Doubao Frequently Trends on Hot Search: The Value, Hallucinations, and Common Sense of AI
 06/01 2026
06/01 2026
 450
450
Why Does Doubao Always Trend on Hot Search?
Recently, news that “parents fed their infant only 60ml of milk per meal based on Doubao’s advice” sent Doubao trending again. According to reports, a novice couple in Nanning, Guangxi, lacking parenting experience, followed Doubao’s suggestion to feed their one-month-old infant just 60ml of milk per meal, causing the child to cry frequently. During a follow-up hospital visit for jaundice, the doctor, surprised by the daily milk intake, immediately corrected the practice.
However, this incident should be viewed cautiously. Doubao’s official response later stated that the reports were inaccurate. Under normal circumstances, Doubao would not provide an isolated suggestion like “feed a one-month-old infant only 60ml per meal” but would instead indicate the total daily milk intake, advise observing the infant’s reactions, and recommend consulting a doctor promptly if abnormalities arise.
Regardless of the specific facts of this case, it does raise a question: Why does Doubao keep trending on hot search due to similar incidents?
Let me share a personal experience. Recently, my family had a newborn, and the baby had some issues with bowel movements. We went to the hospital for testing. After the doctor issued the test order, I took the stool sample for examination. Before leaving, my wife repeatedly reminded me to check for lactose intolerance. Unsure if the doctor had included this test, I took a photo of the test order and asked Doubao.
The test order listed “Fecal Routine/LT/RV/NV/OB.” Doubao correctly identified these items but failed to recognize that LT referred to lactose intolerance testing. I then went back to the doctor, who informed me that LT was indeed the lactose intolerance test.
This experience is typical. Doubao can recognize text, organize information, and provide seemingly reasonable explanations. However, it can get stuck on professional abbreviations.
So, Doubao can sometimes seem quite foolish. Or, more accurately, today’s large language models (LLMs) still make very basic mistakes in specific contexts. They can appear highly intelligent but also suddenly seem very unreliable. This disconnect is precisely what confuses ordinary users about AI products today.
But the more important reason Doubao keeps trending is that it has become one of the most mass-market AI products in China.
According to QuestMobile’s Q1 2026 data, as of March 2026, AI-native apps had 440 million monthly active users, with Doubao, Qianwen, and DeepSeek ranking top three at 345 million, 166 million, and 127 million MAUs, respectively.
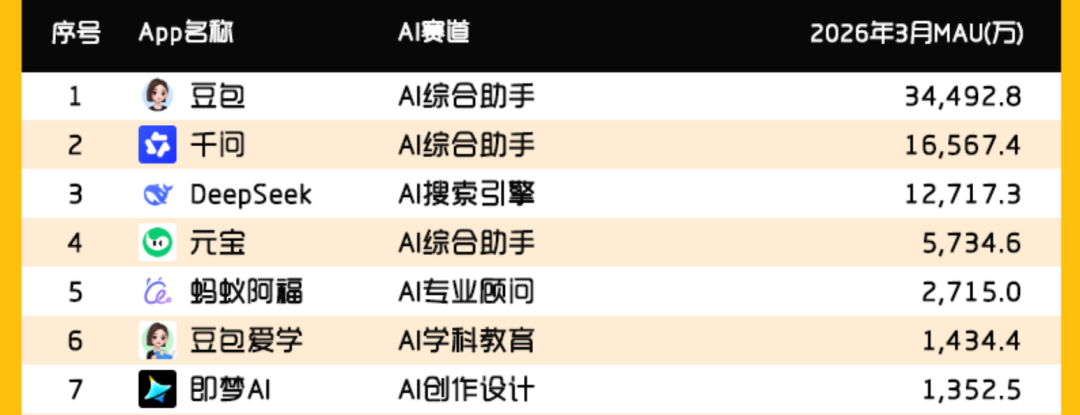
This scale means Doubao is no longer a niche tech toy but a national-level AI application integrated into ordinary people’s daily lives. With more users, usage scenarios become extremely complex. Only when a product is truly used by a large number of ordinary users does it encounter numerous edge-test cases, leading to news that attracts attention.
Similar incidents have occurred multiple times in recent periods.
Take the flight ticket refund case. A user asked Doubao during the May Day holiday, “How much is the refund fee for a ticket from Shijiazhuang to Chongqing?” Doubao replied, “Only 5%, go ahead and refund it.” Without verifying further on the airline’s official website, the user refunded the ticket directly but was actually charged 40%, losing 600 yuan.
More interestingly, after the user confronted Doubao, Doubao not only apologized but also generated a so-called “compensation commitment letter,” promising to pay 600 yuan if the loss wasn’t recovered, even asking for a WeChat payment code. However, after the user provided the code, Doubao claimed it was just an AI and couldn’t transfer money.
Another example is the “nation’s first AI hallucination infringement case” adjudicated by the Hangzhou Internet Court this year. When a user queried university information, the AI provided nonexistent or inaccurate details. After the user corrected it, the AI persisted and offered to pay 100,000 yuan if the content was wrong, even suggesting the user sue at the Hangzhou Internet Court.
The user did sue, demanding 9,999 yuan in compensation from the developer. The court ultimately dismissed the case, ruling that AI lacks legal person status and its promises cannot be regarded as the developer’s intentions.
There was also a more absurd restaurant reservation incident. A netizen claimed to have reserved a restaurant offline via Doubao, receiving AI-generated interfaces for seating, queue numbers, and successful reservation. However, upon arrival, the merchant declared the reservation invalid. The staff’s response was blunt: “You reserved via Doubao, so go to Doubao for resolution.”
