The Competition of Autonomous Driving Technology Escalates: What Comes After VLA?
 05/29 2026
05/29 2026
 571
571
In 2026, the logic of intense competition in the autonomous driving industry is undergoing its third major restructuring.
In just a few years, the industry has rapidly progressed through two stages: the hardware arms race and end-to-end algorithm competition. New energy vehicle manufacturers like XPeng and Li Auto, along with traditional automakers such as Geely and Great Wall Motors, have flocked to the VLA (Vision-Language-Action) model, making it one of the key schools of thought in the current iteration of autonomous driving technology.
With its trinity architecture of "visual perception + language reasoning + action output," VLA addresses the biggest pain point of traditional autonomous driving: understanding road conditions without grasping their underlying logic. However, VLA's drawbacks are also evident. Relying on language models for reasoning requires two translations—from vision to language and from language to action—each introducing errors and slowing response times.
The ruthlessness of industry competition lies in "just catching up with the mainstream when a new iteration arrives." While some manufacturers are still refining VLA for mass production and optimizing reasoning speed and scenario generalization capabilities, players like Huawei and Xiaomi argue that VLA is not the ultimate form of autonomous driving but merely a transitional technology on the path from assisted driving to fully autonomous driving. The real competition in the second half has already shifted to the next technological paradigm after VLA.

To understand the limitations and future directions of VLA, one must first clarify the iterative logic of autonomous driving's three generations of technological paradigms over the past decade. Each iteration represents a complete overhaul of the previous generation's shortcomings.
The first generation was the rule-driven era, representing the most primitive form of autonomous driving. Early autonomous driving relied entirely on engineers hand-writing millions of lines of C++ code, using preset fixed rules to handle various road conditions. The system's core logic was "matching rules and mechanical execution," offering stability, controllability, and strong interpretability but extreme rigidity. Faced with unanticipated emergency scenarios, abnormal road conditions, or mixed traffic, the system would fail to make decisions, unable to adapt to complex real-world road conditions. This was the core reason why early assisted driving was limited to highway cruising.
The second generation was the end-to-end AI era, marked by Tesla's FSD V12 as the starting point. The industry completely abandoned modular decomposition and manual rule-stacking, adopting a full neural network architecture of "pixel input, action output" trained on massive real-world road data, allowing AI to autonomously learn driving decisions. This generation solved the rigidity and slow iteration problems of traditional rule-based algorithms, significantly improving driving smoothness and scenario adaptability. However, it also had a fatal flaw: it possessed perception capabilities but lacked understanding. AI could identify obstacles and lane markings but failed to grasp the logic behind scenes or understand traffic common sense, leading to frequent issues like "recognition but misjudgment, clumsy evasion, and unreasonable decisions."
The third generation is the current VLA era, the mainstream form of the autonomous driving industry in the past two years. Building on end-to-end visual architectures, VLA incorporates natural language reasoning capabilities, forming a complete closed loop of "visual perception of the world, linguistic understanding of logic, and action output for decision-making." Unlike pure visual end-to-end models' "intuitive decision-making," VLA can, like human drivers, first identify road conditions, then understand the scene, and finally formulate driving strategies, perfectly adapting to high-frequency complex scenarios such as urban intersections, mixed pedestrian-vehicle traffic, and temporary construction zones, making high-level mapless intelligent driving genuinely practical for mass production.

VLA is essentially an end-to-end intelligent system that integrates multimodal perception, high-level logical reasoning, and low-level action execution through a unified neural network. Its core value lies in aligning the previously independent perception module (seeing), logical module (thinking), and execution module (doing) within the same semantic space. Compared to traditional autonomous driving systems, VLA not only recognizes pixels or geometric structures in the environment but also understands the semantic logic behind these signals.
The VLA model consists of three core components: a visual encoder, a large language model (LLM) backbone network, and an action decoder. The visual encoder transforms multi-view images captured by cameras into high-dimensional feature vectors containing spatial layouts and object characteristics of the environment. The LLM backbone network, serving as the decision-making center, logically processes these visual features using vast world knowledge accumulated during pre-training. The action decoder then converts these abstract reasoning results into specific physical actions such as steering angles and acceleration/deceleration values.
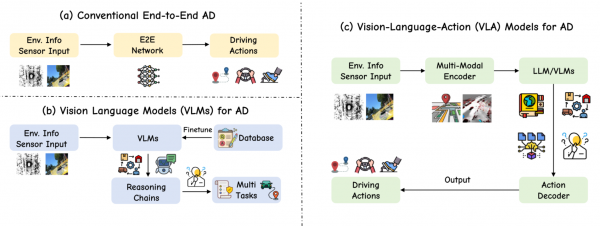
This integrated mapping approach enables the system to handle driving tasks in a manner closer to human cognition. During human driving, the brain does not first mark the precise coordinates of every pedestrian before calculating but directly produces evasive actions based on an overall understanding of the scene (e.g., "this pedestrian might cross the road"). The VLA model, through a shared Transformer architecture, collaboratively encodes language, vision, and action modalities, constructing a unified semantic space and achieving seamless integration from perceptual understanding to action decision-making.
