Demystifying the Rankings: Do High Scores in Robotics Competitions Equate to Real-world Implementation Strength?
 05/27 2026
05/27 2026
 664
664

Author|Mao Xinru
Today's embodied AI industry is trapped in a peculiar Schrödinger-like state.
Nearly every company talks about model capabilities, generalization abilities, and algorithm implementation, but if you ask how strong they really are, few can provide a convincing answer.
The reason is simple: the industry lacks a common measuring stick.
Without unified standards, everyone can only compete on storytelling.
You can showcase a robot performing a flawless operation in a controlled environment and create an impressive video.
But behind that video, no one knows how many times the robot can repeat the task in other scenarios, whether it remains effective in different settings, or if it can handle different tasks.
The industry remains in a state where everyone claims to be strong, but no one can clearly articulate where that strength lies.
Thus, third-party evaluation rankings have become a reference point.
Some view rankings as a badge of competence, while others dismiss them as shallow, one-sided, and overly inflated.
Both sides have their reasons.
This reflects a deeper issue: the industry lacks a universally accepted measuring stick, leading to endless debates.
Excellent technological achievements should withstand the scrutiny of public evaluations. Objective competition results are the fairest proof of technical strength.
In the current landscape of missing standards and chaotic evaluation systems in the embodied AI industry, viewing rankings objectively may be the rational attitude the industry needs most right now.

Rankings are not the finish line but a tool for dissecting capabilities
The controversy surrounding rankings stems from long-standing evaluation chaos.
In recent years, numerous low-threshold evaluation rankings have emerged, with some plagued by issues like non-transparent standards, single-dimensional tasks, excessive reliance on simulated scenarios, and ample room for manipulation.
Many models' high scores are merely performative achievements in controlled settings, unable to be replicated in real, complex environments. This has led to a widespread perception that rankings are watered down and high scores are merely for show, even giving rise to two extreme viewpoints: ranking obsession and ranking dismissal.
To clarify the true value of rankings, we must first escape the trap of binary opposition.
Rankings are not the ultimate verdict on a model's capabilities, nor do they represent the entirety of a company's technical strength. Instead, they serve as a Periodic reference scale (phased reference benchmark) for technological iteration before the embodied AI industry's standardized system takes shape.
High-quality, authoritative rankings hold irreplaceable positive value for the industry and are a core driving force for helping the industry move beyond extensive development in phases.
What makes a ranking high-quality and authoritative?
From a broad industry perspective, five criteria must be met:
Real-world testing, not just for show: High simulation scores are no substitute for real-world success
Comprehensive dimensions, covering general capabilities: A single skill doesn't tell the whole story
Transparent rules, with reproducible results: Transparency builds credibility
Evolving standards, adapting to technological progress: Evaluation must not remain static
Realistic scenarios, with industrial implementation guidance: Rankings should also consider commercial viability
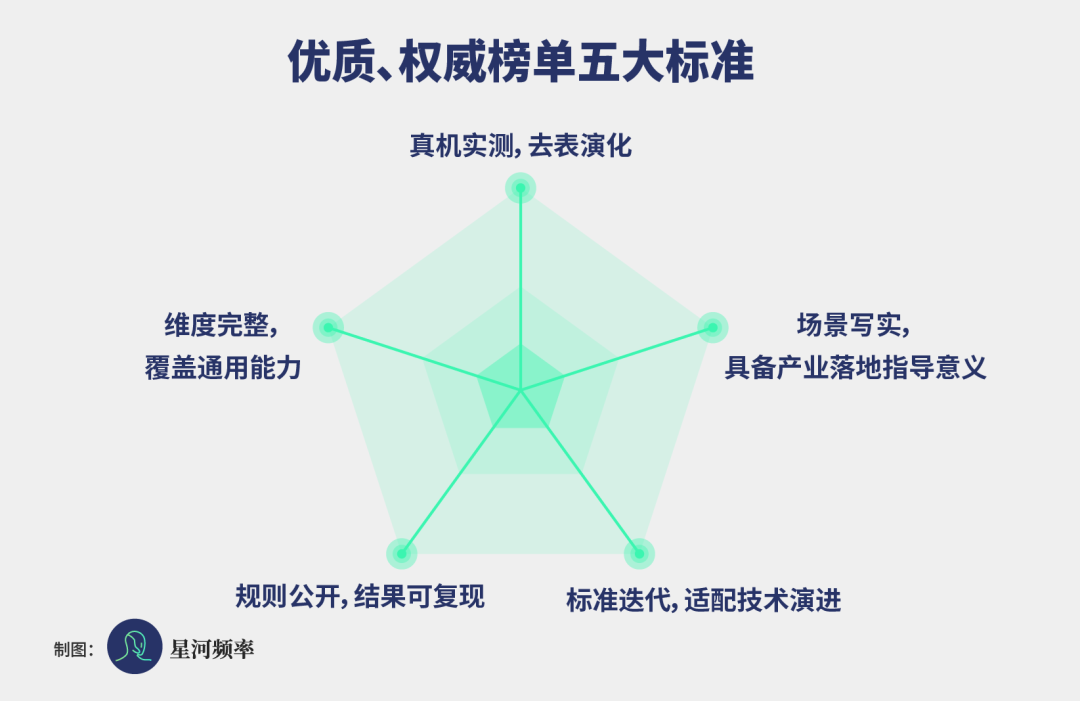
Among these five criteria, real-world testing is the most critical, serving as the dividing line between performative and practical intelligence.
From an industry development perspective, mainstream authoritative rankings can establish a foundational framework for quantifying and comparing embodied models.
In the absence of unified industry-wide benchmarks, evaluating model performance has historically relied on corporate demos, technical presentations, and subjective judgments, lacking quantitative basis and unified dimensions, resulting in vague and one-sided evaluations.
International professional rankings like WorldArena, Benjie's Olympics, Robochallenge, RoboTwin 2.0, MolmoSpaces, and LIBERO provide a globally recognized evaluation matrix by breaking down abstract intelligence capabilities into quantifiable, comparable, and reviewable metrics through standardized, transparent evaluation tasks.

