DeepSeek Raises 50 Billion Yuan in Funding, but Liang Wenfeng Can't Escape Capital Game
 05/13 2026
05/13 2026
 581
581

The Capital Game: Liang Wenfeng Wants Money, but More Importantly, Control
Despite his quantitative trading background, Liang Wenfeng has always been wary of capital.
This is precisely why, in May's tech circle, no news was more impactful than DeepSeek's funding round.
According to The Information, citing multiple sources, DeepSeek is seeking to complete a funding round exceeding 50 billion yuan (approximately $7.35 billion). Founder Liang Wenfeng plans to personally contribute 20 billion yuan, accounting for 40% of the total raised. Tencent intends to invest 6 billion yuan for roughly a 2% stake, while the National Integrated Circuit Industry Investment Fund (the "Big Fund") is in discussions to lead the round.
If successfully closed, this would set a new record for single-round funding by a Chinese AI company, with a post-money valuation expected to surpass 350 billion yuan (approximately $51.5 billion).
Just 21 days earlier, in early April, DeepSeek's valuation stood at $10 billion, with an initial funding plan of just $300 million for option pricing. Twenty-one days later, its valuation has surged more than fourfold, while its funding scale has ballooned 24-fold.
For those familiar with Liang Wenfeng, this news is akin to a "nuclear explosion." The tech idealist, who had repeatedly declared a "moratorium on funding" and declined investment offers from Tencent and Alibaba, has suddenly reversed course—and on a staggering scale.
In fact, from domestic to overseas markets, several leading AI large language model (LLM) companies—including OpenAI, Zhipu AI, and Moonshot AI—are currently engaged in large-scale funding rounds. As we noted at the dawn of the LLM boom, this is a market where "gods clash."
Among them, DeepSeek is not a conventional "heavenly army" but rather a unique "Zhenyuanzi" (a reclusive, powerful figure in Chinese mythology).
The protagonist of this story, Liang Wenfeng, was born in Zhanjiang, Guangdong, in 1985. A graduate of Zhejiang University with bachelor's and master's degrees, he transitioned from leading High-Flyer Quantitative Trading, a private equity giant, to founding DeepSeek, remaining one of the most "maverick" figures in the tech world.
Today, times have changed. While companies once struggled to secure funding, DeepSeek has been swept into the AI-driven capital wave.
From High-Flyer Quant to DeepSeek: A "Technological Purist's" Journey
To understand this funding round, one must first grasp Liang Wenfeng and the "DeepSeek-style utopia" he built.
Liang's journey began in finance.
In 2008, shortly after graduating, Liang led a seven-person team using machine learning models for quantitative trading, achieving a 500% return in three months. By 2015, High-Flyer Quantitative Trading was formally established, rapidly rising to the top of the industry with AI-driven quantitative strategies.
By 2021, High-Flyer's assets under management exceeded 100 billion yuan, with an average annual return of 56.6% by 2025, generating over $700 million in income for Liang that year alone. DeepSeek's "financial independence" was never just talk.
But Liang's ambitions extended far beyond finance.
As early as 2020 or even earlier, Liang and his team believed artificial intelligence would be the future's core driver, with computational power as its foundation. While most firms focused on strategies and scale, High-Flyer made a then-radical, capital-intensive decision: to continuously reinvest substantial profits into building a massive GPU computing cluster.
In March 2020, its "Firefly-1" supercomputer, equipped with thousands of high-end GPUs and costing over 100 million yuan, went live. This far exceeded industry norms at the time, laying a solid foundation for its AI quantitative research and paving the way for its later foray into artificial general intelligence (AGI), including DeepSeek.
In April 2023, High-Flyer announced the establishment of DeepSeek, formally entering the AI sector. By July, Hangzhou DeepSeek AI Foundation Technology Research Co., Ltd. was registered, with Liang personally leading the charge from fintech to AGI.
At its inception, DeepSeek was the AI circle's most "Buddhist" outlier.
Liang set three ironclad rules for DeepSeek: no funding, no IPOs, no commercialization. During the 2023-2024 AI funding frenzy, this was a nearly "rebellious" choice.
While internet giants like ByteDance, Alibaba, and Baidu poured money into models while rapidly launching B2B and B2C businesses, and startups like Zhipu AI, Baichuan Intelligence, and Moonshot AI launched multiple funding rounds to fuel rapid expansion via capital infusions, DeepSeek relied on High-Flyer's "infinite blood supply" to conduct closed-door R&D, eschewing roadshows, publicity, and commercial orders.
