AI Image Generation Finally Stops Guessing! GenEvolve Transforms Open-Ended Image Generation into a Trainable, Self-Evolving Agent!
 06/01 2026
06/01 2026
 440
440
Interpretation: The Future of AI Generation
Many image generation tasks seem straightforward—just ask the model to draw a picture. However, the real challenges often arise before generation begins.
For example, if a user requests an image of a specific real-world landmark, the model cannot simply generate a 'similar-looking building.' If a reference image is provided, the model must preserve not just the style but also the identity, form, and key materials. When users specify text, spatial relationships, or vague information in posters, precise execution of all details is required.
Together, these challenges form a typical open-ended generation scenario: the model must first gather information, select references, disentangle constraints, and then organize these elements into instructions that the underlying generator can execute. GenEvolve focuses precisely on this step. Instead of treating image generation as a single prompt rewriting task, it models the pre-generation decision-making process as a tool trajectory.
Project Homepage: https://ephemeral182.github.io/GenEvolve/
arXiv: https://arxiv.org/abs/2605.21605
GitHub: https://github.com/MeiGen-AI/GenEvolve
Model Weights: https://huggingface.co/MeiGen-AI/GenEvolve
Data & Evaluation: https://huggingface.co/datasets/MeiGen-AI/GenEvolve-Data-Bench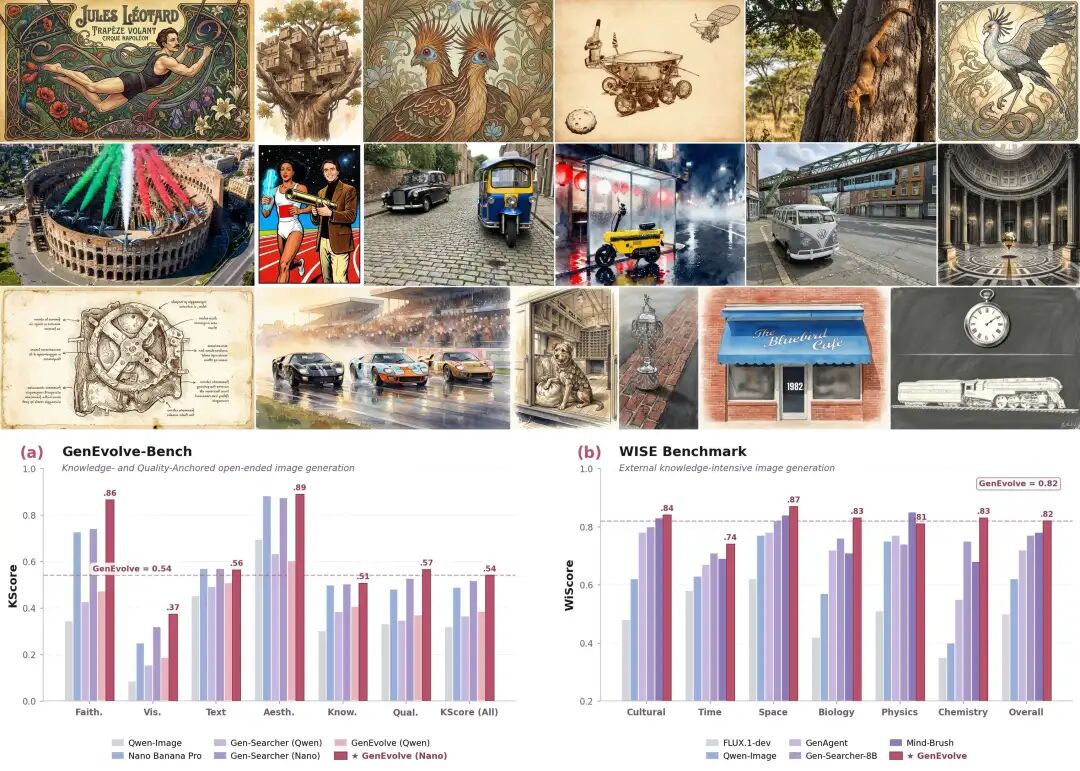
As a pre-generation agent strategy, GenEvolve can be combined with various renderers such as Qwen-Image-Edit and Nano Banana Pro. Before generation, the Agent must make three types of judgments.
In open-ended image generation, the information missing from user requests is not always the same.
The first type is factual basis. Tasks involving real buildings, products, public figures, historical events, scientific concepts, etc., require first supplementing external knowledge; otherwise, the image may 'look reasonable' but contain critical factual errors.