At the same time, they drive optimization of the industry's subjective evaluation models, offering visual references for research iteration, technical competition, and product selection, helping to reduce arbitrariness in subjective judgments.
From a technological iteration perspective, high-quality rankings continuously raise industry evaluation thresholds, pushing technology away from performative displays and toward practical effectiveness.
Quality rankings focus on complex real-world tasks, rejecting low-difficulty, routine scenarios, and instead emphasizing real-world interaction, testing core capabilities like fine-grained control, long-term decision-making, complex environment generalization, and dynamic closed-loop control.
From a research and development perspective, vast amounts of evaluation data from rankings also serve as a core support for addressing technological shortcomings in the industry.
Regular evaluations by authoritative rankings accumulate diverse task test samples and model operation data, Intuitive exposure (visibly exposing) current models' technological shortcomings in environmental reasoning, fine manipulation, and multi-task adaptation, while providing data references for clarifying research directions, optimizing model architectures, and iterating general capabilities.
Moreover, the participation choices of industry-leading companies indirectly validate the technical reference value of high-quality rankings.
Take Physical Intelligence as an example: as a global leader in embodied AI brains, it rarely participates in industry evaluations, yet Benjie's Olympics is the only ranking it actively joins.
PI entered its highest-performing closed-source model, π*0.6, in the competition, primarily because it recognized Benjie's Olympics' evaluation logic of de-emphasizing performance and focusing on real-world practicality.
PI also aimed to validate the model's fine manipulation and long-sequence task execution capabilities through challenging real-world tasks.

This demonstrates that high-quality rankings serve as a crucial testing ground for leading companies to validate their core technologies.
Meanwhile, the competitive landscape of industry rankings continues to evolve, with top rankings like WorldArena seeing frequent leadership changes—over a dozen times in three months. This dynamic turnover reflects the rapid development of the embodied AI industry.
Frequent leadership changes indicate that no single company can permanently monopolize the track (track) based on Periodic advantage (phased advantages). Only foundational, universally applicable hardcore technologies can adapt to continuously upgrading evaluation standards and maintain a leading position in the industry over the long term.
In summary, rankings are not the ultimate standard for judging model quality but represent the fairest and most effective phased evaluation tool before industry standardization is achieved.
By abandoning polarized perceptions and viewing rankings objectively, we can better understand the true logic of technological iteration in embodied AI.

