AI Accelerator: The Powerhouse Behind AI Algorithm Operations and Applications
 05/26 2026
05/26 2026
 641
641
Preface
At present, AI is swiftly becoming an integral part of our learning, work, and daily routines, significantly steering the course of social development towards enhanced intelligence and convenience.
Utilizing AI chatbots and large-scale AI models necessitates substantial computing power in the background. This article explores the fundamental logic of AI hardware devices that underpin these applications, demonstrating robust application services through intricate underlying operations.
1. AI Accelerator
The quest for intelligent technology and an intelligent society defines our era. Artificial intelligence (AI) and deep learning (DL) algorithms are pivotal in fulfilling these aspirations, paving the way for an intelligent world and systems. Enhanced computing capabilities, increased sensor data, and refined AI algorithms are propelling cloud- and edge-based intelligent machine learning (ML) trends. These technologies find application in smart devices, wearable electronics, smartphones, automobiles, robots, drones, and more. However, efficient hardware alone is insufficient to achieve the performance required for executing these algorithms. Hence, AI accelerators emerge as a cutting-edge research area for circuit and system designers as well as academia, catering to the ever-growing demands of compute-intensive AI applications.
Typically, four research areas drive the demand for AI accelerators (as depicted in Figure 1). Neuroscience offers insights into how the human brain acquires intelligence. AI researchers endeavor to emulate these concepts to develop AI algorithms that infuse machines with intelligence. Researchers in cyber-physical systems (CPS) or intelligent systems strive to apply these innovations to devise solutions for an intelligent society. These solutions may be software-based or involve wearable devices. In any case, efficient hardware is inherently required to implement these innovations in practical applications. Therefore, AI accelerators represent a highly regarded research direction within the AI research landscape.
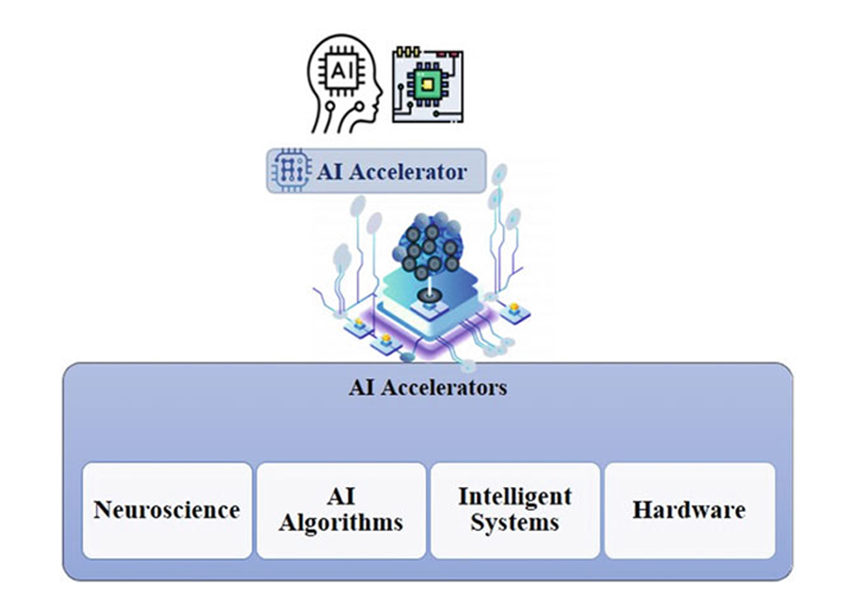
Figure 1 Main Research Areas for Developing Efficient AI Accelerators
Device-end AI is another burgeoning system-on-chip (SoC) technology that enhances the intelligence and speed of connected devices, including automobiles, high-definition (HD) cameras, smartphones, wearable devices, and other Internet of Things (IoT) devices. Popular applications at the device end encompass facial detection, object detection and tracking, posture detection, and speech recognition. Moreover, device-end inference is gaining popularity over cloud-based models due to its lower latency and stronger privacy. However, executing these compute-intensive tasks on small devices poses challenges due to their limited computing power and higher energy consumption. Furthermore, the global pandemic has necessitated a 'new normal,' accelerating digital transformation across various domains such as the digital economy, digital finance, digital government, digital health, and digital education. Indeed, multiple initiatives for digital platforms and solutions already exist, with AI and SoC making these possibilities a reality.