The second type is usable references. Reference images are not just for showing style—they may carry constraints such as character identity, product structure, partial form, clothing material, etc. The Agent must determine which images are worth using and how references should be incorporated into the final program.
The third type is generation control capability. Text rendering, counting, layout, attribute binding, anatomical consistency, and material consistency are often the most error-prone parts of open-ended generation. These need to be explicitly defined as verifiable constraints rather than remaining as vague natural language wishes.
To address these three types of needs, GenEvolve provides the Agent with three entry points: search(q) for querying external evidence, image_search(q) for retrieving visual references, and query_knowledge(skill) for invoking generation knowledge related to text, space, quantity, and materials. The Agent's goal is not to 'call more tools' but to organize tool results into a prompt-reference program and then pass it to the underlying image generator for execution.
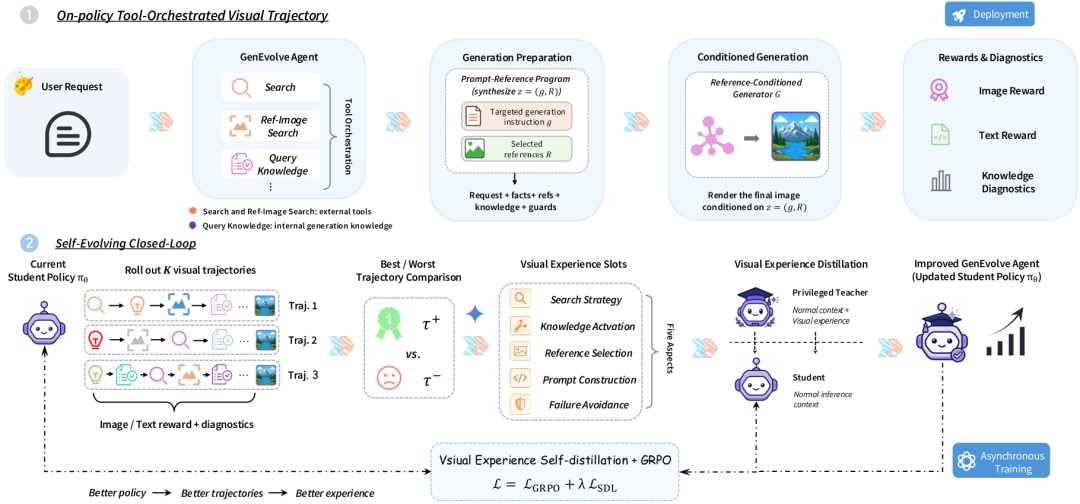
GenEvolve breaks down an open-ended generation task into tool invocation, reference binding, skill activation, and final program generation. 1) Unified 'Tool Orchestration' Paradigm: A Single Agent Covers Multiple Needs in Open-Ended Generation
GenEvolve does not treat open-ended image generation as a collection of independent modules or tools to be handled separately. Instead, it organizes the most common needs in open-ended generation scenarios into two major tracks, unified under a single Agent:
External Knowledge Dependency (Knowledge-Anchored): Entity recognition, events, landmarks, products, visual facts; Quality Constraint Dependency (Quality-Anchored): Text rendering, spatial layout, quantity, attribute binding, anatomy, material consistency, aesthetics, creative transformation.
What matters here is not just the 'task names themselves' but that these capabilities collectively correspond to a real design workflow:
Receive user request → Search for external evidence → Find visual references → Activate appropriate generation knowledge → Write an executable prompt-reference program → Pass it to the generator for rendering → Output the final finished image
Many previous approaches simply stitched together 'search augmentation' and 'image generation modules.' While functionally covering all bases, the overall experience often felt disjointed.
In contrast, GenEvolve functions more like an 'intelligent generation assistant based on tools and experience': given an open-ended request, it can both call external tools to gather evidence and find reference images, as well as activate appropriate skills based on the request type, organizing all information into a generator-agnostic final program.
2) 'Data-Evolution-Distillation' Closed Loop: Enabling a Single Agent to Learn Both Tool Usage and Creativity While Alleviating Multi-Constraint Conflicts
To train an Agent truly oriented toward open-ended image generation, the first step is not to directly fine-tune it on a mix of tasks but to answer a more fundamental question:
What kind of data can teach a model to complete the entire pipeline of 'understanding the request → finding evidence → selecting references → activating generation knowledge → writing the final program'?