Rankings are becoming a 'wind vane' for technological iteration
Since rankings serve as phased benchmarks for industry technology, we must first understand the current competitive landscape of rankings.
With rapid technological iteration in embodied AI, the industry has moved beyond relying on demos for storytelling. Quantifying technical strength through authoritative rankings has become a consensus among many leading companies.
Rankings themselves are becoming a mirror reflecting the industry's phased technical capabilities, making it clear at a glance which companies are truly skilled and which are merely bluffing.
Take the five mainstream rankings with high industry recognition and participation as examples: each evaluates different core capabilities of models, covering a complete system from environmental understanding, fine manipulation, multi-task generalization, to long-sequence transfer.
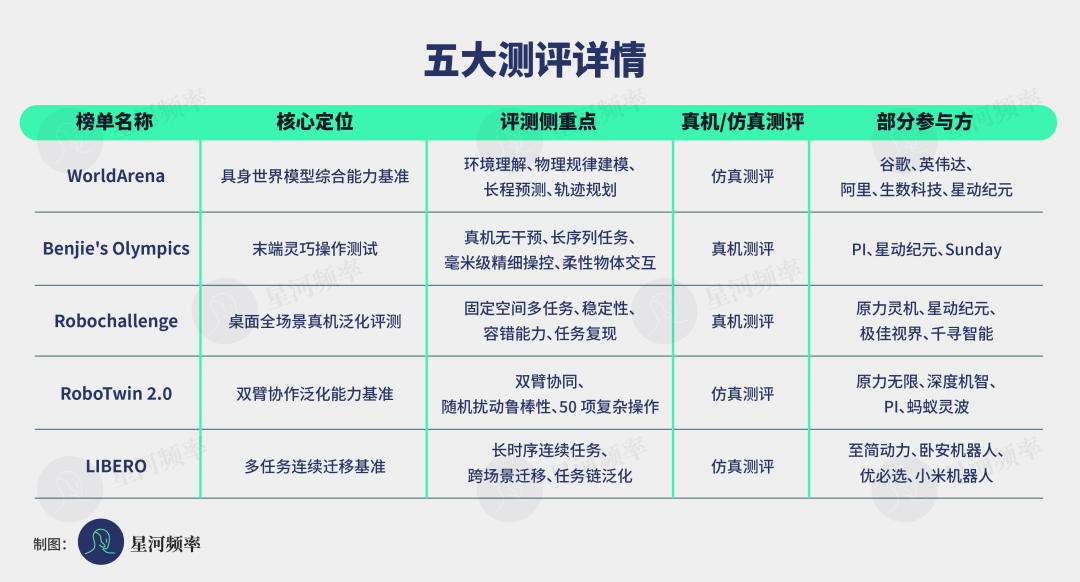
Among them, WorldArena emphasizes a model's world modeling and reasoning capabilities, focusing on testing a robot's understanding and prediction of real-world structures, physical laws, and dynamic changes—a core metric for verifying a robot's comprehension of the real world.
Benjie's Olympics prioritizes dexterous real-world manipulation, focusing on fine interaction tasks that are extremely challenging for robots yet common in human daily life, with zero human intervention and no simulation tolerance, specifically examining a model's long-sequence practical operation and fine control capabilities.
Additionally, RoboChallenge, as a real-world operation competition, emphasizes full-scenario, normalized multi-task generalization on desktops, core examining equipment stability, fault tolerance, and continuous reproducibility in fixed spaces, closer to daily and industrial practical scenarios.
RoboTwin 2.0 focuses on dual-arm collaborative operation capabilities, testing a model's operational robustness and complex task adaptation under random disturbances.
LIBERO emphasizes long-sequence continuous task transfer, core measuring a model's task chain understanding and cross-scenario generalization capabilities.
Five rankings, five distinct perspectives.
Some test thinking, some test movement, some test stability, and some test collaboration.
Together, they form the most intensive model capability testing ground in today's embodied AI industry.
Intense competition among rankings has also accelerated technological iteration in the industry.
Besides WorldArena, mainstream rankings like Benjie's Olympics, RoboChallenge, and LIBERO remain in a state of dynamic competition.
An increasing number of domestic and international leading companies and research teams are participating intensively, continuously breaking world records across various tasks. Ranking competition has evolved from early dominance by a few players to a fierce, multi-player contest.
Take WorldArena as an example: its participant lineup has expanded from a dozen early models to 40 competing simultaneously, with over ten domestic companies surpassing NVIDIA and Google in total scores.
Benjie's Olympics has also attracted challenges from players like Sunday Robotics.
On RoboChallenge's leaderboard, over 20 players with public scores now compete, with its international ecosystem expanding from China to the global stage.
The RoboTwin 2.0 ranking has also seen fierce competition, with teams like Shengshu Technology and Yuanli Infinite taking turns at the top.