Additionally, device-end AI enables instant responses, bolsters reliability, enhances privacy protection, and optimizes network bandwidth utilization, supporting numerous functions ranging from computer vision and natural language processing—surpassing human capabilities—to wireless connectivity, power management, photography, and more. However, the algorithmic advantages of intelligent systems hinge on extremely high computing power and memory, relying on high-performance hardware. This presents a significant challenge in designing suitable hardware platforms capable of seamlessly executing state-of-the-art AI and ML algorithms. Furthermore, such devices should exhibit lower latency, higher reliability, and the ability to safeguard user privacy. Therefore, to meet these ever-increasing demands, there remains a need to equip devices with AI accelerators.
Moreover, automation in the transportation sector is crucial to meet growing urbanization and transportation demands. Artificial intelligence elevates Intelligent Transportation Systems (ITS) to new heights, namely high driving automation (Level 4) and full driving automation (Level 5). However, introducing Level 4 and higher autonomous vehicles (AVs) into the real world encounters various obstacles. Additionally, identification mechanisms and corresponding backup systems are essential to provide responses when these autonomous vehicles encounter abnormal situations, such as distinguishing between humans and non-humans, recognizing traffic signs and gestures, in-car monitoring, personal privacy protection, suspect identification, adverse weather conditions, road damage, and obstacle detection.
2. Overview of AI
Artificial intelligence (AI) is a technology that imbues devices, machines, software, hardware, etc., with intelligence. It encompasses a vast scope, covering machine learning (ML) and brain-inspired methods such as spiking neurons, neural networks (NN), and deep learning (DL) techniques, as shown in Figure 2. With recent research and development in ML and DL algorithms, AI continues to evolve. Deep neural networks (DNNs) now surpass humans in various cognitive tasks. Some notable examples where AI outperforms humans include art and style imitation, image and object recognition, prediction, video games, speech generation and recognition, and website design modifications.
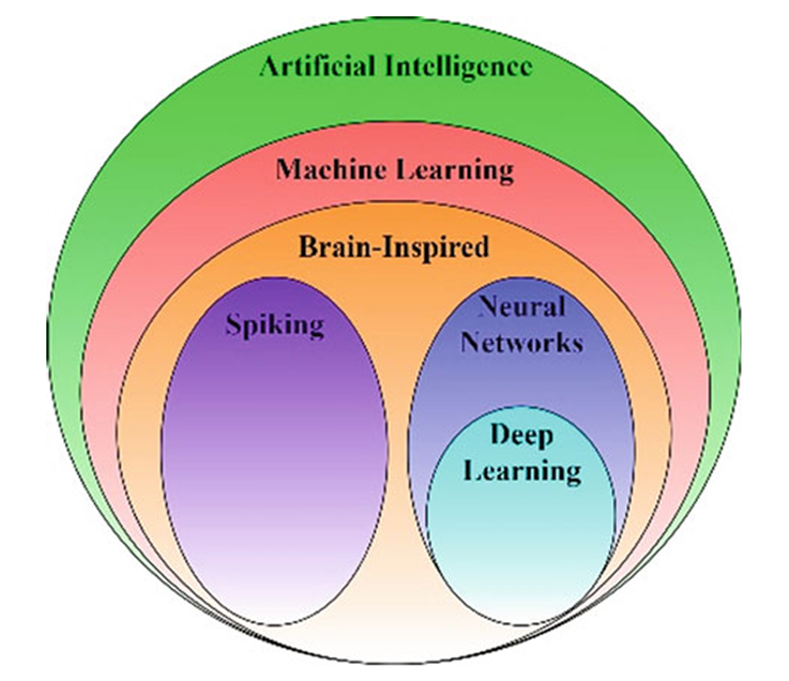
Figure 2 The Scope of Artificial Intelligence
AI imbues machines with intelligence, a development driven by neuroscience. The thoughts and discoveries of neuroscientists have been incorporated into AI methods to develop brain-inspired algorithms. Artificial neural networks (ANNs), spiking neural networks (SNNs), and deep learning (DL) are some typical examples.
ML is a method that enables machines to learn problem-solving skills. A machine learning model undergoes two phases: training and inference. During the training phase, the model attempts to learn skills, while during the inference phase, it makes actual predictions. Machine learning algorithms are further subdivided into four broader categories: supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning (as illustrated in Figure 3).
