"Event-Level" World Model WALL-WM: The Robot's Brain Finally Learns to "Prioritize"
 06/01 2026
06/01 2026
 673
673

Author|Su Han
Do you need to simultaneously calculate the speed of the oncoming car, the distance, and the 3.5 seconds it takes for you to cross the zebra crossing every morning when crossing the road?
Of course not. You simply take a quick glance and silently assess a critical question in your mind: "Will the car hit me?" Then you decide whether to proceed or stop.
The entire process takes less than a second and consumes minimal energy. However, today's robots are almost always doing the former.
They are set to predict the next moment of the world at a fixed frequency, 30 times or 50 times per second, even if they know nothing will happen in the next 0.5 seconds, they still have to complete the calculations.
It's like calculating all 300 steps of crossing the road every morning before taking the first step.
Tiring, isn't it? Of course, it is.
The key point is that most of the calculations are wasted. This is one of the fundamental reasons why current robots are "inconsistent":
They are too obedient, so obedient that they exert equal effort on every frame and every second, never asking themselves, "What is worth thinking about, and what isn't?"
On May 29, Independent Variable Robot introduced Wall-WM, the first world model with "event-level prediction capabilities."
Its core is to break free from the old paradigm of "uniform time sampling." The model no longer mechanically predicts every frame but instead judges which moments are truly important.
In other words, Wall-WM enables robots to finally learn to "prioritize."
However, what does the introduction of this world model really mean?
Why does the innate human ability to "prioritize" become a fundamental technological innovation when applied to robots? To answer these questions, we must first understand how a robot's "brain" works.
From Mechanical Imitation to True Understanding: How Does Wall-WM Achieve This?
Currently, the mainstream "brain" for robots in the industry is called VLA (Vision-Language-Action). As the name suggests, one module is responsible for "seeing," another for "understanding human language," and the third for "taking action."
It sounds reasonable, but the problem is that these three modules are connected in series: the vision module passes what it sees to the language module, which then passes its understanding to the action module. Each transfer results in a loss of information.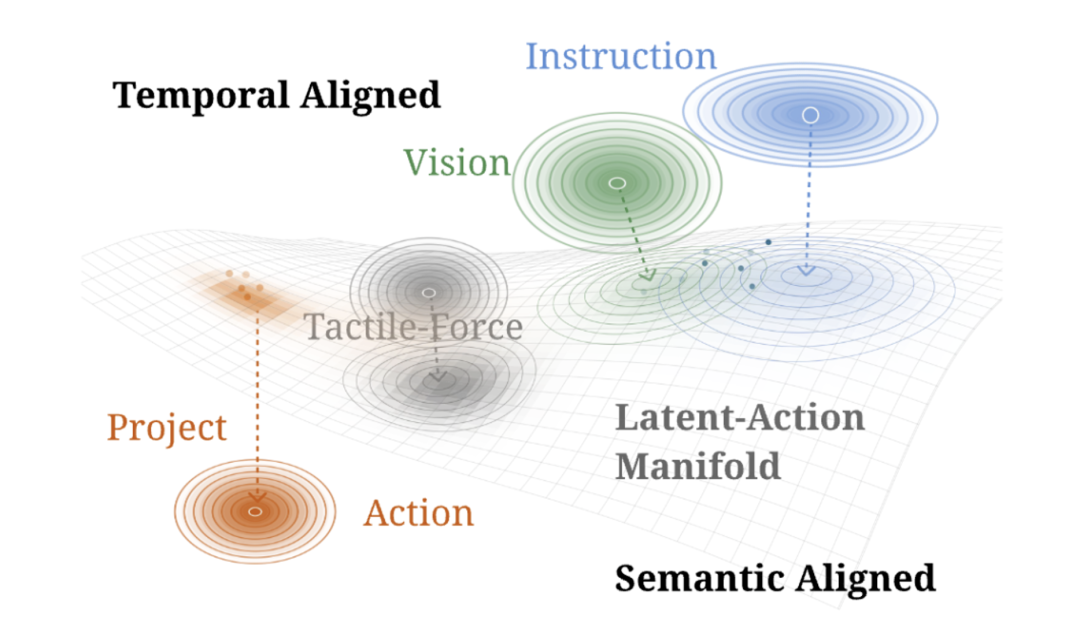
This is why many robots appear "dumb." It's not because they didn't see it, but because much of the information they saw was lost by the time it reached the "action" module. Is there any way to improve this?