GenEvolve-Data is therefore not an ordinary prompt-rewriting dataset nor a simple image-text pairing dataset. Each sample is designed as a complete open-ended generation problem: some lack external facts, some rely on visual references, and some require precise text, quantity, layout, materials, or anatomical structures. These requests are first controlled by structured recipes to cover the scope, then generated into real multi-round tool trajectories by a Teacher Agent, and finally audited by VLM, rendered into GT images, and visually filtered to form three views usable for SFT, self-evolution, and evaluation.
With this data foundation, the second question arises: How can the same Agent handle both Knowledge-Anchored and Quality-Anchored needs? Task interference does occur here: knowledge-based constraints emphasize factual correctness and reference consistency, while quality-based constraints focus on pixel-level verifiable details. Therefore, GenEvolve does not cram all signals into a single training pass but adopts a phased approach:
First, supervised fine-tuning (SFT cold start) is performed on filtered tool orchestration trajectories to teach the Agent 'when to search, when to look at images, when to activate skills, and what kind of program to output.' Then, through GRPO + visual experience self-distillation (SDL) in a feedback-driven RL phase, both 'which trajectory is better' and 'what makes a token better' signals are optimized simultaneously. Finally, the 'experience' is fully baked into the weights, and the deployed Student model requires no runtime memory—the retrieval corpus and privileged Teacher exist only during training. 3) GenEvolve-Bench: Evaluating Common Needs in Open-Ended Image Generation with a Unified Benchmark System
To evaluate such tasks more comprehensively, we constructed GenEvolve-Bench, a unified testing benchmark for open-ended image generation covering the two main tracks of Knowledge-Anchored and Quality-Anchored, with systematic evaluations conducted accordingly.
Experimental results show that GenEvolve performs more balancedly across both tracks. It demonstrates particularly strong advantages in Knowledge-Anchored tasks requiring greater external world knowledge, while also showing better stability in Quality-Anchored tasks involving verifiable details such as text, quantity, layout, and materials.
Under a unified and fair evaluation method (KScore: Faithfulness 0.1 / Visual 0.4 / Text 0.4 / Aesthetic 0.1, with Gemini 3.1 Pro Preview as the visual scorer), GenEvolve's overall performance surpasses current mainstream open-source direct generators and agentic workflows, achieving the highest current KScore when paired with strong generators.
We additionally conducted extrapolation testing on the public WISE knowledge-intensive benchmark: using an 8B open-source strategy + open-source Qwen-Image-Edit renderer, the overall WiScore reached 0.82, surpassing GPT-4o (0.80) and all agentic baselines.
Methodology
GenEvolve's core goal is to uniformly model the common scenario in real open-ended image generation where
'one open-ended request + multiple hard constraints'
exists, as one self-evolving agent for tool-orchestrated open-ended image generation.
In other words, it aims for a single agent to possess two types of capabilities simultaneously:
On one hand, it can retrieve world knowledge, select and bind reference images, and transcribe external evidence into generation programs; on the other hand, it can accurately express hard constraints such as quantity, text, layout, anatomy, and materials at the program level—all within the same framework while balancing 'factual correctness' and 'visual compliance with all requirements.'
To achieve this, we designed a complete training pipeline of Data-Expert-Evolution-Distillation, combined with visual experience self-distillation at the end to explicitly distill the 'differences between optimal/worst trajectories' into the deployed model, thereby minimizing mutual interference in multi-constraint training as much as possible.
GenEvolve Method Overview: The Student samples multiple tool orchestration trajectories; optimal/worst pairs are distilled into a structured Decision Guide given only to the privileged Teacher, then token-level reverse KL distillation returns it to the deployed Student. Phase 1: Automated Data Construction & GenEvolve-Data
For a unified agent to truly possess generalization capabilities, the prerequisite is having high-quality, controllable tool orchestration trajectory data covering multiple constraint types.
To this end, GenEvolve first established an automated data production pipeline, constructing GenEvolve-Data and simultaneously building the evaluation set GenEvolve-Bench.
The entire process can be understood as a complete data closed loop (closed loop):
Structured Recipe → Natural Request Prompt → Teacher Agent Multi-Round Tool Trajectories → VLM Auditing → GT Image Rendering → Visual Filtering → Three Splits for Training/RL/Benchmark

The GenEvolve-Data and GenEvolve-Bench data closed loop (closed loop): From structured recipes to Teacher tool trajectories, VLM auditing, GT image rendering, visual filtering, then split into SFT/self-evolution/evaluation three views.
In other words, we did not simply splice together existing samples but first generated requests closer to real open-ended generation needs, then applied strict filtering and task-oriented transformations to ultimately precipitate (distill) them into a trainable, evaluatable data system.