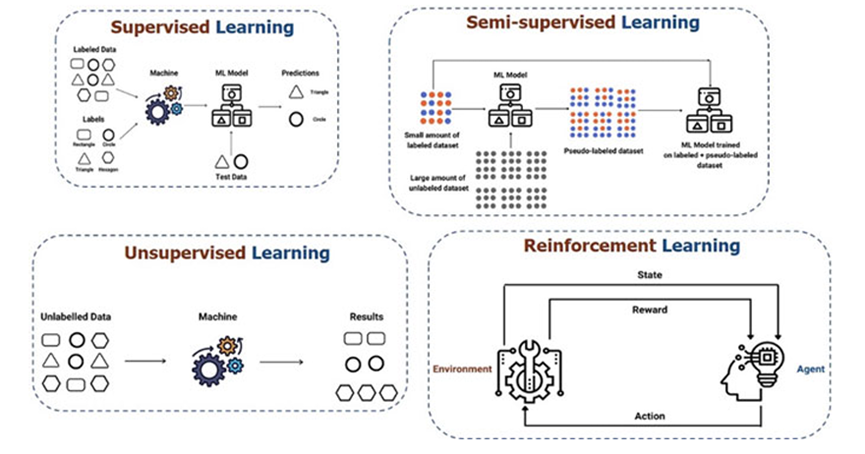
Figure 3 Machine Learning
Supervised Learning: Utilizes labeled datasets to train algorithms. During training, the model endeavors to identify features or characteristics of elements with the same label and employs these features to classify given inputs into appropriate categories during inference.
Semi-Supervised Learning: In one scenario, datasets contain a small number of labeled samples, with the remaining samples unlabeled. Utilizing the small set of labeled datasets, semi-supervised learning methods attempt to pseudo-label more unlabeled datasets. Furthermore, both labeled and pseudo-labeled datasets are employed to train machine learning models. The algorithm should be capable of predicting new samples based on the learned features.
Unsupervised Learning: Employed to cluster items when there are no explicit categories or pre-existing labels. This method aims to learn existing similarities between samples in a dataset and clusters the dataset based on its similarity features.
Reinforcement Learning: In this category of machine learning algorithms, no dataset exists. An agent endeavors to find the optimal strategy to achieve a goal in a simulated environment. The agent receives rewards during its interaction with the environment. Rewards can be positive, indicating correct decisions, or negative, indicating penalties for wrong actions or behaviors. The reward mechanism aids the agent in finding the optimal strategy and thus making the best actions.
3. AI Applications
The industrial and academic sectors have applied AI technologies in various forms. Many applications incorporate AI technology in some manner. Figure 4 illustrates the areas where AI has been rigorously applied. In the aerospace sector, AI is utilized for commercial flight autopilot, weather monitoring, etc. In sports, it involves wearable technology, smart ticketing, automated video highlights, and various computer vision-based applications. Mobile (smartphone) phones enhance the intelligence of their applications by applying AI. Similarly, workplaces, entertainment, hospitality, media, gaming, education, commercial centers including retail and online shopping, transportation, banking and finance, government and politics, events, insurance, cybersecurity, smart homes, defense, social networks, real estate, agriculture, healthcare, etc., have all utilized AI technology in various forms.
Figure 4 Multifaceted Applications of AI
Some popular areas of AI include:
Computer Vision (CV): Further subdivided into machine vision, video/image recognition, etc.
Machine Learning (ML): Conducted in supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning.
Natural Language Processing (NLP): Chatbots, classification, content generation, and content/semantic recognition are typical applications involving NLP.
Expert Systems: Knowledge-based systems aiming to solve complex problems in professional fields through knowledge reasoning to simulate the decision-making abilities of human experts.
Recommendation Engines: Utilize data filtering tools to recommend the most relevant items to individuals. Netflix, YouTube, Amazon, etc., are typical examples of recommendation systems.
Robotics: Robots should replicate human actions, and AI enables them to achieve this seamless replication.
Speech: AI-driven speech recognition provides the functionality to convert speech to text or text to speech.
4. AI Algorithms
There is an increasing demand for the implementation of AI algorithms in industrial applications. AI algorithms based on deep learning typically follow the trend of training and inference, as shown in Figure 5.
