Xiaomi MiMo’s 99% Price Reduction: More Than Hype—Luo Fuli’s X Post Silences Doubters
 06/01 2026
06/01 2026
 603
603
Setting aside the specifics of this incident, it has reignited a critical question: Why does Doubao keep trending due to similar controversies?
Luo Fuli took to X to address the controversy surrounding Xiaomi MiMo’s dramatic price cut.
On May 26, the official Xiaomi MiMo account announced on X that the MiMo-V2.5 series API would undergo a permanent price reduction, with discounts of up to 99%. Pricing would be standardized across all context lengths, while Token packages would see a 5-8x upgrade.
The announcement sparked a week-long debate in China’s AI community. Initial reactions split into two main camps. The largest group dismissed it as “just another price war”—a trend over the past two years where domestic AI leaders like Zhipu, DeepSeek, ByteDance’s Doubao, and Alibaba’s Tongyi have taken turns slashing prices to avoid falling behind.
The other camp was more skeptical: Xiaomi had just reported a 50% annual profit decline, yet it was investing 60 billion yuan into AI while cutting API prices by 90%—a classic “cash burn” strategy to capture market share. Some saw it as an extension of the DeepSeek effect, which had dragged industry pricing to rock bottom, forcing competitors to follow suit or risk obsolescence.
In response, Luo Fuli, head of MiMo, published a 5,000-word technical blog last night, detailing the engineering innovations behind the price cut.
“This is real engineering, not marketing,” he declared.
To understand Luo’s argument, we must first clarify where the 99% discount applies.
It’s not a blanket cut across all model services. The 99% reduction targets a specific pricing tier: Input (Cache Hit)—when users repeatedly access historical context in long conversations. Ordinary new inputs (No Cache Hit) see smaller discounts, while model outputs (Output) see the least reduction.
Think of it like a coffee shop:
If you order the same half-sweet latte daily, the shop has two options: make it fresh each time (incurring ingredient and labor costs) or brew a large batch upfront and store it in the fridge, serving you from the pre-made stock. MiMo chose the latter—replacing “on-the-fly calculation” with “on-the-fly retrieval” for repeated user inputs, slashing costs for this portion to near-zero and enabling the 99% discount.
Achieving this required six engineering breakthroughs, each critical. Let’s break them down.
Engineering Improvement 1: Shrinking the model’s “memory” to 1/7
When interacting with you, the model computes an “intermediate state” for each token and stores it for the next step—this is KVCache, akin to the model’s “short-term memory notebook.” For every sentence you speak, the model jots down a summary, allowing it to reference notes instead of reprocessing everything from scratch.
Traditional models use “Full Attention” at every layer, meaning each token reviews all tokens in the conversation, causing the notebook to balloon with each exchange. MiMo-V2.5-Pro restructured its architecture: out of 70 layers, 60 focus only on the most recent 128 tokens (SWA, Sliding Window Attention), while just 10 layers (“archivists”) review the full history.
Result: KVCache volume and computational load drop to 1/7 of Full Attention.
To illustrate, imagine a company originally required every employee to memorize all meeting records, leading to mental overload. The new rule reduces the cognitive burden for 60 employees to 1/7, leaving only 10 archivists to manage the full history—efficiency increases sevenfold without sacrificing memory capacity.
Engineering Improvement 2: Actually utilizing the space saved by SWA
Architecturally reducing the notebook size to 1/7 was the first step, but translating “theoretical 1/7” into “actual 1/7” required another breakthrough.
Traditional KVCache systems allocate video memory uniformly across all layers based on “maximum possible usage.” This means even if 60 SWA layers only need a small notebook, the system allocates space as if they were “archivists” with large notebooks—wasting the space saved by SWA.
