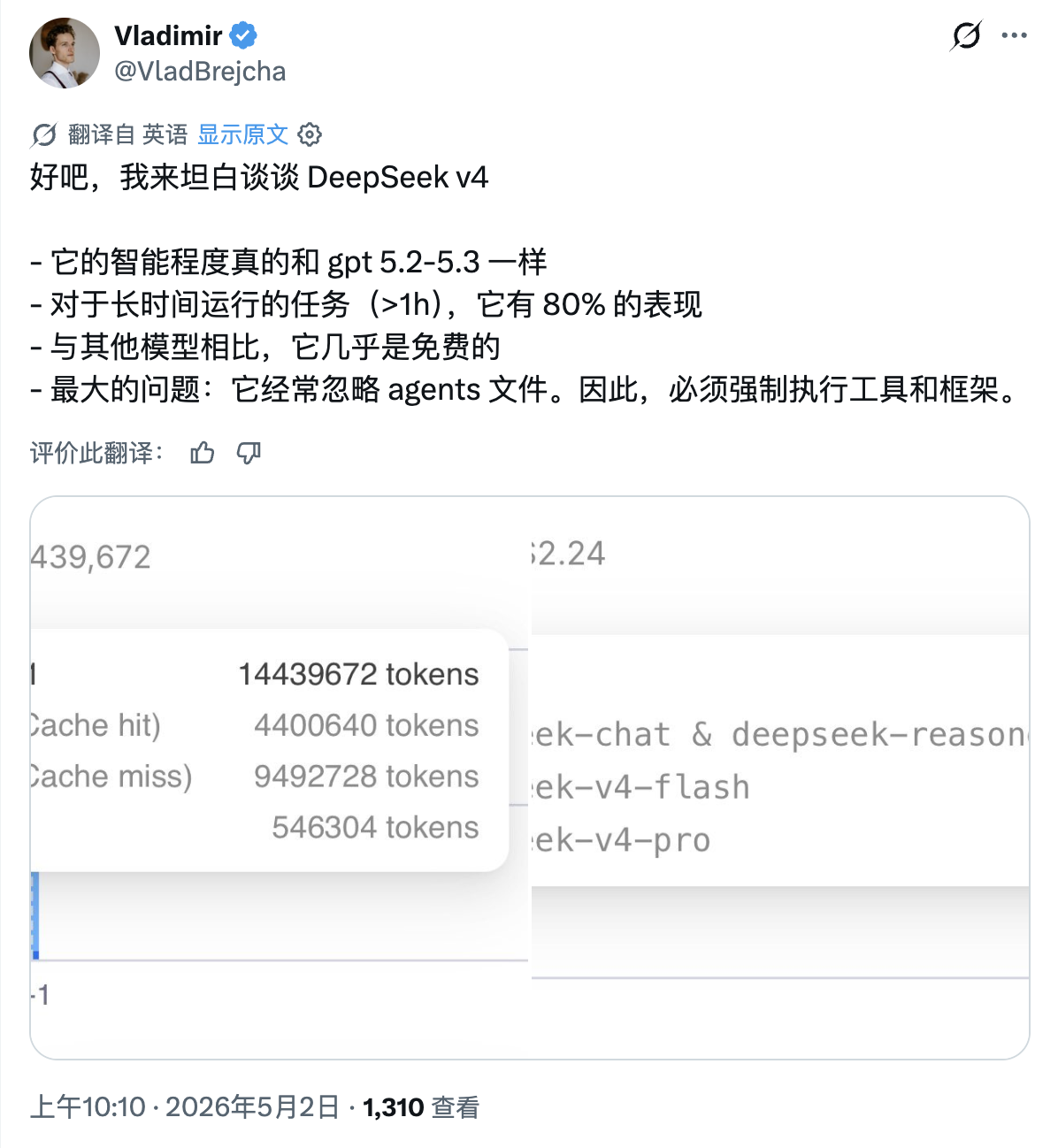
Image Source: X
Claude Code and Codex are truly complete products, but DeepSeek V4 is just a model. SemiAnalysis emphasized in its test report: 'A truly complete product is a runtime framework + model. Missing either one leaves you lacking.'
Over the past year, Agent frameworks like OpenClaw (Longxia), Claude Code, and Codex have gained increasing prominence. Many developers now say, 'I'm using Claude Code' instead of 'I'm using Claude 4.6.' Similarly, many discuss Codex rather than GPT-5.5.
DeepSeek Still Needs Its Own Codex
Looking back, when ChatGPT first gained popularity, the entire industry was essentially building products around 'conversation.' Whether it was OpenAI, Anthropic, or domestic companies, the focus was on making models more human-like in chat, emphasizing smarter, more natural, and more lifelike interactions.
But now, the focus of AI is shifting from 'chatting' to 'working.' This change may seem like just a shift in usage, but it has also altered the competitive logic of the entire industry. Previously, the most important task for model companies was to train smarter models; now, an increasingly important question is how to make AI truly complete tasks.
This is why terms like Agent, Workflow, Context Engineering, and Harness Engineering have emerged frequently in the industry over the past year. Essentially, they all address the same issue: how to make AI truly enter the production process.