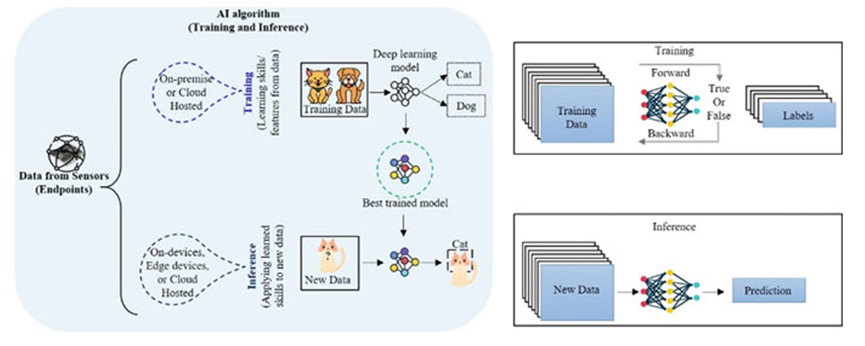
Figure 5 Schematic Diagram of AI Algorithm Training and Inference
Sensors serve as the endpoints of AI systems, providing the necessary databases for training and inference. Training and inference can be hosted in the cloud or implemented on-board, on-chip, or on edge devices. Deep learning models should learn skills or features by extracting information from the databases available during training. Training datasets are usually labeled. Therefore, AI algorithms attempt to identify features/patterns by adjusting the weights and biases associated with corresponding neurons and connections during the 'forward' pass. During the 'backward' pass, these weights and biases are updated by calculating the error. Convolutional neural networks (CNNs) are employed in deep learning algorithms. Figure 6 illustrates the concept of a typical CNN. The features of the input image are extracted using convolutional kernel (filter) layers, pooling layers, and applying activation functions (also known as transfer functions, such as Rectified Linear Units (ReLU), etc.).
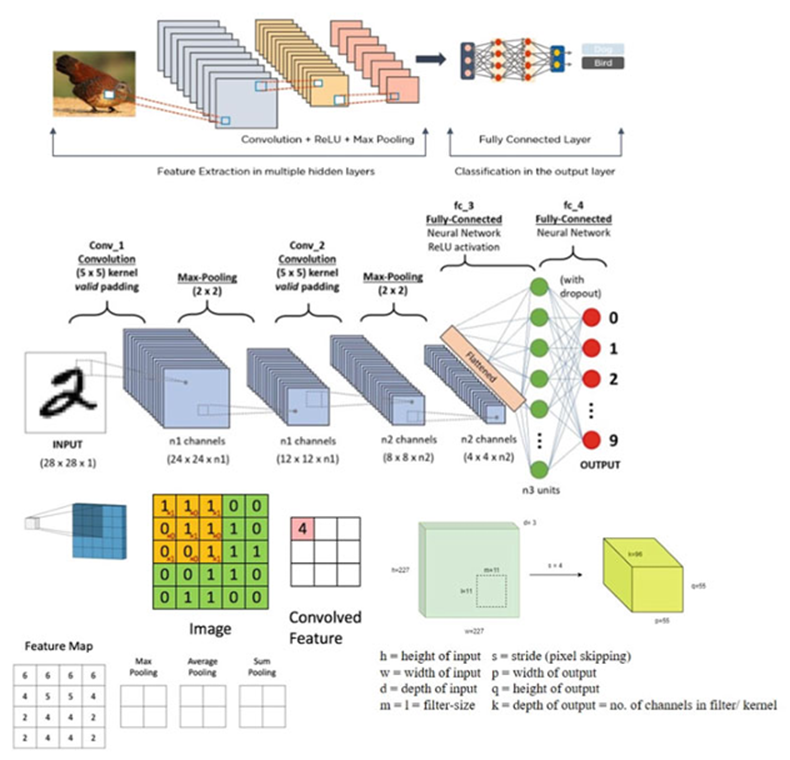
Figure 6 Schematic Diagram of CNN
Fully connected layers are utilized for classification operations at the output layer. There may be max pooling operations, where the maximum value among the convolutional kernel values is taken as the output value of the max pooling layer. Similarly, average pooling or sum pooling, corresponding to the average value and the sum value, respectively, represent the outputs of the corresponding pooling layers. Some standard concepts used in convolutional neural networks are also shown in Figure 6. Stride defines the number of pixels moved on the input matrix when performing convolution operations; padding maintains the input size by adding zeros, etc. The output height and width of the convolutional layer can be derived from (1) and (2):
Output (width) = ⌊ (Input (width) + 2 × (padding) − filter (width))/stride+1⌋ (1)Output (height) = ⌊ (Input (height)+2 × (padding)−Filter(height))/stride+1⌋.(2)
Figure 7 describes the forward and backward propagation of the convolutional layer in training and inference, as well as multiply-accumulate (MAC) operations.