From a categorical distribution perspective, GenEvolve-Data is organized into two main tracks: Knowledge-Anchored and Quality-Anchored. The former covers external knowledge-related scenarios such as architecture, street views, public figures, products, vehicles, events, science, and cultural relics; the latter covers visible quality constraints such as text/layout, spatial relationships, counting, anatomy, attribute binding, materials, aesthetics, and creative transformation. This design ensures the benchmark tests not just 'how visually appealing the image is' but whether the Agent can select appropriate evidence, reference images, and generation skills based on request type.
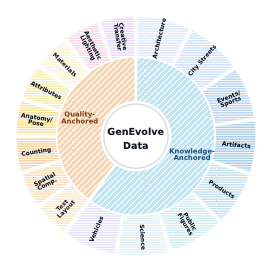
The category hierarchy of GenEvolve-Data: Each main track covers 8 diagnostic scenarios for controlling data coverage, hierarchical splitting, and benchmark analysis.
From construction statistics, the data also underwent strong filtering:
The prompt pool retained 19,990 valid requests; of these, 19,320 passed structural checks to enter the trajectory phase, ultimately retaining 13,379 high-quality filtered trajectories; SFT trajectories numbered 8,800; GT image generation succeeded for 4,321 images, with 3,175 visual feedback cases retained after filtering; the self-evolution training pool contained 2,575 cases, and the held-out benchmark contained 594 cases. 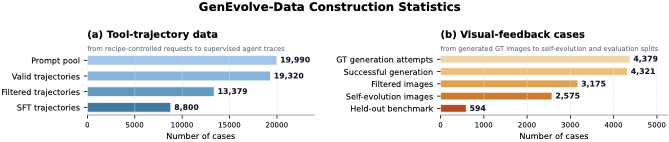
GenEvolve-Data Construction Statistics: The left side shows the filtering process from prompt to SFT trajectories; the right side shows the segmentation of GT images, visual filtering, self-evolving samples, and held-out benchmarks.
(1) Request and Basic Trajectory Generation: Closer to Real Open-World Generation Needs
The requests used by GenEvolve are not ordinary captions. Instead, they first combine information such as task family / missing external evidence / visual anchors / dominant generation requirements / difficulty, and then use a VLM to expand them into natural but hard-constrained open-ended requests. Subsequently, the Teacher Agent (Seed 2.0 / Gemini 3 Pro) undergoes a real multi-round tool cycle: initiating text searches, pulling visual references, activating generation knowledge, and ultimately outputting a prompt-reference program.
The tool invocation order is request-driven: knowledge-intensive requests often start with factual lookups; reference-sensitive requests rely on image searches earlier; quality-driven requests activate internal generation knowledge sooner.
(2) Multimodal Filtering: Ensuring Data is Usable for Both Training and Evaluation
For synthetic data, the real bottleneck often lies not in quantity but in noise control. Therefore, we designed a hierarchical filtering mechanism to ensure the reliability of the training and evaluation sets.
Trajectory Filtering: Programmatic checks remove incomplete tool cycles, invalid references, URL/ID leaks, missing ordinal bindings, and overly simplified final programs. A VLM scorer then reviews whether "the reference truly supports the image," "whether evidence is adopted," and "whether the program covers all hard constraints." GT Image Filtering: High-quality Teacher programs are rendered into GT images by Nano Banana Pro, followed by a second visual filtering step to check prompt consistency, reference utilization, visual coherence, and generation quality. Three-View Segmentation: The final retained samples are split into SFT View (preserving complete tool cycles without exposing GT images), Self-Evolution View (retaining requests + GT images + metadata), and the GenEvolve-Bench evaluation set, covering both Knowledge and Quality tracks. Phase 2: SFT Cold Start (Teaching the Agent "How to Use Tools" First)
If the model is directly thrown into RL for trajectory sampling, the most common issue is extreme instability in early tool invocations: when to search, whether to replace references, whether to adjust skills, how to write the final program... All require a qualified initial value for "proper tool use" first.
To address this, GenEvolve performs a cold-start SFT on the filtered Teacher trajectories.
Training Target: The language policy part of Qwen3-VL-8B-Instruct (visual encoder frozen, optimizing only the assistant-side tokens, including / /); Training Stack: LLaMA-Factory long context (cutoff 32K), bf16 + FlashAttention-2, ZeRO-3, AdamW optimizer + cosine learning rate; Exit Criterion: Select checkpoints based on held-out trajectory loss rather than benchmark performance to avoid overfitting to the scorer prematurely during SFT.