After three years of iteration, VLA has completely rewritten the industry landscape, narrowing the algorithmic gap between small and medium-sized manufacturers. Today, mainstream automakers' VLA systems perform similarly on regular urban roads and highways, with minimal differences in daily driving smoothness and scenario coverage. This homogenization implies that VLA's technological dividends have peaked, and the industry urgently needs new technological breakthroughs.
While public opinion widely regards VLA as the optimal solution for autonomous driving, frontline technical teams and industry experts see it as inherently flawed from birth. These shortcomings cannot be fully resolved through model fine-tuning, data increments, or computational upgrades, which is why VLA is destined to remain a transitional technology.
First is the lack of temporal logic and weak spatial scene reasoning capabilities. Most current VLA models excel at single-frame, instantaneous road condition analysis but fall short in predicting continuous temporal logic for traffic flow changes, pedestrian movement trajectories, and multi-vehicle interactions. Faced with high-speed dynamic scenarios like sudden pedestrian appearances, close-quarters cut-ins, or abrupt lane changes, VLA lacks sensitive perception, often exhibiting decision delays and misjudgments, unable to achieve human-like "proactive anticipation and active risk avoidance."
Second is the high computational cost and difficulty in adapting real-time performance to in-vehicle scenarios. VLA integrates three modules—vision, language, and action—resulting in a massive model parameter count and far higher reasoning computational demands than traditional end-to-end algorithms. Vehicle electronic control systems require decision response speeds of up to 100Hz, while generic VLA language reasoning speeds typically fall below 10Hz. This vast computational gap necessitates significant model simplification for onboard deployment. Even if some manufacturers optimize reasoning pathways to reduce latency to under 80 milliseconds, they cannot fully resolve the conflict between intelligence level and speed, and high computational costs significantly raise the mass production threshold for high-level autonomous driving.
Third is the lack of physical world common sense and failure in long-tail scenario generalization. VLA's learning logic relies on massive data fitting rather than true understanding of physical laws. It can learn to avoid conventional obstacles through training but cannot autonomously reason about physical common sense like "puddles are slippery and require slowing down," "hanging branches might fall and require detouring," or "reduced road friction in rain or snow requires longer braking distances." For such rare long-tail scenarios, data cannot fully cover them, leading to frequent VLA decision errors. The safety bottom line of autonomous driving is precisely determined by these long-tail extreme scenarios.
Finally, there is cross-modal alignment bias and insufficient decision stability. The three major modules—vision, language, and action—inherently suffer from linkage losses, with visual perception biases, language reasoning errors, and action output deviations accumulating layer by layer. In visually constrained scenarios like backlighting, dense fog, or low light, VLA may experience disconnections between semantic understanding and actual road conditions, resulting in bizarre decisions like "correct recognition but incorrect understanding and action deviations," causing minor issues like driving jerks and route deviations or major safety incidents. This is an inherent physical limitation of pure visual VLA solutions.
In summary, while VLA has solved the intelligence problem of autonomous driving, it has not addressed safety, real-time performance, and generality issues, which is the core motivation for the industry to break through VLA and explore next-generation technologies.
Standing at the 2026 technological crossroads, leading manufacturers are moving beyond VLA's modal fusion thinking toward physical world intelligent modeling. While VLA focuses on seeing, understanding, and acting, the next generation of autonomous driving technology emphasizes grasping laws, reasoning, and predicting. Currently, the industry has identified four mainstream iterative directions.
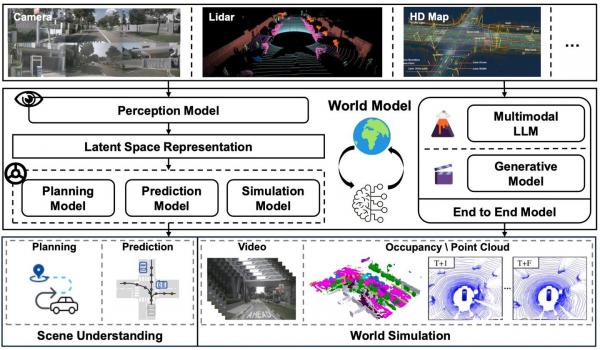
First, multimodal physical world models will become the core foundation of next-generation technology. World models represent the optimal solution to VLA's lack of physical common sense and are a key focus for Tesla and Huawei. Unlike VLA, which relies on data to fit scenarios, world models autonomously learn the physical rules, traffic patterns, and motion logic of the real world, constructing a complete virtual road condition world. Faced with unseen long-tail scenarios, they can autonomously deduce optimal decisions based on physical common sense without massive data training, truly achieving "learning by analogy." In short, while VLA "acts based on seeing," world models "act based on understanding principles," fundamentally solving the industry's long-tail scenario failure problem and serving as the core foundation for fully autonomous driving.