Liang's reasoning was simple: technological idealism should not be hijacked by capital or commercialization.
He publicly stated, "DeepSeek's goal is to build a world-class general-purpose large model, not to make money or go public. Capital seeks short-term returns, and commercialization compromises technical routes—both would interfere with our core mission."
This purity propelled DeepSeek into the top tier of domestic LLMs.
In May 2024, DeepSeek-V2 was released, sparking debate with its innovative architecture and unbeatable cost-performance ratio. By December 2024, DeepSeek-V3 went open-source, revealing 53 pages of technical details.
In January 2025, DeepSeek-R1 was unveiled, matching OpenAI's o1 in mathematical, coding, and reasoning tasks. According to a paper published in *Nature* by its team, DeepSeek-R1's training cost just $294,000, with base LLM development costing around $6 million—far below figures disclosed by U.S. peers.
Technological success made DeepSeek a benchmark for domestic LLMs and turned Liang's "three nos" into an industry legend—proving that world-class models could be built without capital or commercialization.
But idealism collides with reality.
DeepSeek's Ideals Shattered by Triple Pressures
Liang's insistence on staying clear of capital circles underwent a strategic shift in April 2026.
A quantitative hedge fund veteran does not make impulsive decisions. Liang's pivot to capital likely followed calm (deliberate) calculations amid a qualitatively shifting competitive landscape for DeepSeek.
Public media reports highlight talent retention as a key trigger.
DeepSeek has long been seen as China's most unique LLM firm—small team, extremely high talent density, minimal external hiring, relying primarily on retained graduates and interns.
However, this lean, elite model amplifies the impact of each core researcher's departure.
Over the past year, DeepSeek has lost multiple technical leads to lucrative offers. AI prodigy Luo Fuli was poached by Xiaomi's Lei Jun, while researcher Guo Daya joined ByteDance as an Agent lead. Since late 2025, at least five core R&D personnel have departed, with major tech firms sparing no expense to recruit them.

This has led to industry speculation that Liang's recent funding drive aims to price employee stock options to retain talent.
If talent attrition is the "immediate concern," financial pressure represents the "long-term worry"—particularly computational costs.
AI LLM development is a typical (quintessential) "capital-intensive, high-investment, long-cycle" endeavor. While algorithmic ingenuity could once "punch above its weight" in LLM competitions, today's race is a brute-force computational arms race.
V4.1, slated for June 2026, will prioritize reasoning, multimodality, and stability—all requiring astronomical investments, from training to inference, NVIDIA to Ascend chips, and thousand-card to ten-thousand-card clusters.
No matter how wealthy High-Flyer is, it cannot sustain a head-on computational arms race with global giants. Critically, AI is a "fail-fast" industry: if funding lags, technical iteration stalls, and rivals quickly overtake.
Most importantly, the AI competition itself has qualitatively evolved, while capital markets' valuation logic for LLM firms has shifted.
Domestically, ByteDance and Alibaba are pouring billions into AI. Moonshot AI just closed a $2 billion round, valuing it at over $20 billion, with annual recurring revenue exceeding $200 million by April. MiniMax, StepFun, and others are also raising funds aggressively.
Meanwhile, Zhipu AI and MiniMax's post-IPO rallies have set industry valuation benchmarks. Startups that fail to secure valuations during this window risk seeing their primary market (primary market) valuations collapse.
Notably, StepFun is also actively preparing for an IPO.
These factors explain why Liang began raising funds—and why now.
But his approach again subverted industry norms: no dilution of control, no short-term capital, personally leading the round with 20 billion yuan to keep capital autonomy firmly in hand.
The Capital Game: Liang Wenfeng's Battle for Control
DeepSeek's 50 billion yuan funding round was never simply about "raising money due to need."
This was a meticulously designed capital game, with Liang's sole objective: to retain company control while bringing in capital, preventing investors from dictating technical routes.
According to Tianyancha business records, on April 27, 2026, Hangzhou DeepSeek AI Foundation Technology Research Co., Ltd. increased its registered capital from 10 million yuan to 15 million yuan. Founder Liang Wenfeng boosted his stake from 1% to 34% via direct capital injection, while original majority shareholder Ningbo Cheng'en Enterprise Management Consulting Partnership saw its stake diluted to 66%.