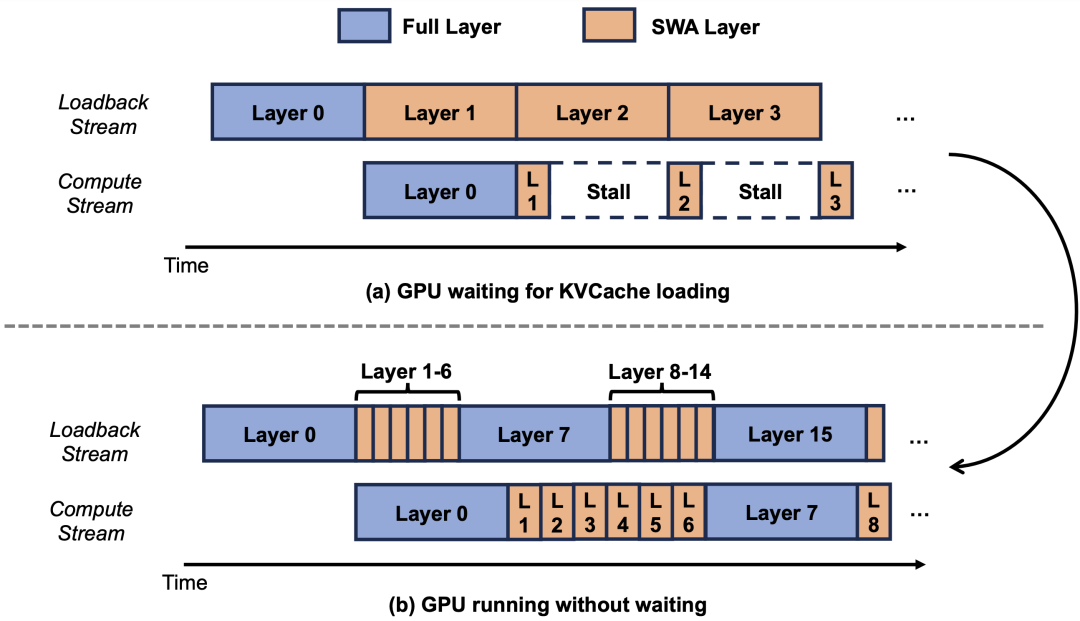
Luo’s team fixed this by splitting KVCache into two independent pools. The 10 Full Attention layers use a “large pool” for full context; the 60 SWA layers use a “small pool” for just the 128-token window.
Imagine a company originally gave every employee a “filing cabinet for 100 years of documents”—but 60 employees only needed “a small cabinet for one week of files,” leaving 99% of the space empty. The new approach allocates cabinets based on actual needs, allowing five times more colleagues to work in the same office—a single GPU can now serve five times more concurrent users.
Without this step, the advantages of SWA would be wasted.
Engineering Improvement 3: Ensuring “repeated reads” actually hit the cache
With the notebook shrunk to 1/7 and space utilization optimized, the next challenge was improving prefix cache hit rates.
Many user conversations share identical beginnings—the same system prompt, codebase, or document. The system stores these computed results for reuse, a mechanism called prefix caching.
However, SWA introduced a pitfall: two requests with identical tokens don’t guarantee KVCache survival. The prefix may have been computed, but portions outside the SWA window could have been evicted. If the system still reuses data based on the old rule of “same tokens = cache hit,” it may retrieve invalid or overwritten data, crashing model performance.
Luo’s team upgraded the rule to “window-safe length”—only promising retrieval for portions that can be fully borrowed.
Imagine a library with 1 million books. You want to borrow the complete three-volume set of *The Three-Body Problem*. The old system would tell you “the book is available,” but when you arrive, only the cover and first volume remain—the other two were borrowed. This “false hit” wastes your time. The new system only promises what it can fully deliver—giving you the first volume, then fetching the other two.
This stricter rule might seem to lower hit rates, but in reality, the opposite occurs: because SWA reduces KVCache volume to 1/7, the same storage can hold several times more content, significantly boosting real hit rates.
Luo’s blog cites online testing data: under mainstream frameworks, server-side cache hit rates average 93%, reaching over 95% for high-frequency, long-context users.
In plain terms: 95% of “repeated read” requests don’t require GPU computation—they’re retrieved directly from cache. This is the physical basis for the 99% discount.