Second, temporal embodied intelligence architectures will address dynamic decision-making shortcomings. To overcome VLA's weak temporal reasoning, next-generation technology will significantly enhance continuous scenario modeling capabilities, abandoning single-frame static reasoning for a temporal memory and dynamic reasoning system. The system can record past road condition information in real-time and predict future 3-5 second traffic and pedestrian flow dynamics, achieving full-temporal decision-making across "past-present-future" and aligning with human drivers' thinking, resolving decision-making challenges in high-speed dynamic risk avoidance, complex traffic interactions, and multi-agent game theory at intersections, significantly improving driving safety and smoothness in high-speed and urban congestion scenarios.
Third, neurosymbolic fusion will balance intelligence and interpretability. Current VLA models are pure black-box AI with unexplainable decision-making logic, posing safety regulatory risks and struggling to meet compliance requirements for autonomous driving deployment. Next-generation neurosymbolic fusion technology combines AI deep learning's intuitive advantages with symbolic logic's rule advantages. AI handles real-time scene perception and rapid decision-making, while symbolic logic enforces constraints on traffic rules, physical common sense, and safety baselines. This retains the extreme intelligence of large models while resolving black-box decision-making uncontrollability, ensuring logical traceability for every brake, lane change, and detour, meeting high-level autonomous driving's safety compliance requirements.
Fourth, lightweight universal autonomous driving platforms will enable affordable mass production. VLA's high computational costs severely limit the popularize of high-level autonomous driving. Next-generation technology will rely on model distillation, operator optimization, and edge computing reconstruction to create lightweight universal autonomous driving platforms that significantly reduce computational demands while retaining top-tier decision-making capabilities, eliminating reliance on ultra-high computational hardware. Simultaneously, it will support multi-sensor fusion architectures, prioritizing vision with radar assistance, balancing low cost and high safety redundancy, resolving the pain point of high-level autonomous driving being limited to high-end models, and promoting the full sink of fully autonomous driving to mid-range mass-produced vehicles.
The window for technological iteration is always short. Leading domestic and foreign manufacturers have already begun racing toward next-generation technology, pre-emptively layout the post-VLA technological track, launching a new round of industry rankings.
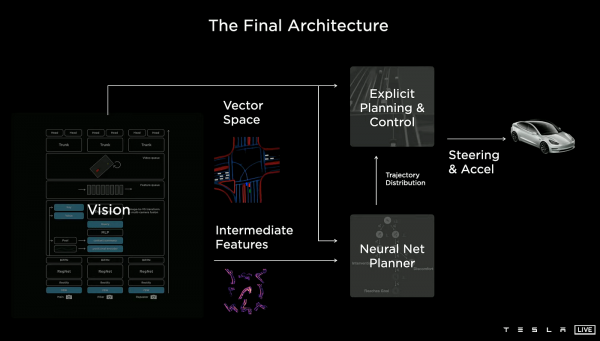
Tesla, as the industry's technological bellwether, is advancing an end-to-end temporal neural network fused with a neural world simulator, with core reasoning still based on end-to-end and supplemented by cloud-based closed-loop simulation. Unlike VLA, Tesla does not use large language models for semantic reasoning but adheres to a "pure vision end-to-end + physical simulation training" route.
FSD employs a "multimodal (camera + IMU + navigation + audio) input → temporal Transformer/occupancy network → direct control signal output" one-stage end-to-end architecture, not the traditional "perception-planning-control" cascade. This structure enables temporal modeling and can be viewed as an "end-to-end temporal network." The Neural World Simulator generates future states in the cloud (given current state + action → predict next frame scene), supporting closed-loop training, long-tail scenario synthesis, and reinforcement learning.
In April, Huawei introduced the WEWA 2.0 architecture, comprising two core parts: the cloud-based World Engine (WE) and the vehicle-based World Behavior Model (WA). The cloud side incorporates a multi-agent game theory mechanism and online reinforcement learning, enabling real-time interaction with the environment for a "generate-learn-verify" workflow. On the vehicle side, the architecture centers on the Safety Risk Field Theory and the Driving Agent module, assessing real-time risks by quantifying kinetic, potential, and behavioral fields and generating risk heatmaps to aid decision-making. The Driving Agent module supports autonomous strategy optimization for travel tasks, enhancing complex scenario response and defensive driving capabilities.