Independent Variable Robot's answer is to replace the time unit it uses for thinking through the Wall-WM world model.
Traditional models predict the future at a fixed frequency, 30 times or 50 times per second, exerting effort on every frame. Even if nothing happens in the next 0.5 seconds, they still have to complete the calculations. This is called "frame-level prediction."
However, Independent Variable Robot has adopted a different logic: predicting based on "events."
What is an event? Reaching out, grasping, lifting, moving, placing—these coherent, meaningful action segments over a period are events.
The model only readjusts its predictions when "significant changes" occur in the world.
For example, "the cup starts to slip" is one event, and "the hand touches the cup" is another. At other times, it doesn't need to think 30 times per second.
More importantly, what it learns is not "I need to execute instruction X in frames 10-20," but rather how the physical world will evolve under this event and how it should act.
But there's a hidden challenge here:
What if the robot forgets its hard-earned visual capabilities while learning new actions? Wall-WM has specifically considered this issue of "learning new without forgetting old" in its design.
The design of Wall-WM is clever. Its vision module and action module are not equal; instead, they are unidirectionally coupled:
The action module can only read information from the vision module but cannot interfere with it in reverse. It's like taking notes while reading a book—the notes don't change the words on the page.
This way, during large-scale training, the model can retain its original visual understanding capabilities while continuously improving its action capabilities. Engineers also don't need to "guess" in advance how actions should be encoded because the model will learn it on its own.
However, after solving the issue of "learning new without forgetting old," Wall-WM still needs to address another longstanding problem: How does a robot know that multiple cameras on its body are capturing the same thing?
Most robots have more than one camera, such as one on top of their head, one on their left wrist, and one on their right wrist. The problem is, how does it know that the images from these three cameras correspond to the same object?
The traditional approach is to let the model learn the correspondence on its own.
However, the results are often unsatisfactory: the model tends to be lazy, treating cross-view attention as a generic feature mixer rather than truly understanding spatial geometry.
Therefore, Wall-WM introduces two mechanisms: cone masking and tubular masking.
Cone masking physically tells the model: The images from these two cameras cannot possibly correspond in space, so don't bother learning their relationship.
Tubular masking, on the other hand, "forces" the model to learn the truly corresponding regions by intentionally blocking a certain area in one camera's image and compelling the model to find the same content in other cameras.
A layman's understanding: Ordinary AI sees things as a "2D jigsaw puzzle," where each image is an independent plane.
Wall-WM, however, sees things as "3D building blocks." It knows that images from different angles splice (pinjie, meaning "piece together") into a three-dimensional object. Even if a certain angle is blocked, it can "mentally reconstruct" the object's true position.
Understanding space and events, Wall-WM has taken a significant step forward compared to traditional models in terms of "what it thinks about." But for a robot, thinking fast is not enough—the real world doesn't wait.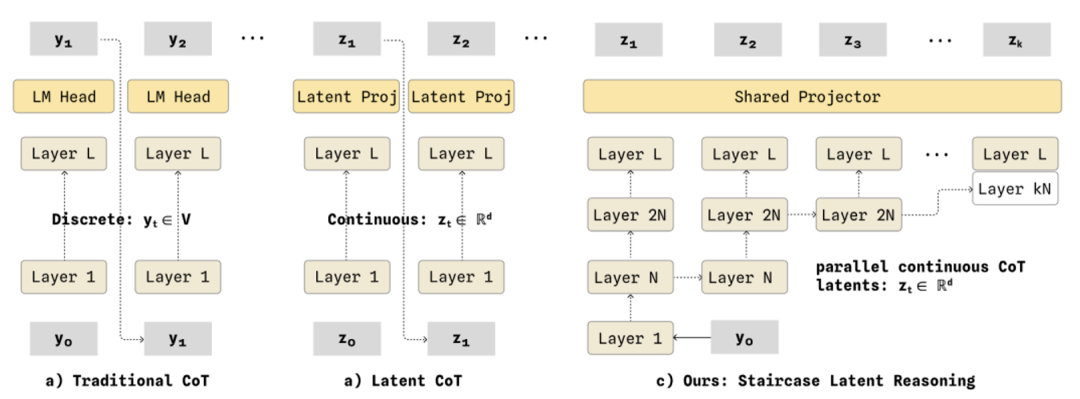
When robots perform complex tasks, they often need a "Chain of Thought" (CoT), meaning they reason through the steps in their mind before acting.
