Which enterprises have incorporated world models into their autonomous driving solutions, and what are the differences in their implementations?
 05/19 2026
05/19 2026
 529
529
After going through two stages—rule-driven and imitation learning—the autonomous driving industry is collectively moving towards a key direction: enabling AI to understand the underlying operating principles of the physical world. This direction is known in the industry as the world model. Rather than merely reacting to what the model perceives, it requires the model to internally simulate scenarios and answer causal questions such as, “If I do this, what will happen next?”
In October 2025, Ashok Elluswamy, Vice President of AI at Tesla, provided a detailed introduction to the FSD technical framework at the ICCV, a premier computer vision conference. Multi-camera images, navigation maps, vehicle motion information, and audio signals are input into a unified end-to-end neural network, which, after training on massive amounts of data, directly outputs control signals. Elluswamy explicitly stated that end-to-end AI is the future of autonomous driving and publicly unveiled Tesla's Neural World Simulator for the first time. Instead of predicting actions, this simulator synthesizes future states based on the current state and the next action, forming a closed-loop evaluation with the in-vehicle model.
Around the same time, companies such as Huawei, NIO, Momenta, QCraft, Horizon Robotics, SenseTime Jueying, and Wayve unveiled their respective world model solutions. While all refer to this technology as world models, there are significant differences in how they are used, where they are deployed, and the problems they solve.
What is the underlying idea behind world models?
To understand the differences in how companies apply world models, it is essential to first grasp their foundational logic.
Traditional autonomous driving systems adopt a cascaded architecture of perception, prediction, planning, and control, with each stage relying on rules defined by human engineers or annotated data for connection (connection). This approach has a problem: information transfer between these intermediate stages is lossy, and what is missed upstream cannot be remedied downstream. During his ICCV presentation, Elluswamy explicitly pointed out that in modular approaches, the interfaces between perception, prediction, and planning are poorly defined, whereas in end-to-end architectures, gradients flow from control all the way back to sensor inputs, enabling holistic optimization of the entire network.
World models attempt to establish a compressed representation of the external environment within the model. This representation not only contains spatial geometry and semantic information but also encodes causal context. In this internal representation space, the model can simulate future scenario evolution based on candidate actions. It not only predicts what will happen but also makes judgments such as, “If I take this action, how will other road users react?” This implies that the model has the capability to rehearse decisions before making them.
It should be noted that world models and end-to-end approaches are not mutually exclusive concepts. Chen Xiaozhi, Chief Scientist at Zoyu Technology, emphasized at the 2025 Apsara Conference that concepts like world models, VLA, and one-stage end-to-end approaches are not mutually exclusive technical routes. In practice, most companies embed world model capabilities into a larger technical framework, with some focusing on cloud-based simulation and others on in-vehicle inference.
World models generally cover three types of tasks: future physical world generation, behavior planning and decision-making, and joint prediction and planning. In practical implementations, some companies focus on cloud-based data generation and simulation training, others deploy world models in vehicles for real-time inference, and still others use them specifically for safety assessment and verification.
AI driving school versus in-vehicle brain: The divergence between cloud and in-vehicle routes
While many companies are researching world models, there are disagreements regarding their deployment location and functional positioning, reflecting different technical judgments—whether to have world models work behind the scenes in the cloud or to install them directly in vehicles for millisecond-level real-time decision-making.
Huawei's Qiankun Intelligent Driving WEWA architecture is representative of the cloud-vehicle division of labor. At the end of 2025, Jin Yuzhi, CEO of Huawei's Intelligent Automotive Solution BU, provided a detailed introduction to this architecture, which consists of two core components: the World Engine running in the cloud and the World Action Model running in the vehicle.

WEWA architecture. Image source: Internet
The World Engine is positioned as a cloud-based driving school. Based on real-world road data, it constructs challenging scenarios using diffusion generative models. For example, an originally empty road can be simulated to include sudden pedestrian appearances, cut-ins from side vehicles, and abrupt braking by the vehicle ahead, among other combined conditions. The density of challenging scenarios is increased by 1,000 times compared to the real world, with all simulations adhering to the laws of the physical world.
The in-vehicle World Action Model is the industry's first intelligent driving-native foundational model with full-modality perception capabilities. It can invoke different abilities based on various scenarios. After adopting this architecture, the ADS 4 system achieved a 50% reduction in end-to-end latency, a 20% improvement in traffic efficiency, and a 30% reduction in harsh braking rates.
Tesla's approach shares similarities with Huawei's in concept but follows a more aggressive implementation path. Elluswamy revealed that Tesla's FSD architecture faces a dimensionality disaster, with visual inputs from seven cameras at 36 FPS and 5-megapixel resolution over 30 seconds, combined with navigation maps and motion data, resulting in approximately 2 billion input tokens. The neural network needs to condense these 2 billion tokens into just two outputs (steering and acceleration).