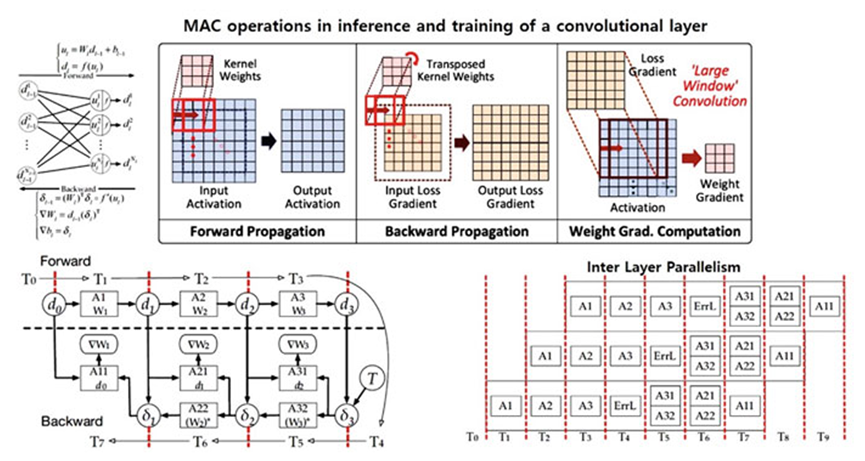
Figure 7 Brief Explanation of CNN
In forward propagation, the kernel weights (W) convolve with the input, and the corresponding bias (b) is added to generate the intermediate output (u) before activation at layer l. The activation function is represented as (f) in both forward and backward propagation. Forward propagation and backward propagation are defined by (3) and (4), respectively, as follows:
Forward propagation: − Intermediary output: ul = (Wl) × (dl-1) + (bl-1). Final output: dl = f (ul). (3)Backward propagation: − Error for the previous layer (l − 1)th layer: δl−1 = (Wl)T × (δl) × f′(ul). Weight gradient of the lth layer: ∇Wl = f (ul). Bias gradient of the lth layer: ∇bl = δl. (4)
Forward and backward propagation are implemented on hardware using registers, multipliers, and adders, as shown in Figure 7, and are completed within seven clock cycles (T1 to T7). Inter-layer parallelism is demonstrated by introducing parallelism within the same clock cycle to illustrate computational acceleration.
The concept of intelligent machines was proposed as early as the 1940s. Figure 8 shows a timeline of some groundbreaking algorithms, along with the two AI winters (prior to deep neural networks, i.e., deep learning). The famous duo McCulloch and Pitts introduced an electronic brain. It learned basic logical functions such as AND, OR, and NOT operations. Rosenblatt introduced the "Perceptron," which could simulate these logical operations.
Similarly, in 1960, ADALINE made its debut, boasting learnable weights and thresholds. However, the XOR problem emerged in 1969, triggering the first AI winter. Although this period led to a stagnation in AI research, it also fueled the demand for more efficient algorithms. Thus, it can be seen as a software (algorithmic) prerequisite in AI research. Researchers have been tirelessly seeking solutions to the XOR and nonlinear problems. Rumelhart and colleagues tackled the classic XOR problem using Multi-Layer Perceptron Learning (MLP). Nevertheless, the substantial computational requirements of the MLP model for handling complex problems led to another AI winter. This second AI winter once again slowed the progress of AI research, but it also heightened the demand for efficient computing systems. Hence, it can be viewed as a hardware (accelerator) prerequisite in AI research.