However, traditional CoT reasons step by step, needing to finish the first step before moving on to the second, which is very slow.
Wall-WM's approach is:
The bottom layer (dǐcéng, meaning "bottom layer") runs only once, while the high-level (gāocéng, meaning "higher layers") unfold in parallel like a staircase. Moreover, the most crucial aspect is that the CoT it produces remains discrete and readable text. You can always open it to see how the model is reasoning, making interpretability and real-time performance no longer a trade-off.
What Does the Release of Wall-WM Mean for the Industry and Developers?
From understanding events to comprehending space and then making rapid decisions, Wall-WM has fundamentally rewritten the "mechanical" way of thinking at the bottom layer (dǐcéng, meaning "bottom level").
However, Wall-WM also has a clever design: the same "brain" can be flexibly adapted to different scenarios.
It has two modes. One is called "Event Mode," suitable for scenarios with an upper-level planner. For example, if you give the robot a task like "bring me the cup," it can break it down into a series of events—reaching out, grasping, lifting, moving, placing—and output one complete action unit at a time, closely aligning with event boundaries.
The other is called "Unified Mode," suitable for scenarios without an external planner that require end-to-end real-time control. The model reasons and executes simultaneously, maintaining a fixed control frequency.
These two modes can be switched as needed without retraining.
A lightweight household robot can run in a low-computing-power mode, while an industrial robotic arm can switch to a high-computing-power mode. The same code thought process (sīlù, meaning "approach") can adapt to everything from a floor-cleaning robot to a factory production line.
For developers, there's no longer a need to maintain multiple models for different devices, significantly reducing development costs.
Currently, a consensus is forming in the embodied AI industry:
World models will become the next infrastructure in the robotics field, but most are still stuck in research papers or internal systems.
Independent Variable Robot is the first to fully demonstrate a world model with "event-level prediction capabilities."
It's not just releasing a demo or an API; instead, it has detailedly disclosed the entire thought process (sīlù, meaning "approach"), model design, training scheme, and experimental data through a technical report.
And the experimental results have validated the effectiveness of the "event-level prediction" approach.
In real-world Core15 L1 benchmark tests, Wall-WM significantly outperformed similar models like π0.5 and DreamZero in average task completion scores.