Therefore, when many developers evaluate AI Coding or Agent products now, while the model as the system's 'engine' is important, the key factor directly determining AI's actual value lies in a systematic engineering approach. For example, context management, tool invocation, long-term memory, task decomposition, error recovery, and multi-Agent collaboration. In practical work, these capabilities are often even more important than the model's inherent advantages.
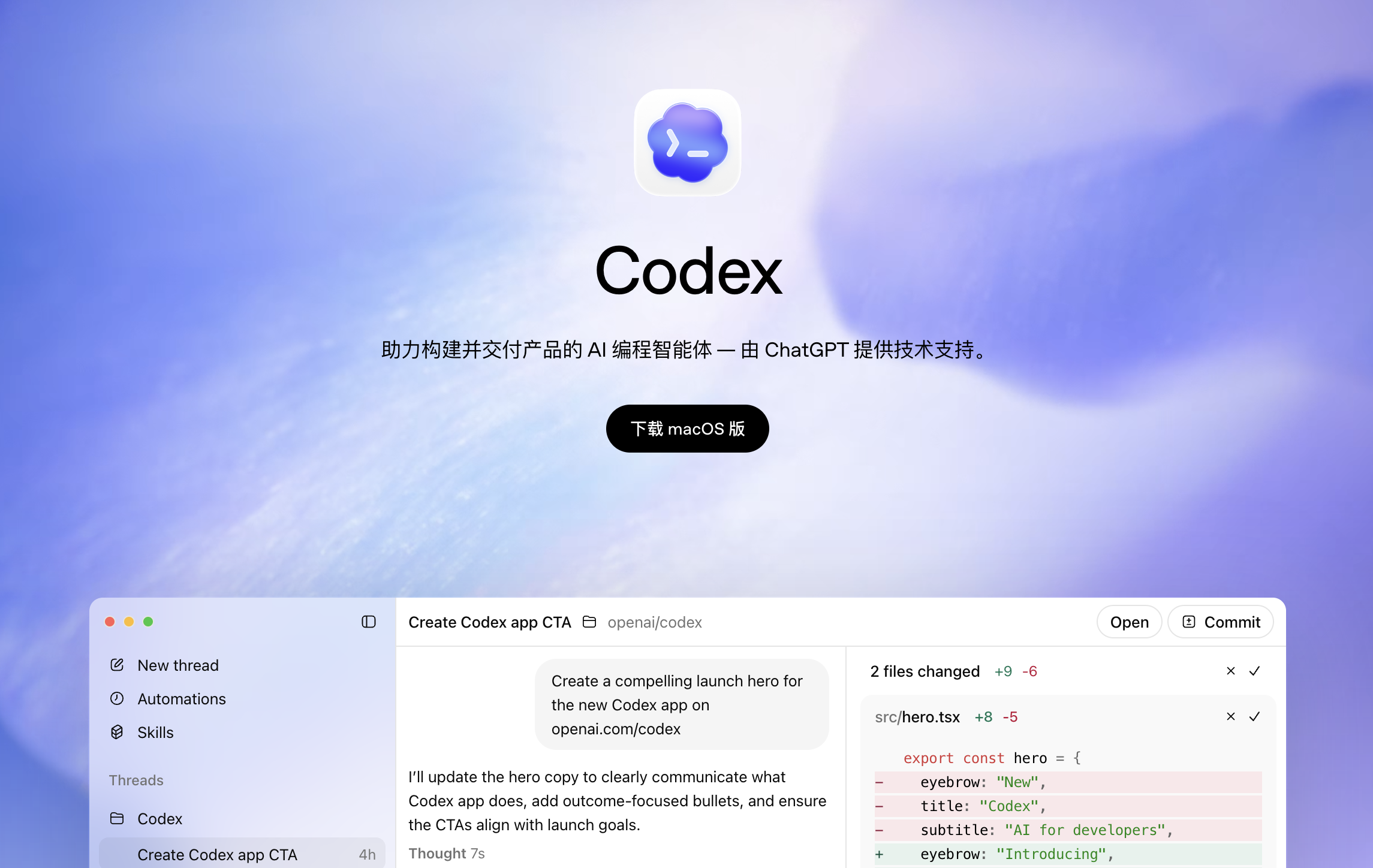
Image Source: X
This is why more and more people are saying that the competition in AI Coding is no longer just about LLMs but about AgentOS.
Conversely, this also explains the success of Claude Code and Codex to some extent. On one hand, their own models lead in capabilities; on the other hand, vertical integration from the underlying model to the Agent framework brings more stable and efficient performance in real work environments. Especially in long-task scenarios, Claude Code functions more like an AI assistant capable of continuous autonomous work.
The true significance of GPT-5.5 lies not just in its stronger model but also in the increasing maturity of the Codex workflow behind it. Capabilities such as file management, tool invocation, Agent collaboration, task decomposition, and context management have collectively brought about a qualitative change in the actual capabilities and value demonstrated by AI.
OpenAI recently announced that the API revenue growth rate for GPT-5.5 in its first week exceeded twice that of any previous version, while Codex's revenue doubled in less than seven days. Moreover, this advantage has now spilled over from AI Coding to more Agent scenarios.