Image source: Internet
Tesla's solution is to use massive fleet data to identify key tokens, retaining only the most useful information through sparsification and aggregation. On the simulation side, Tesla developed the Neural World Simulator, trained on its self-built massive dataset, capable of generating future states based on the current state and the next action, forming a closed loop with the in-vehicle end-to-end foundational model for both evaluation and reinforcement learning training. This simulator also enables AI to learn the equivalent of 500 years of human driving experience in a single day.
NIO's NWM (NIO World Model) focuses on in-vehicle real-time simulation. In May 2025, NIO officially began rolling out the first version of its self-developed NWM, covering over 400,000 vehicles equipped with the Banyan intelligent system. NWM is a multivariate autoregressive generative model with both spatial and temporal understanding capabilities. Spatially, it reconstructs sensor inputs through generative models to generalize and extract information. Temporally, it automatically models long-term environmental changes through autoregressive models.
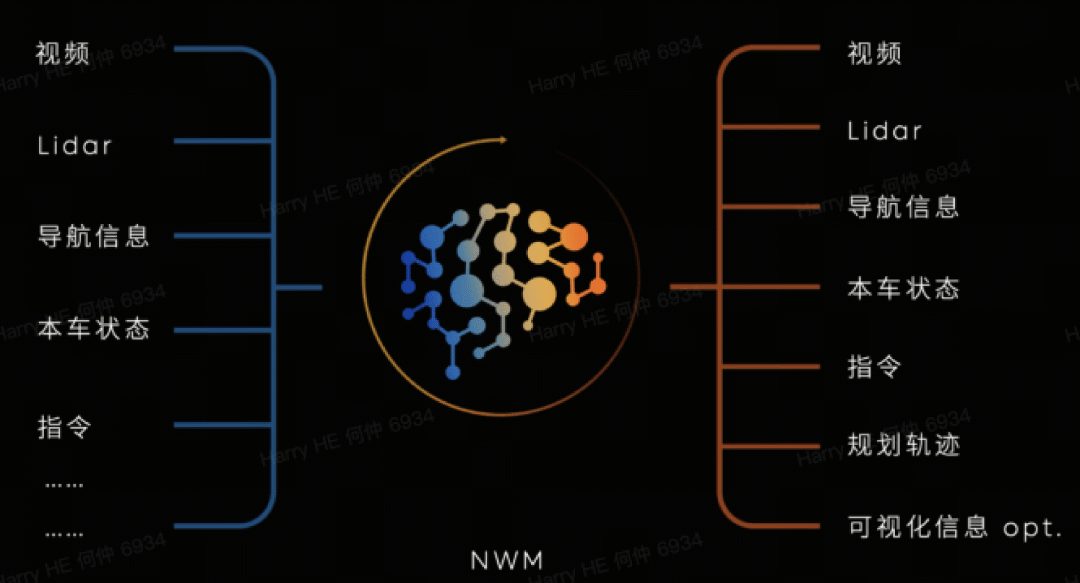
Image source: Internet
It can simulate 216 possible trajectories within 100 milliseconds and find the optimal path, then continue to update its internal model based on external information inputs in the next 100 milliseconds, predicting another 216 possibilities and continuously seeking the optimal solution. In addition to NWM, NIO has also developed the generative simulation model NSim, which together forms closed-loop simulation testing capabilities.
Momenta's R7 reinforcement learning world model adopts a three-tier progressive architecture. According to Xia Yan, Momenta's Partner and SVP of R&D, the first layer is world model pre-training, where the model learns physical common sense through massive real-world driving data. The second layer is closed-loop simulation, where extreme scenarios are simulated virtually. The third layer is reinforcement learning, where AI repeatedly tries and optimizes in a highly realistic environment.
Momenta CEO Cao Xudong announced at the 2026 Beijing Auto Show that the R7 had achieved mass production and launch (first launch), proposing that world models and reinforcement learning constitute the two core pillars of physical AI. This layered design decouples physical common sense learning from driving behavior optimization, with pre-training responsible for understanding physics and reinforcement learning responsible for driving well.
QCraft adopts a unified architecture combining VLA, world models, and reinforcement learning, explicitly proposing the concept of safe end-to-end driving. This involves integrating proven spatiotemporal joint planning experience into the One Model design while constructing a world model based on motion simulation during offline training. Its motion simulation world model is characterized by more controllable generated simulation videos, ensuring consistency and correctness in timing, spatial positioning, object geometry, and physical rules. This differs from traditional world models, which focus on generating visual realism.
Training partner or safety examiner?
At the cloud application level, companies have also diverged in how they position the functional role of world models.
SenseTime Jueying's Jueying Enlightenment World Model focuses on generative capabilities. Wang Xiaogang, CEO of SenseTime Jueying, proposed in September 2025 that intelligent driving is transitioning from rule-based Level 1.0 and end-to-end Level 2.0 to generative Level 3.0. At WAIC 2025, SenseTime Jueying unveiled an upgraded version of the industry's first mass-produced, interactive “Jueying Enlightenment” world model, releasing a generative world model product platform and the industry's largest generative driving dataset, WorldSim-Drive. Wang summarized the value of world models as three breakthroughs: breaking through data bottlenecks (generating infinite long-tail scenarios), establishing more certain technical safety boundaries (continuous testing in simulation), and achieving driving experiences surpassing human capabilities through autonomous evolution.