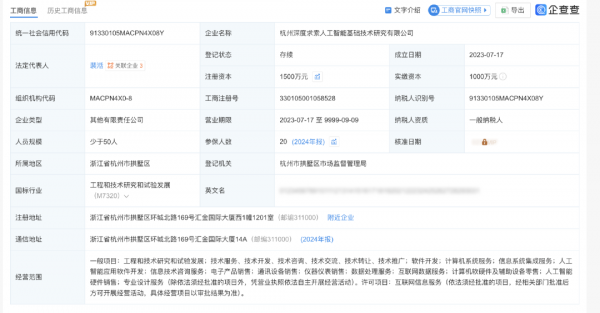
Through direct and indirect holdings, Liang controls approximately 84.29% of the company. Notably, this capital increase involved no new external shareholders—only Liang's 5 million yuan personal investment.
This indicates DeepSeek optimized its internal equity structure before launching large-scale external funding, with Liang solidifying control ahead of bringing in state and tech giants.
DeepSeek's funding differs from other LLM startups in two key ways:
First, the most shocking detail is not the 50 billion yuan scale but Liang's personal 20 billion yuan contribution (40% of the round), making him the largest investor.
This "founder-led mega-investment" model is rare in global AI history. Essentially, it is Liang's "control battle": "I'll accept your capital, but not your control."
Second, DeepSeek's investors appear carefully curated, accepting only two types of capital: state-backed funds and industrial capital, while rejecting traditional financial VCs (e.g., Sequoia, Hillhouse).
According to *Shanghai Securities News*, citing industry sources, the National Integrated Circuit Industry Investment Fund is negotiating to lead DeepSeek's first round. While talks are confirmed, final valuation remains undecided. Other participants include multiple internet giants and state-backed funds.
Subsequent reports confirmed Liang's 20 billion yuan personal investment (40% of the round), Tencent's 6 billion yuan for ~2%, and the Big Fund as the second-largest investor. Alibaba reportedly walked away after failing to agree on terms.
This investor structure reflects Liang's deep strategy: rejecting financial VCs, which typically demand exits within 3-5 years, forcing rapid commercialization and IPOs—antithetical to DeepSeek's "long-termist tech" ethos.
In contrast, state and industrial capital prioritize strategic value over short-term returns, avoiding interference in technical routes while providing policy, computational, and scenario-based resources.
Liang's 20 billion yuan personal stake buys him dialogue dominance at this valuation. Had he merely followed with a small investment or none at all, external investors would wield greater pricing power and strategic influence.
His 20 billion yuan commitment signals clarity: "I understand this company better than any external investor. You may participate, but my voice naturally prevails."
This is a highly sophisticated founder game theory (game-theoretic) strategy.
Thus, DeepSeek's funding embodies a multi-layered logic of "national strategy + founder resolve + ecosystem building + talent defense," while others pursue "tech expansion + commercialization + market share grabs."
This divergence reflects DeepSeek's unique role in China's AI landscape: not just a commercial firm but a national technological asset and key piece in autonomous, controllable strategic plans.
The Costs and Risks of Entering the Capital Game
With its valuation surging over 4x in 21 days, from $10 billion to $51.5 billion, many question: Is this a capital bubble? Is DeepSeek truly worth this much?
A brief comparison:
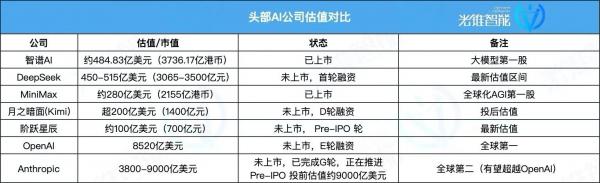
Data as of May 12, 2026
In China, DeepSeek's $45-51.5 billion valuation makes it the nation's second-most valuable LLM firm after Zhipu AI ($48.483 billion), surpassing MiniMax ($28 billion) and Kimi ($20 billion).
While Zhipu and MiniMax have achieved multi-billion-dollar Hong Kong stock market valuations (Zhipu over HK$370 billion, MiniMax over HK$210 billion), DeepSeek—as a pre-IPO firm—already approaches or exceeds these listed peers in primary market valuation.
More importantly, DeepSeek's valuation soared from $10 billion to $51.5 billion in just one month, a fivefold increase—a growth rate rarely seen in venture capital history.
Undoubtedly, in the Chinese market, DeepSeek stands in the first tier in terms of valuation and financing scale. However, compared to overseas market giants, DeepSeek still has a long way to go.