The resulting GenEvolve-SFT after cold start can be understood as "a student who has learned the Teacher's entire paradigm of tool invocation + program writing" but has not yet learned "which trajectories truly yield high-scoring images."
Phase 3: GRPO + Visual Experience Self-Distillation (SDL)
Supervised fine-tuning enables the model to "use tools" but struggles to further teach it to "use them better, more like a high-level designer."
We introduce two layers of signals for simultaneous optimization during the RL phase:
(1) Trajectory-Level: GRPO + Hybrid Rewards
For each user request, the agent samples 6 rollouts, each producing a program z, which is then rendered into an image by the generator. Two scorers simultaneously evaluate:
KScore Visual Scoring: Four-dimensional Faithfulness / Visual / Text / Aesthetic (weights 0.1 / 0.4 / 0.4 / 0.1); Program Sufficiency Text Scoring: 5-point scale {0, 0.25, 0.5, 0.75, 1} to assess whether the program carries sufficient facts, ordinal references, skill activations, and executable hard constraints.
The final reward R = 0.5 R_img + 0.5 R_text serves as the group-relative advantage signal for GRPO.
(2) Token-Level: Visual Experience Self-Distillation
Trajectory-level rewards alone are insufficient—they tell you "which trajectory is better" but not "why this one is better." GenEvolve's key contribution is transforming "why" into a learnable token-level signal:
For each prompt's 6 rollouts, the optimal/worst pair (requiring reward gap ≥ δ_min) is selected, and Gemini 3.1 Pro Preview distills their differences into a structured Decision Guide: retrieval_key: trigger phrase + source-prompt summary; decision_guidance: 6 types of imperative bullets (recommended tool plans / search queries / skill routing / reference selection / program writing / failure defenses). These Decision Guides enter a prompt-keyed rolling buffer (capacity 500), with retrieval indexing established via Qwen3-Embedding-0.6B based on embed(trigger + summary). During training, the top-1 Guide is pulled back via cosine similarity (gate ≥ 0.84) and injected only into the Teacher's perspective; the Student always sees only the ordinary system prompt. SDL uses importance-weighted reverse KL to align the Student's distribution with the Teacher's on the same batch of on-policy tokens—but only on decision-critical tokens: Decision-only mask: Retains only tokens within / blocks; Top-K filtering: Retains only the top 10% tokens with the largest |log π_E − log π_S| per sequence.
In summary: On the few dozen most critical decision tokens, the Student learns "what a person seeing the Decision Guide would do"—but during deployment, the Student requires no retrieval library. This is how GenEvolve fully burns "experience" into the weights.
This figure shows what SDL actually learns at the token level. On the left, the Teacher overrides the Student: The Student originally tends to output generic or filler tokens, but with the Decision Guide's help, the Teacher redistributes probability mass to more critical actions, such as invoking tools first, clarifying spatial layouts, anchoring factual identities, or selecting reference images. On the right, the Teacher supports the Student: When the Student is already moving in the right direction, the Teacher further increases the probability of correct decision tokens, encouraging the model to reuse these strategies more confidently in subsequent training.