Image source: Internet
Wayve's GAIA-3 takes a distinct approach, positioning the world model as a safety examiner. In December 2025, Wayve officially released GAIA-3, a generative world model with 15 billion parameters, double the size of its predecessor, GAIA-2. Its video tokenizer also doubled, and its pre-training dataset increased tenfold, covering multiple continents, vehicle models, environments, and driving conditions.
GAIA-3 has the capability to generate safety-critical scenarios, supporting what-if counterfactual reasoning tests in offline environments and featuring embodiment transfer functionality for consistency assessment across different sensor configurations. Jamie Shotton, Chief Scientist at Wayve, stated that GAIA-3 advances world modeling from visual synthesis to true autonomous driving evaluation and verification. Early research shows that GAIA-3's simulation test results are highly consistent with real-world road tests and reduce the rejection rate of synthetic tests by four-fifths. This approach integrates generation and evaluation into a single world model framework, making safety verification less dependent on limited real-world road test mileage.
Academic exploration is also driving the generalization of world models. The Drive-WM proposed by the Institute of Automation, Chinese Academy of Sciences, is the first driving world model compatible with existing end-to-end planning models, with its paper published at CVPR 2024. Drive-WM employs multi-view joint spatiotemporal modeling, generating high-fidelity multi-view driving videos through diffusion models and combining multi-view prediction with end-to-end planning to provide reward and penalty feedback for trajectory optimization. Zoyu Technology also unveiled its new multimodal end-to-end world model at the end of 2025, announcing the formation of its data-driven spatial intelligence mobility foundation.
World models within end-to-end systems and VLA: Parallel technical judgments
As the world model route gradually takes shape, VLA (Vision-Language-Action models) is also rapidly developing, leading to considerable discussion within the industry about the relationship between the two routes.
Huawei's stance is clear. Its WEWA architecture does not incorporate language models as an intermediate layer; instead, the World Action Model directly processes multimodal perception inputs and outputs driving actions. Huawei believes that adding a language reasoning module to the driving decision chain introduces information loss and that true autonomous driving should enable the model to directly understand the physical world.
Some companies pursue a parallel route combining VLA and world models. XPENG Motors disclosed its 72 billion-parameter XPENG World Foundational Model in April 2025. Built on a large language model backbone network, it possesses visual understanding capabilities, long-chain reasoning abilities, and action generation capabilities. XPENG's approach involves knowledge distillation from the foundational model to the vehicle, overcoming the limitation of limited model parameters in vehicles. Its technical path follows the world model framework of understanding, simulating, and generating, with the model internally reconstructing a digital representation of the physical world, predicting environmental changes under different decisions, and directly generating control actions after selecting the optimal path. This approach seeks to find a balance between the spatial reasoning capabilities of world models and the common-sense reasoning abilities of language models.

Image source: Internet
Horizon Robotics' HSD chooses to have its VLM (Vision-Language Model) play only a supplementary role, used solely for recognizing text information such as road signs, without relying on large language models to understand traffic conditions themselves. The main driver of driving decisions remains an end-to-end visual model combined with reinforcement learning within the world model. HSD adopts a one-stage end-to-end plus reinforcement learning architecture, achieving photon input to trajectory output, with reinforcement learning enabling self-exploration and interaction within the world model to enhance scenario understanding and reasoning capabilities.
It is worth noting that this parallel route is likely just a transitional state. Wang Xiaogang, CEO of SenseTime Jueying, pointed out that the bottleneck of end-to-end autonomous driving lies in human behavior representing the ceiling of intelligence, along with dependence on large volumes of high-quality data. The combination of world models and reinforcement learning has the potential to break through this limit. As world models improve in physical common-sense modeling and causal reasoning capabilities, pure visual simulation may gradually cover the scenario understanding functions currently supplemented by language models. Conversely, if the multimodal reasoning capabilities of large language models continue to evolve, the boundaries between the two routes may further blur.
Setting aside debates over specific routes, the industry is united on a fundamental issue: enabling AI to truly understand the laws of the physical world and continuously learn and improve through trial and error in safe virtual environments is an indispensable step toward achieving high-level autonomous driving.
-- END --
-
![]()
Focus | CCCC’s Takeover of Greentown Comes to Fruition: Why Did the 11-Year ‘Control Without Authority’ Era End?
-
![]()
Final Verdict: The 2026 China Auto Forum Shines with Unique Characteristics at a Pivotal Moment
-
![]()
Tencent Maintains Matrix Approach, Alibaba Merges Entry Points: Tech Titans Initiate AI Agent Consolidation
-
![]()
Geely Secures Portion of Ford’s Spanish Production Capacity
-
![]()
Tesla Stalls This Second
-
![]()
Elon Musk's 'Money-Burning' Spree: All Car Sales Profits Poured into AI
-
![]()
Why Did Tesla’s Profits Drop and Cash Flow Go Negative?
-
![]()
AI Titans Are All in the Red: Time for Intelligent Driving Car Buyers to Reassess?