XPeng and Li Auto focus on mass production optimization, taking differentiated iterative paths. XPeng made a bold choice with its second-generation VLA—removing the language layer. Adopting a "vision → implicit Token → action" architecture, it completely abandons explicit language translation, allowing visual signals to directly generate continuous driving actions, minimizing reasoning latency while deploying a virtual-real data closed loop to address long-tail scenario shortcomings through virtual scene training. Li Auto introduced the Mind VLA-01 architecture, specifically addressing VLA's three-dimensional spatial alignment biases, strengthening adaptability to abnormal road conditions and complex underground parking scenarios while pursuing model lightweighting for ultimate mass production cost-effectiveness.
In March, Xiaomi Automobile unveiled the XLA cognitive large model, emphasizing modality support, efficiency, and controllability. The "X" in its name signifies native support for multimodal data input, integrating lidar, vision, navigation, sound, and robotic data. XLA employs latent space reasoning technology to balance low system latency and reasoning capabilities while maintaining interpretability and traceability in the reasoning process. Based on the Xiaomi MiMo-Embodied embodied foundation large model, it fuses VLA and world model architectures, achieving an upgrade from data-driven to cognition-driven, and is named XLA instead of VLA due to its native support for richer multimodal data inputs.
In terms of autonomous driving companies, Pony.ai's PonyWorld 2.0, WeRide's general simulation model WeRide GENESIS, and Mogo Auto's multi-modal large model for the physical world, MogoMind, all fall under the category of world models. Fundamentally, a world model is a capability framework that 'understands the physical world and interacts with it in a virtual environment.' Its core capabilities primarily consist of two aspects: first, digitally modeling and abstracting the physical world; second, based on such modeling, generating reasonable imagination and predictions about the physical world, such as predicting how the world will change in the future through given images.
Based on world models, autonomous driving companies can generate required scenarios without limitations from various dimensions during cloud-based simulation training. They can produce videos as training data according to instructions, leading to a generational leap in model iteration speed. After mature implementation in autonomous driving, world models have the opportunity to further explore other physical AI applications, such as complex robot control and automated logistics systems.
Overall, the industry landscape has become clear: second-tier manufacturers are still fully implementing VLA and catching up with the mainstream; first-tier leading manufacturers have already mastered VLA technology and are preemptively deploying the next generation of world models and embodied intelligence. Over the next two years, the gap in autonomous driving capabilities among automakers will no longer be determined by VLA capabilities but by the speed of implementing the next generation of physical intelligence technologies.
From rule-based algorithms to end-to-end systems, from VLA large models to intelligence in the physical world, the iterative logic of autonomous driving has always been clear: reducing reliance on manual intervention, enhancing general capabilities, and narrowing the gap between humans and machines. As a key transitional technology, VLA supports the leap of autonomous driving from 'mechanical assistance' to 'human-like intelligence,' but its structural shortcomings destined (zhùdìng, 'are destined to') prevent it from supporting the implementation of fully autonomous Level 4 driving.
Over the next 2-3 years, with the further development of VLA and world models, autonomous driving will undergo three disruptive changes:
First, there will be a qualitative improvement in safety fallback capabilities, addressing the failure issues in long-tail extreme scenarios, truly achieving reliable all-weather and all-scenario driving, and eliminating core safety hazards in autonomous driving.
Second, it will completely eliminate reliance on data, eliminating the need for massive scenario coverage, and relying on physical common sense to autonomously adapt to various unknown road conditions, solving the adaptation challenges across different cities and road conditions.
Third, costs will significantly decrease, with lightweight model architectures lowering hardware requirements. High-level fully autonomous driving will transition from being standard in high-end luxury vehicles to being available in affordable family cars priced around 100,000 yuan, achieving universal accessibility.
At the same time, industry competition will completely move away from 'parameter inflation and feature stacking,' returning to core capabilities such as physical modeling, temporal reasoning, and safety controllability. Manufacturers that simply follow trends by stacking large models and replicating VLA functions will gradually be eliminated from the market. Only companies that truly master core underlying algorithms and physical intelligence technologies will have the opportunity to secure passage to the next stage.
No technology race offers eternal technological dividends; only continuous underlying innovation does. The widespread adoption of VLA has freed the industry from low-level hardware and rule-based competition, truly ushering in the era of AI-driven intelligent driving. After VLA, autonomous driving will no longer be just a 'machine that can drive' but a vehicle-mounted intelligent agent that understands road conditions, physics, rules, and can make predictions. This round of iteration goes far beyond algorithms themselves; it represents the ultimate leap of autonomous driving from being 'used by humans' to 'coexisting with humans.'
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