It demonstrated stronger completion capabilities in basic tasks, reasoning tasks, dexterous operations, and generalized scenarios, making it one of the most accomplished L1 models under abstract instruction settings.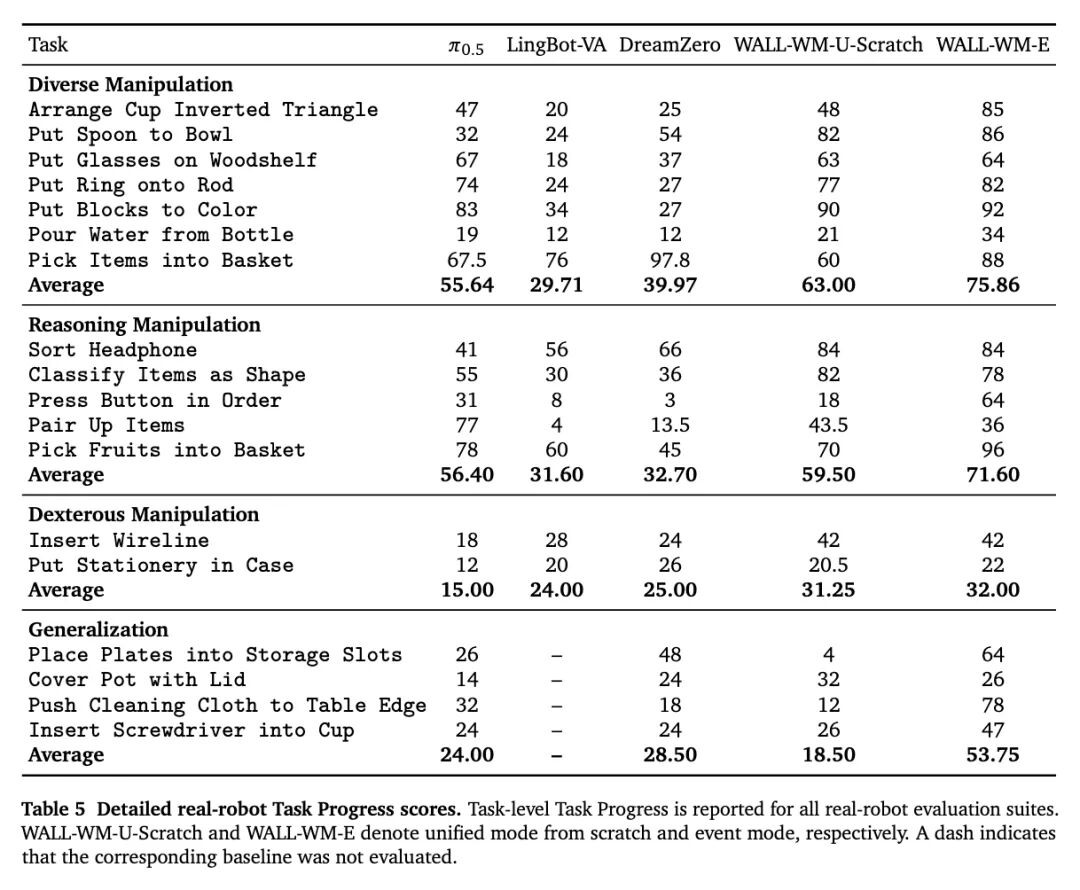
This means that Wall-WM has improved not just mechanical execution capabilities but also the robot's understanding of complex tasks and abstract goals.
Meanwhile, in Embodied Video Generation tests, compared to traditional video generation models like Wan2.1 and Wan2.2, Wall-WM achieved significant leadership in multiple embodied-related dimensions such as Motion Quality, Semantic Consistency, and Physical Plausibility.
Behind this, fundamentally, is because it no longer just generates frames one by one but predicts how "events" evolve in the real physical world.
Additionally, in 3D Awareness (CO3Dv2) tests, Wall-WM also outperformed models like WAN2.1-14B, Open-Sora 2.0, V-JEPA, and DINOv2 in spatial error metrics such as Point Error and Depth Error.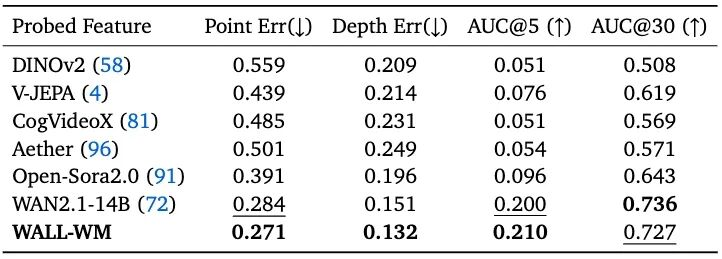
But more important than performance improvements is that it has changed the way robots understand the world.
In the past, robots exerted effort on every frame; now, they are beginning to learn, like humans, what is worth thinking about and what isn't worth wasting computing power on.
The true value of Wall-WM may not lie in being yet another VLA model with higher benchmark scores but in providing a self-consistent engineering solution to the fundamental problem of embodied foundation models: how to enable the model to truly learn to predict the physical world while retaining multimodal visual priors and spatial geometric understanding.
Here, "events" are no longer just an annotation granularity for actions but have become the true unit of thought for the world model.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