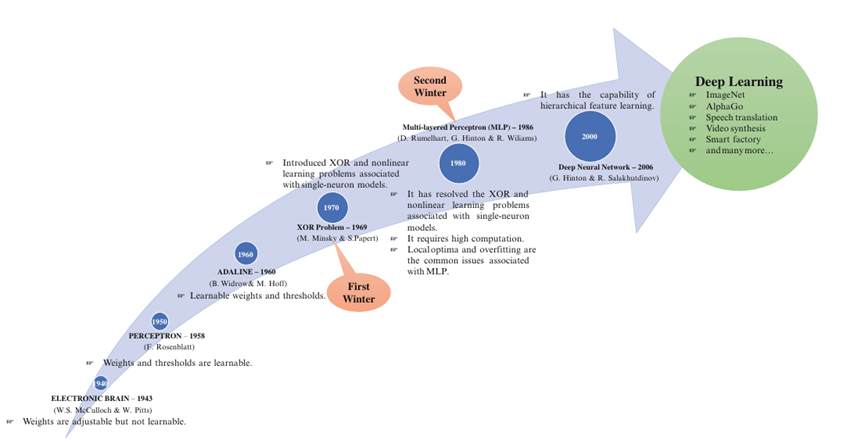
Figure 8: Timeline of AI Methods
Having experienced two AI winters, AI research fell into a pseudoscientific state. Fortunately, some researchers persevered in their work on AI and deep learning, significantly sustaining the progress of AI. In 1995, Cortes and Vapnik developed the Support Vector Machine (SVM), a system designed for mapping and identifying similar data. In 1997, Hochreiter and colleagues introduced Long Short-Term Memory (LSTM) for recurrent neural networks. AI research received a significant boost in 1999 with the advent of rapid processing capabilities provided by Graphics Processing Units (GPUs). This advancement increased the computational speed of images and graphics severalfold. Consequently, with the emergence of GPUs and larger datasets, AI research regained momentum in the early 2000s. In 2006, Hinton and colleagues made significant strides in deep learning research, ensuring its potential and outcomes for future AI research.
Moreover, the development of open-source and flexible software platforms, such as Theano, Torch, Caffe, TensorFlow, and PyTorch, provided the necessary impetus for current AI research. As a result, more advanced AI algorithms were subsequently introduced. Figure 9 presents a timeline of some popular AI algorithms used in deep learning.
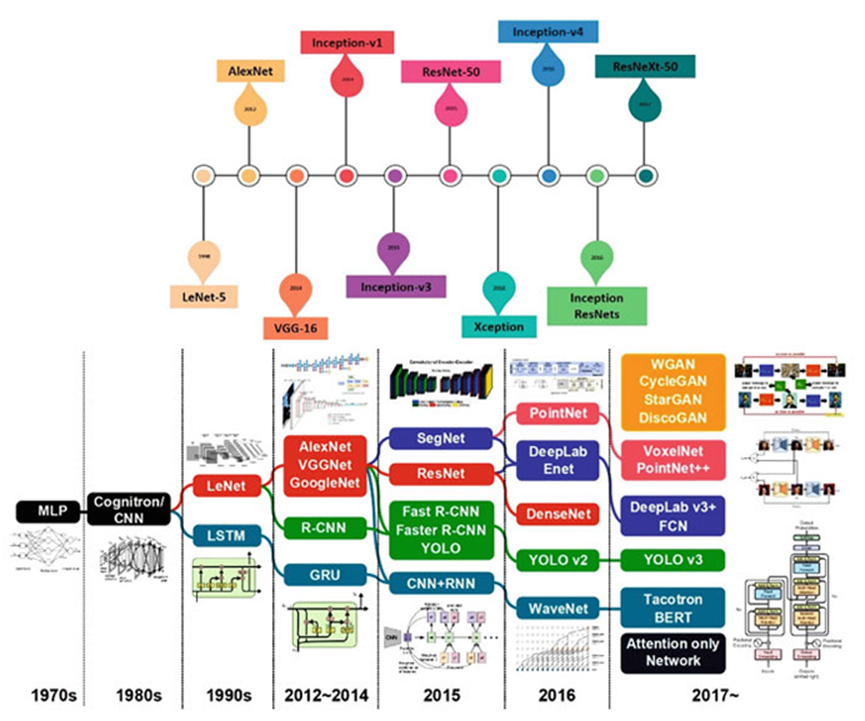
Figure 9: Timeline of Popular Deep Learning Algorithms
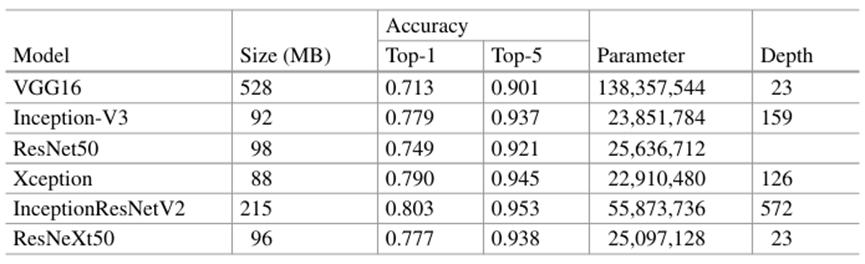
There are generally two methods to measure the accuracy of AI algorithms: Top-1 accuracy and Top-5 accuracy. In Table 1, Top-1 and Top-5 accuracy represent the model's performance on the ImageNet validation dataset. Depth indicates the topological depth of the network, encompassing convolutional layers, pooling layers, activation layers, batch normalization layers, etc. Top-1 accuracy is the traditional metric, considering only the single category with the highest probability. In contrast, Top-5 accuracy uses the top five categories instead of a single one. For example, for an image of a blueberry, the probabilities predicted by the AI algorithm are as follows: Cherry: 0.35%; Raspberry: 0.25%; Blueberry: 0.2%; Strawberry: 0.1%; Apple: 0.06%; Orange: 0.04%. According to Top-1 accuracy, the prediction (Cherry: 0.35%) is incorrect. However, according to Top-5 accuracy, the prediction is correct because blueberry is among the five categories with the highest probabilities.