Those following Anthropic and OpenAI should have noticed that both companies have been expanding Claude Code and Codex to more scenarios recently, including connecting with more third-party applications and platforms.
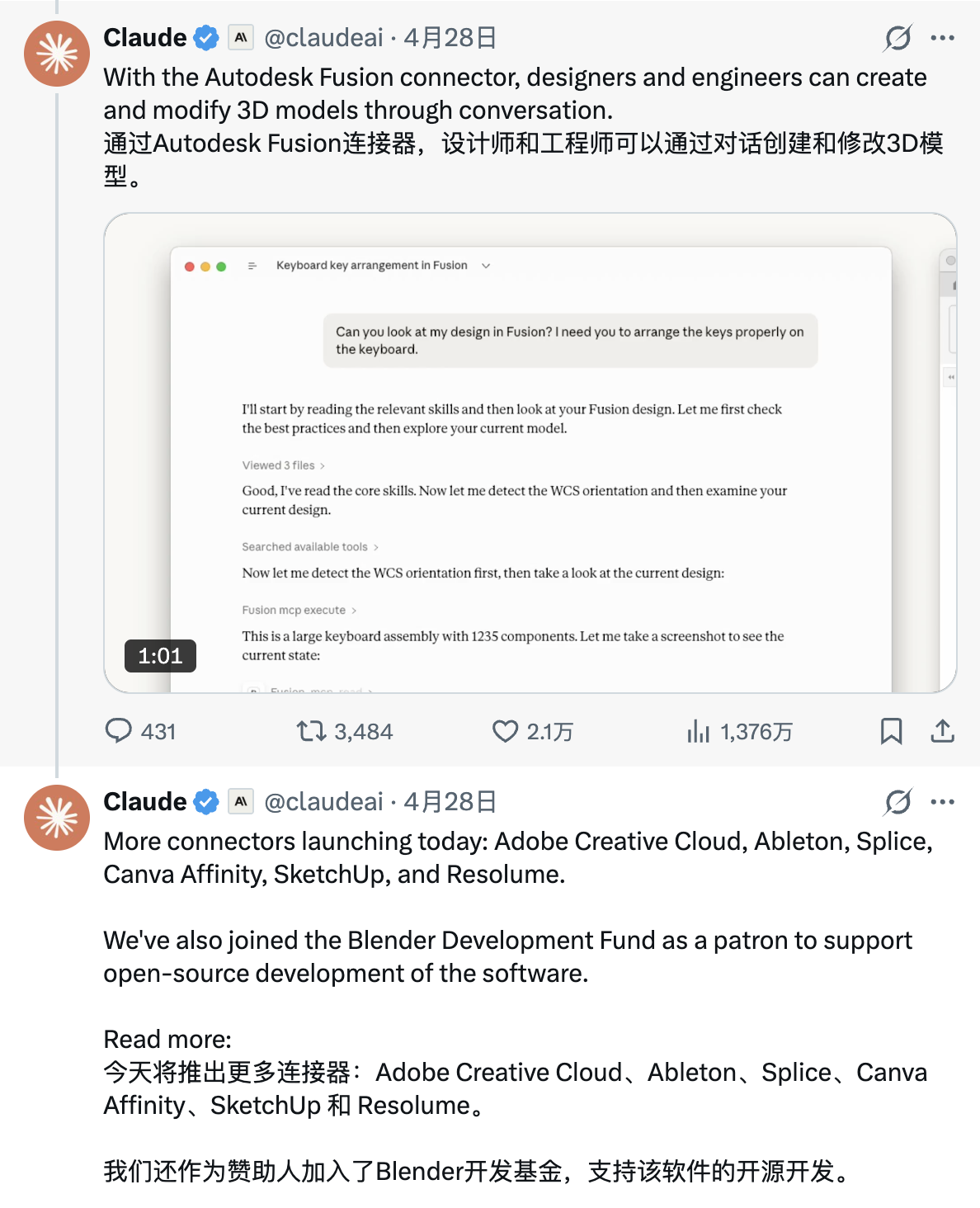
Image Source: X
Not only that, Claude Code has taken on more of Claude Cowork's office positioning, recently launching AI Agents tailored specifically for banks and other financial services enterprises. Codex is also emphasizing more work in research, documentation, accounting, etc., rather than being limited to Coding.
Looking back at DeepSeek V4, while it has caught up with industry trends and leading players at the model level, it still lacks its own Codex. Indeed, calls for this have grown loud, with someone even open-sourcing a terminal Coding Agent—DeepSeek TUI—based on DeepSeek V4 on Github, supporting Skills and many common features in Agent frameworks.
However, this is still a third-party developer's work, and their understanding of DeepSeek V4 is unlikely to match that of the official team, making it difficult to fully leverage V4's vertical integration advantages. The best hope is that, driven by feedback and calls from DeepSeek TUI, DeepSeek's official team will step in to create its own open-source Agent framework, its own Codex.
Large Model, Agent, DeepSeek, GPT, Codex
Source: Leikeji
Images in this article are from the 123RF licensed image library. Source: Leikeji
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