Among publicly recorded ranking participants, Xingdong Era is the only company to have secured first place across three top rankings with entirely different dimensions: WorldArena, Benjie's Olympics, and RoboChallenge.
The significance of this uniqueness lies in:
WorldArena tests understanding and reasoning in virtual worlds, Benjie's Olympics tests fine manipulation in real physical environments, and RoboChallenge tests stable execution in structured scenarios.
These three dimensions have virtually no overlap, and achieving top rankings simultaneously demonstrates the universality and robustness of the underlying capabilities.
Beyond this individual case, the phenomenon of a company winning multiple authoritative model rankings may become a new reference standard for measuring technological capabilities in the industry.
Previously, industry judgments of model capabilities often relied on performance in a single ranking or specific task, easily leading to cognitive biases where specialization in one area was mistaken for overall excellence.
However, when a company's model achieves top rankings across multiple evaluations with non-overlapping dimensions, it sends a different signal.
It indicates that the technological system possesses cross-task and cross-scenario capability transferability, rather than being merely optimized for specific question types.
In this sense, simultaneous top rankings across multiple rankings are evolving into a new paradigm for evaluating technological capabilities.
It does not rely on a single examination to determine success but assesses a model's true universal strength through cross-validation across different dimensions, scenarios, and task systems.
After all, true general intelligence is not confined to a single scenario, task, or evaluation system but achieves comprehensive capability coverage.

Rankings are the gateway; implementation is the exit
There is no doubt that high-quality rankings can objectively verify a model's phased capability ceilings. Achieving top positions across multiple high-quality, authoritative rankings with distinct dimensions provides strong evidence of a model's technical depth and universal capabilities.
However, rankings ultimately represent capability validation in laboratory and evaluation settings. No matter how impressive the scores, they must withstand the test of real industrial scenarios. The industry's ultimate focus remains consistent: whether robots can truly perform tasks, integrate into business operations, and operate stably in factories.
This has become the most critical watershed in the embodied AI industry by 2026: the ability to perform tasks effectively is replacing flashy technology as the new focus of industry competition.
The industry is responding to this question in different ways.
Not long ago, Figure AI launched a live logistics sorting demonstration on social media, where three Figure 03 robots continuously operated for over 200 hours in a self-built standardized environment, sorting nearly 250,000 packages in total.
This live demonstration aimed to address two core doubts: whether Figure AI's model can truly be put to practical use and whether the robots can maintain stable long-term operation.
Prior to Figure AI's high-profile live demonstration, Zhiyuan Robotics, in collaboration with Longcheer Technology, completed an eight-hour live demonstration of real-world operations on a 3C precision manufacturing line.
At Longcheer Technology's factory, Zhiyuan's Elf G2 robot completed tasks such as tablet grasping and transportation, equipment docking for testing, and retrieval and repositioning after testing. The robot performed a total of 2,283 operations with a success rate exceeding 99.5%.
This validated another dimension: whether robots can enter high-precision, high-demand industrial production lines.
Similarly opting for logistics scenarios but differing from Figure AI, Xingdong Era chose to directly deploy its model in real logistics environments for testing.
It has established partnerships with leading logistics companies such as China Post and SF Group, operating routinely in over ten logistics centers across multiple provinces and cities nationwide, handling tasks such as sorting and feeding packages, scanning codes, and identifying exceptional items.
These three approaches are not superior or inferior to one another; essentially, they all aim to answer the same question: how to prove that robots can truly perform tasks.
Live demonstrations, long-duration operation, real orders, and factory integration are all validation methods being explored by the industry.
Each method has its applicable scenarios and Periodic significance (phased significance).
Live demonstrations in standardized environments can intuitively showcase stability, real production lines can validate scenario adaptability, and direct entry into real logistics networks can test the model's tolerance for uncertainty.
However, regardless of the path taken, they all ultimately point in the same direction: moving models out of the laboratory and making the real effects visible to the public.
Meanwhile, Morgan Stanley's 2026 report on humanoid robots clearly points out that the most certain and easily scalable near-to-medium-term applications lie in B-end rigid demand (rigid demand) scenarios such as industrial manufacturing, warehousing and logistics, and high-precision inspections.
These scenarios involve repetitive, arduous, and high-risk tasks, where the value of robotic replacement is clear, and ROI is most quantifiable, making them core breakthroughs for industry commercialization.

Against this backdrop, rankings serve as an "entrance exam" for capabilities, while real-world deployment acts as the "final thesis defense" for capabilities.
While it is important for a model to score highly, the industry's true question is whether it can stably deliver and continuously create value in real-world scenarios.
The current embodied AI industry is at a new stage calling for scalable applications.
At this stage, what the industry needs is not a champion in a single dimension but players who can continuously prove themselves across the complete chain of rankings-models-deployment.
Rankings dissect capabilities, models integrate capabilities, and deployment validates capabilities—these three aspects often operate independently in the industry.
Companies that excel in rankings may not necessarily succeed in deployment, companies that can deploy may not have a general-purpose brain, and companies with a general-purpose brain may not withstand public scrutiny.
Only players who can connect these three aspects truly have the opportunity to define the future of the industry.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