Engineering Improvement 4: Storing “cache” in the GPU’s built-in SSD
With hit rates improved, the next question was: where to store these caches?
Video memory (GPU’s HBM) is expensive and limited—a single H100 with eight cards has just 640GB, but MiMo may need to store tens of terabytes of KVCache. Hierarchical storage is essential: recently used data goes to video memory (L1), slightly older data to CPU memory (L2), and cold data to distributed cache (L3).
This resembles money management: cash in your wallet (video memory) is instantly accessible but limited; bank card balances (CPU memory) take 30 seconds to access but hold more; fixed deposits (L3 distributed cache) take 2 minutes but are much cheaper.
The industry’s standard approach is to build a separate storage cluster for L3, using dedicated machines and data centers, incurring monthly rent.
Xiaomi’s storage team took a different approach. They developed a distributed cache called GCache, deployed directly on the GPU machine’s built-in SSDs—sharing the same machines as training and inference tasks.
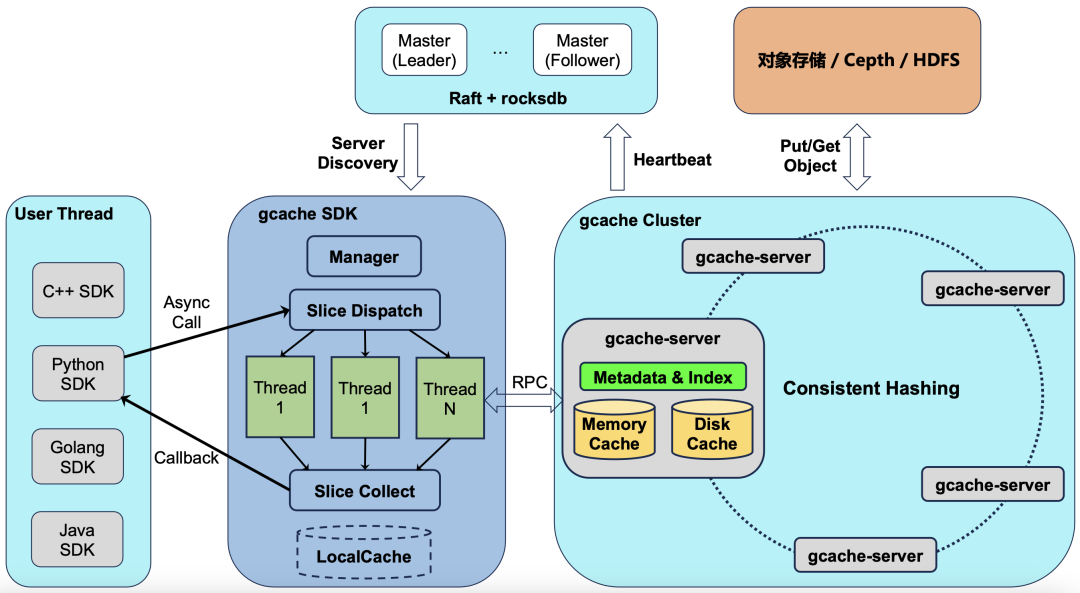
In plain terms: while others rent a separate warehouse for large data storage, Xiaomi realized the GPU machines’ “garages” were empty and stored the data there instead, eliminating monthly rent.
The technical blog states: “Additional storage costs = 0.”
This move is more impactful than it appears. In conventional “AI company compute accounting,” storage costs are a fixed expense—the larger your model and user base, the higher the storage bill. GCache eliminates this line item entirely. Combined with SWA’s reduced volume and 93-95% hit rates, KVCache survival time (TTL) in L3 extends from minutes to hours or even days—longer TTL widens the hit window for historical context, further boosting cache hit rates and justifying the 99% discount.
Engineering Improvement 5: Routing cache-hit requests via the shortest path
With caches storable, searchable, and cost-effective, the final step was ensuring the right requests reached the right machines.