Table 1: Comparison of Size, Accuracy, Number of Parameters, and Depth of Several Mainstream AI Models
After the development of efficient AI methods, various applications have emerged that transform machine intelligence into augmented intelligence. In other words, AI is currently enhancing the intelligence of devices. Consequently, AI on edge devices and AI within devices have witnessed tremendous development. In another area of AI research, particularly in unseen environments and scenarios, active learning and federated learning methods have played a significant role. Figure 10 illustrates the fundamental components of active learning and federated learning methods. Active learning, also known as "query learning" or sometimes "optimal experimental design," is a form of semi-supervised learning where "active" implies continuous learning by the AI model.
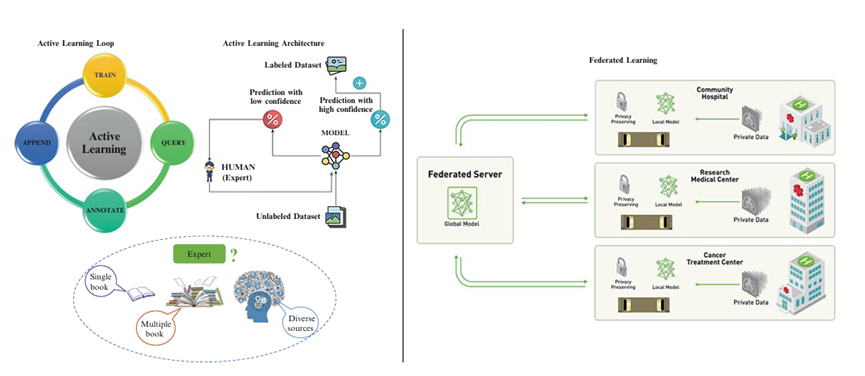
Figure 10: Basic Modules of Active Learning and Federated Learning Methods
In various complex tasks such as speech recognition, information extraction, classification, and filtering, obtaining labeled instances is often complex, time-consuming, or costly. Active Learning (AL) provides a method for self-labeling and is commonly used in these problems. Active learning selects the most uncertain unlabeled samples (queries) to be labeled by humans (experts) and iteratively labels similar remaining data. The key feature of active learning is curiosity, which is why it achieves higher accuracy with fewer labeled instances. In the active learning loop, there are four aspects: training, querying, labeling, and appending. "Training" refers to training the model on a labeled dataset. "Querying" involves using some acquisition function to select unlabeled samples from the dataset. "Labeling" refers to the annotation of the selected samples by an oracle (subject matter expert). Finally, "appending" involves adding the newly labeled samples to the training dataset.
AI-based Active Learning (AL) architectures typically compare the predictive confidence of unlabeled datasets and decide whether to consult an expert (e.g., a human) based on this confidence. Depending on the predictive confidence, unlabeled datasets are added to the labeled dataset for further training. Therefore, "querying" is an important task in AI-based active learning architectures. Another important task is "labeling," which is done by experts. So, who should be the expert? The expert should be a Subject Matter Expert (SME). Therefore, depending on the queries, it is best to leverage diverse knowledge from different sources.
Federated Learning (FL) is a decentralized approach in machine learning, initially proposed by Google. It enables AI models to acquire diverse experiences from different datasets located at different sites, which may be local data centers or central servers, without the need to share training data with the main central server. It is based on iterative model averaging and inherently has the potential to protect individual user privacy. Yang and colleagues further classified federated learning into horizontal federated learning, vertical federated learning, and federated transfer learning, categorizing it based on data partitioning among various participants in the feature and sample spaces. Li and colleagues introduced the challenges, methods, and future directions of federated learning. Zhang and colleagues surveyed the recent developments and research in federated learning, considering five aspects: data partitioning, privacy mechanisms, machine learning models, communication architectures, and system heterogeneity, to summarize the characteristics of existing federated learning and analyze its current applications.