In terms of financing scale, OpenAI's $122 billion financing is 16.6 times DeepSeek's planned $7.35 billion financing, while Anthropic's $30 billion financing is 4.1 times DeepSeek's. Even if DeepSeek completes its $7.35 billion financing, its scale would still be a fraction of that of overseas giants.
From a valuation perspective, OpenAI's $852 billion valuation is 17 times DeepSeek's ($50 billion), while Anthropic's target valuation of $900 billion is 18 times DeepSeek's. DeepSeek's valuation is equivalent to only 5.9% of OpenAI's and 5.6% of Anthropic's.
It can be seen that DeepSeek, as a leading enterprise in China's large model sector, has set a domestic record with its $7.35 billion financing, and its valuation of $45-51.5 billion also makes it the second-highest-valued large model company in China. However, compared to overseas giants like OpenAI and Anthropic, DeepSeek still faces an order-of-magnitude gap in financing scale and valuation.
This gap reflects two realities of the global AI industry:
On one hand, global AI capital is highly concentrated in a very small number of leading companies; on the other hand, there is a difference between the AI ecosystems of China and the United States, with American companies enjoying global capital dividends while Chinese companies rely more on the domestic market and strategic capital.
However, the value of this round of DeepSeek's financing is not only reflected in its commercial valuation but also in its strategic position as a "national-level technological asset." With the involvement of the National Integrated Circuit Industry Investment Fund, DeepSeek is expected to play a key role in the construction of a domestic AI chip ecosystem and the autonomous control of large models, which may be its important differentiated advantage in competing with overseas giants.
However, the $7.35 billion financing and $51.5 billion valuation are not without risks.
DeepSeek's current commercialization model is relatively singular, relying mainly on API call fees. While its open-source strategy has built a broad developer ecosystem—with V4-Flash cache hit prices as low as 0.02 yuan per million tokens and V4-Pro at 0.025 yuan, Can be called the global bottom price ( Can be called the global bottom price , " can be rated as global bottom price")—many enterprise clients choose to deploy it themselves, diverting revenue from paid APIs. According to industry valuation logic, whether the $51.5 billion valuation can be supported by corresponding annual revenue remains the biggest uncertainty.
More subtly, there is the game of control. Through multi-layered limited partnership structures such as Ningbo Cheng'en, Ningbo Chengxin, and Ningbo Chengpu, Liang Wenfeng currently holds about 84% of the equity and nearly 100% of the voting rights. However, after introducing external shareholders such as the National Integrated Circuit Industry Investment Fund and Tencent, can this absolute control be sustained?
In addition, the pressure of talent attrition may not disappear with the financing. Meta once offered a staggering $200-300 million four-year contract to poach top researchers, with total compensation even exceeding that of the world's highest-paid football stars.
In an era where AI talent can be precisely priced, stock options and salaries are only part of retaining talent; technological ideals, research atmosphere, and growth opportunities are equally critical. Can DeepSeek maintain its pure ethos of "not being seduced by praise, not being intimidated by criticism" after capitalization?
From rejecting financing to self-investing 20 billion yuan, Liang Wenfeng's shift may seem sudden but is actually an inevitable choice under industry trends.
The AI competition in 2026 has evolved from a battle over model technology to a comprehensive war over computing power, talent, products, and ecosystems. In the face of this war, any attempt to remain aloof as a "technological utopia" is akin to entering a besieged city.
According to the plan, DeepSeek will release its new model, V4.1, in June, less than two months after the official release of V4 on April 24.
Although the official unveiling has not yet occurred, the information revealed is highly anticipated: it will natively support image and audio information understanding, processing multimodal inputs directly while outputting text, significantly lowering the barrier for enterprise data access. At the same time, the model will strengthen MCP protocol adaptation, providing richer enterprise-grade tools for scenarios such as office automation, intelligent customer service, and code generation.
The underlying technology continues the V4 hybrid attention architecture (CSA+HCA), with a million-token context becoming standard, inference costs further reduced from the previous generation, and video memory usage only about 2% of traditional models.
Clearly, such rapid technological iteration requires sustained financial support. In this capital game, there are no winners who take all—only the fittest survive.
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!
-
![]()
AI Agent Smartphones: The Next Competitive Edge Transcends Large Models
-
![]()
Over 880 Million Yuan Worth of Orders Unveiled, Bidding Launched for Shenzhen Eastern Public Transport
-
![]()
Tesla's Robotaxi Hits the Road: A Monumental Gamble with an Uncertain Future