Xiaomi developed a proprietary scheduling system called LLM-Router, which does three things:
1. **Affinity Scheduling**: Routes requests with identical prefixes to the same machine to maximize cache reuse.
2. **Length Bucketing**: Separates short (0-64K), medium (64K-256K), and long (256K-1M) requests into different processing channels to prevent short requests from being delayed by long ones.
3. **TTFT Optimization**: Prioritizes requests with low actual computation (i.e., those with high cache hits) in the inference queue to avoid blockage by “fresh input” requests requiring heavy computation.
For example, in airport scheduling, passengers flying to the same destination are concentrated in one waiting area to share baggage claim—this is affinity scheduling. Those with carry-ons and those with three large checked bags use separate security lines to prevent slowdowns—this is length bucketing. During boarding, passengers with only carry-ons are prioritized to board quickly and allow the plane to depart early—this is TTFT optimization.
This scheduling strategy boosted L2 cache hit rates by 25%, increased per-machine input throughput by 30%, and reduced P90 latency for long requests by 30%.
In plain terms: a single GPU can now serve more users. This explains the other half of the pricing logic—higher effective output per unit of compute power lowers per-user costs.
Engineering Improvement 6: Accelerating the model’s “typing”
The first five improvements optimized the “reading” side—reducing the cost of users repeatedly accessing historical context to nearly zero. The sixth optimizes the “writing” side—the model’s process of generating the next token.
Traditional models generate only one token at a time. MiMo natively supports 3-layer MTP (Multi-Token Prediction)—predicting the next three tokens simultaneously and skipping intermediate computations if predictions are correct.
To illustrate, traditional typing inputs one character at a time—to type “today’s weather,” you press four keys. MTP acts like an auto-complete guessing your next 1-2 characters—if correct, you skip those keystrokes.
MiMo’s MTP, tested in agentic scenarios, accelerated decoding by 2.3x for the first 128 tokens and 1.5x for tokens 128-256.
This matters because the 99% discount targets Input (Cache Hit), but input and output occur in the same request—if output costs aren’t reduced, overall request costs only halve. MTP lowers output costs, closing the loop on the pricing reduction’s profitability model.
The Cost-Reduction Chain
Stringing these six improvements into a cost-reduction chain:
SWA architecture → KVCache reduced to 1/7 → Dual pools unlock full capacity → A single GPU handles 5+x concurrent users → Prefix cache hit rates reach 93-95% → 95% of requests require nearly no computation → GCache eliminates storage costs → Scheduling prioritizes cache-hit requests → MTP reduces output costs → GPU time per request drops by an order of magnitude → Unit costs fall by 95%+ → Pricing cut by 99% while maintaining positive gross margins.
If any link is missing, the chain breaks. The 99% discount isn’t a marketing number—it’s the cumulative effect of six engineering pillars plus real-world validation.
Beyond the Hype
Looking back at the industry’s initial interpretations, each held some truth. The price wars among Chinese large model companies over the past two years are real; Xiaomi’s profit halving while investing heavily in AI is real; DeepSeek dragging industry pricing to rock bottom is also real.
However, Luo Fuli’s detailed technical blog aims to refute claims of a price war, separating “technical issues” from “marketing issues.”
He writes that MiMo-V2.5’s inference efficiency doesn’t stem from a single breakthrough but from multidimensional collaborative optimization. Hybrid SWA benefits both prefill and decode phases, but poorly optimized KVCache implementations would raise costs across the board. To address this, the MiMo team systematically rebuilt KVCache management, hierarchical caching, and prefix cache trees, solved core SWA KVCache issues, optimized scheduling strategies and the Prefill/Decode pipeline, and validated these improvements in real-world scenarios. Only then did Hybrid SWA deliver its architectural advantages in long-context inference—combining strength and efficiency. Paired with MoE configurations and multimodal inference optimizations, these efforts significantly boosted online inference performance.
This is a systematic approach to AI engineering and a cost-reduction method worthy of reference for the industry.
Price wars don’t require blogs; engineering fulfillment does.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