Various market research institutions and experts predict that the development trend of such augmentation technologies will move towards human augmentation in the future. Yole Développement depicts a path towards augmented intelligence in Figure 11. Similar to humans, in machines, the main areas of intelligence augmentation include audio, visual, olfactory, and motion sensing. Since the advent of personal computers (PCs) in the 1990s, intelligence has been embedded in machines. Graphics cards and Graphics Processing Units (GPUs) have become more advanced, turning mobile phones into smartphones. Deep learning algorithms and efficient hardware have facilitated the development of intelligent assistants like Siri, Alexa, and Cortana. Meanwhile, there has been development in Internet Protocol (IP) surveillance cameras, virtual personal assistants, smart wearables (such as smartwatches), etc. After the emergence of system-on-chip-based neural processing units in 2017, AI has been integrated into electronic devices, making them more intelligent. In 2020, we witnessed smart cameras, more powerful augmented virtual personal assistants, smart wearables with attractive features, and smarter consumer products, electronic devices, smart homes, and more. Soon, we will witness more intelligent products, such as companion robots, smart homes, electronic sniffers for odor recognition, and so on. By 2040, it is expected that humans themselves will achieve intelligent augmentation, i.e., not the simple robots currently displayed, but "augmented humans."
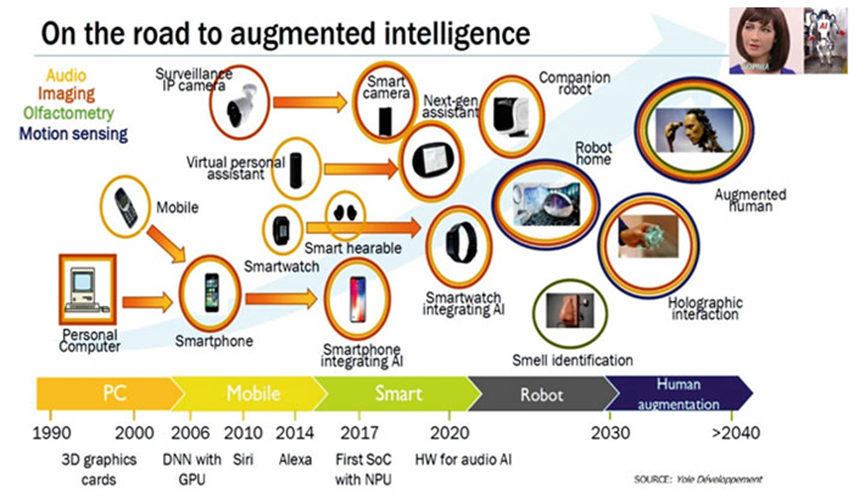
Figure 11: Roadmap for Augmented Intelligence
Such tremendous development is reflected in the integration of efficient AI algorithms with compatible AI hardware. However, there is still a demand for the continuous expansion of future research areas (AI algorithms and hardware). Figure 12 illustrates this demand for AI algorithms and hardware in training and inference.
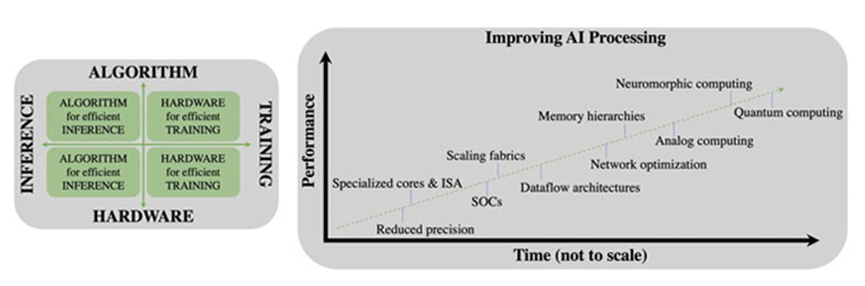
Figure 12: Demand for AI Algorithms and AI Accelerators in Training and Inference
Scalable architectures, memory hierarchies, dataflow architectures, and network optimizations are recent research areas in AI. Neural computing, analog computing, and quantum computing are emerging as research directions for future AI processing.
References:
1. Ashutosh Mishra, Jaekwang Cha, Hyunbin Park, Shiho Kim. Artificial Intelligence and Hardware Accelerators
--
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