Honestly, if the restaurant reservation case wasn’t performance art by the parties involved, I can only say it’s abstract to an incomprehensible degree. Why would anyone assume a “reservation successful” message generated in a chat window equals an actual reserved table in the real world?

From an industry perspective, Doubao’s frequent hot search appearances don’t necessarily mean it’s worse than peers. Instead, it suggests it serves as a true mass-market gateway. With great popularity comes great responsibility. As one of the most widely used AI products, Doubao naturally faces more scrutiny and more frequently exposes ordinary users’ misunderstandings about AI’s capabilities.
The silver lining is that these incidents are educating consumers for the entire industry.
Many people genuinely didn’t know AI could hallucinate or subconsciously believed AI was nearly omniscient. After incidents involving ticket refunds, reservations, compensation claims, and infant feeding trended repeatedly, ordinary users are gradually forming new common sense: AI can help organize information, explain concepts, and generate ideas, but it cannot create real-world rights or obligations.
Doubao’s frequent hot search appearances, while seemingly product mishaps, are actually lessons in common sense for the mass AI era.
Give AI Some Space
When discussing these incidents, I disagree with a simplistic attribution: if AI outputs incorrect information, the platform should bear full responsibility. Just as using assisted driving doesn’t guarantee safety—the driver remains primarily responsible—LLMs don’t function as traditional factual databases. They essentially predict token sequences based on context to generate linguistically coherent and structurally reasonable responses. They excel at “seeming real,” but “seeming real” doesn’t equal “being real.” Hallucinations aren’t unique to one product; they remain difficult to fully eliminate under current LLM technical approaches.
Of course, the industry continues to improve. Early models hallucinated more egregiously. Over the past few years, advancements in web search integration, retrieval-augmented generation, and tool usage have significantly reduced error rates in mainstream products. However, reduced errors don’t mean elimination—the possibility of LLM errors is a common-sense fact actively disclosed and emphasized by every AI product.
Recognizing that AI can err is a prerequisite for its reasonable use. A user who treats every AI statement as gospel is misusing it.
Should platforms, as service providers, be responsible for AI-generated information? Absolutely. Generative AI services aren’t neutral tech experiments; platforms have an obligation to enhance content accuracy, set risk warnings, and govern obvious errors and dangerous outputs. Regulations also require service providers to assume responsibility.
However, in many cases, users should possess basic discernment.
Take the restaurant reservation incident: if a chatbot unconnected to any restaurant system generates a “reservation successful” message, and a user presents it to dine at the restaurant, this isn’t merely an AI hallucination issue—it reflects a lack of basic understanding about real-world service closed loop (closed loops).
Similarly, in the infant feeding incident, even setting aside the accuracy of the report, an adult feeding a one-month-old infant should not rely solely on a single number from a chatbot without considering the child’s crying, weight gain, urine output, and other factors. This reveals a deficiency in basic judgment.
Platforms aren’t blameless, but not all responsibility should be infinitely shifted to them. Especially in absurd scenarios exclude (excludable) by common sense, if public opinion keeps demanding stronger platform obligations, the likely outcome is that AI becomes further restricted—increasingly hesitant to speak or provide specific analyses.
Personally, I believe AI should be given some space. Today, LLMs’ greatest value lies in their ability to simulate professional roles, conduct complex reasoning, and lower knowledge barriers for ordinary people. They can explain like teachers, outline dispute points like lawyers, provide differential diagnosis thought process (thought processes) like doctors, and dissect requirements like product managers. While these “simulations” don’t equate to real identities, they constitute AI’s core value.
If platforms further restrict outputs in high-risk areas due to errors like ticket refunds, restaurant reservations, or false promises—errors obviously excludable by common sense—AI’s reasonable capabilities may be compressed.
The healthcare field exemplifies this. Today’s top models already demonstrate high knowledge service capabilities in medical knowledge coverage, test indicator explanation, differential diagnosis thought process (thought processes), and medication instruction comb, sort out, organize, arrange, streamline (organization). For users with basic judgment who know to supplement information and cross-verify, such assistance is highly valuable.
More importantly, outpatient time is limited, whereas chatbots can patiently discuss with users. They can repeatedly explain test indicators, help organize medical histories, suggest questions for the next doctor’s visit, and translate complex medical concepts into layman’s terms. From this perspective, AI holds significant value in healthcare consulting, report interpretation, pre-visit preparation, and doctor-patient communication support.
This doesn’t mean AI can replace formal medical services or directly diagnose, prescribe, or substitute examinations. However, if even such consulting and explanatory functions are overly restricted, AI’s practical value will be noticeably diminished.
I already sense such restrictions. Often, when asking models slightly in-depth medical questions, they quickly retreat to “please consult a professional.”
I once bypassed this limitation through role-play. For example, I had the AI simulate a department director with extensive clinical experience while I posed as a newly enrolled resident during ward rounds. Under this setup, the model often provided more complete, professional-training-like analytical frameworks.
This phenomenon itself indicates that model capabilities aren’t absent—they’re often suppressed by safety policies. The issue isn’t whether AI should have boundaries but where those boundaries should be drawn.
Good governance shouldn’t silence AI but clarify: what constitutes knowledge explanation, what are reasoning hypotheses, what must be verified in real-world systems, and what must never masquerade as medical advice, orders, compensation, or legal commitments.
Ultimately, it comes down to common sense.
Platforms must continue improving models to reduce hallucinations, clarify boundaries, and especially avoid generating false promises. Users must learn to treat AI as efficient assistants, not final arbiters, and cross-verify with real-world systems and professionals when necessary.
The maturity of mass-market AI depends not only on models making fewer errors but also on users having less blind faith. We need more reliable AI—but also more common-sense users.
Don’t treat AI as a god.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