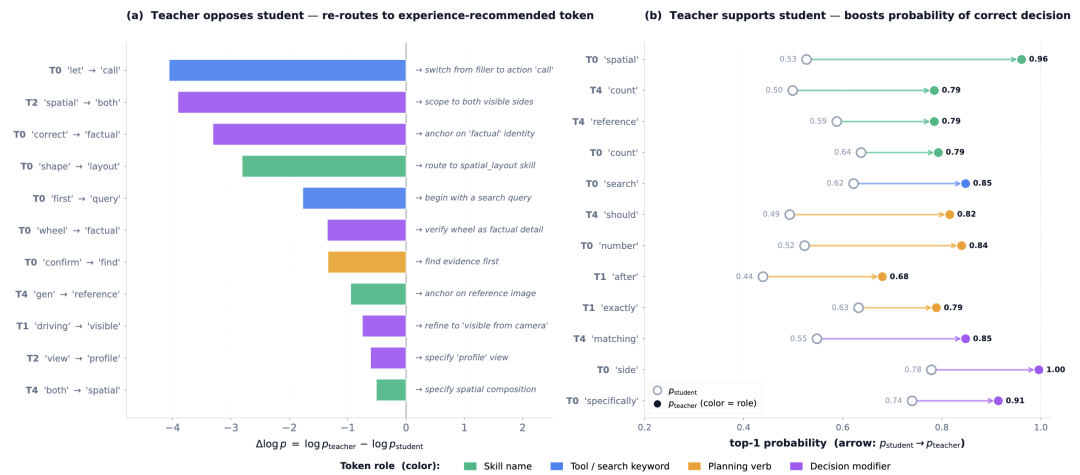
SDL's token-level evidence: The Teacher corrects the Student's erroneous decision tokens while amplifying the probability of existing correct decisions, ultimately precipitate ing [ precipitate here means embedding] visual experience into the deployed model's weights.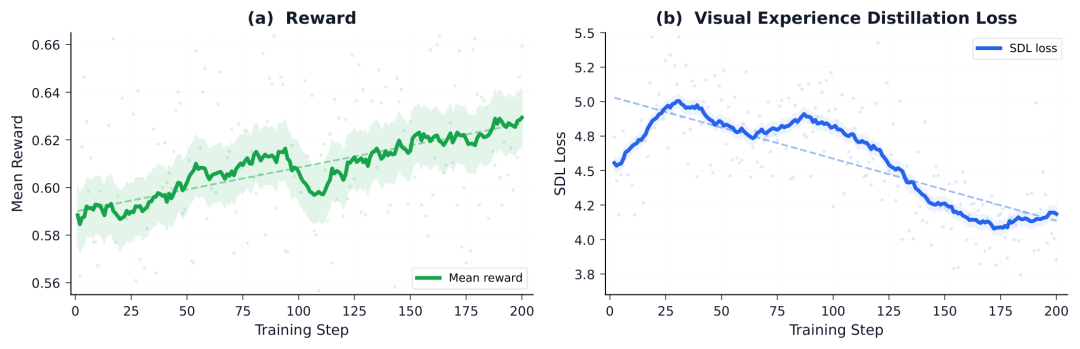
(a) The hybrid reward curve steadily rises with training steps; (b) The SDL reverse KL loss gradually declines. Simultaneous improvement of both signals indicates that GRPO provides trajectory-level signals of "which is better," while SDL provides token-level signals of "why it is better." Experiments: What Makes GenEvolve Truly Strong?
We divide evaluations into four parts: Unified Benchmark (GenEvolve-Bench) → Main Results → Ablation Studies → Cross-Benchmark Generalization (WISE) and Qualitative Comparisons.
1) GenEvolve-Bench: Organizing "Common Needs in Open-Image Generation" into a Unified Benchmark
We first constructed a unified evaluation benchmark, GenEvolve-Bench, covering two major tracks: Knowledge-Anchored / Quality-Anchored. To closely mimic real-world usage scenarios, the benchmark includes two input forms (text-only requests / text requests + user reference images) and maintains balanced distribution across multiple themes (entities, landmarks, products, events, text, layout, counting, attributes, anatomy, materials, aesthetics, creativity).
For evaluation, we use a strong VLM (Gemini 3.1 Pro Preview) to score results:
It assesses both visual detail correctness (factual grounding, reference consistency, verifiable details) and overall quality (composition, text, aesthetics);
It ultimately provides a KScore across four dimensions, weighted into a final metric.
More intuitively, this benchmark measures not "whether an image can be generated" but "whether the agent can properly orchestrate world knowledge, reference images, and generation knowledge like a qualified agent."
2) Quantitative Results: State-of-the-Art Open-Source Performance, Achieving Highest Scores with Strong Generators
On GenEvolve-Bench, we compared mainstream direct-generation baselines (Lumina-Image 2.0 / BAGEL / SD-3.5 / FLUX.1-dev / FLUX.2 Klein / Z-Image / Qwen-Image / Nano Banana Pro, etc.) and agentic baselines (Gen-Searcher, etc.). The results are clear:
When paired with open-source generators like Qwen-Image-Edit-2511: GenEvolve shows significant improvements on both Knowledge and Quality tracks, raising KScore from Gen-Searcher's 0.3493 to 0.3663 (Visual dimension from 0.1050 to 0.1338), with even larger gains on Knowledge-Anchored tasks that rely more on factual grounding. Paired with the stronger Nano Banana Pro: GenEvolve's KScore directly reaches 0.5739, achieving top scores across all four judge dimensions and both benchmark tracks. Even Nano Banana Pro's own "vanilla" direct generation (KScore 0.5298) lags behind "vanilla Nano + GenEvolve orchestration," demonstrating that the agent-side tool orchestration provides generator-independent improvements.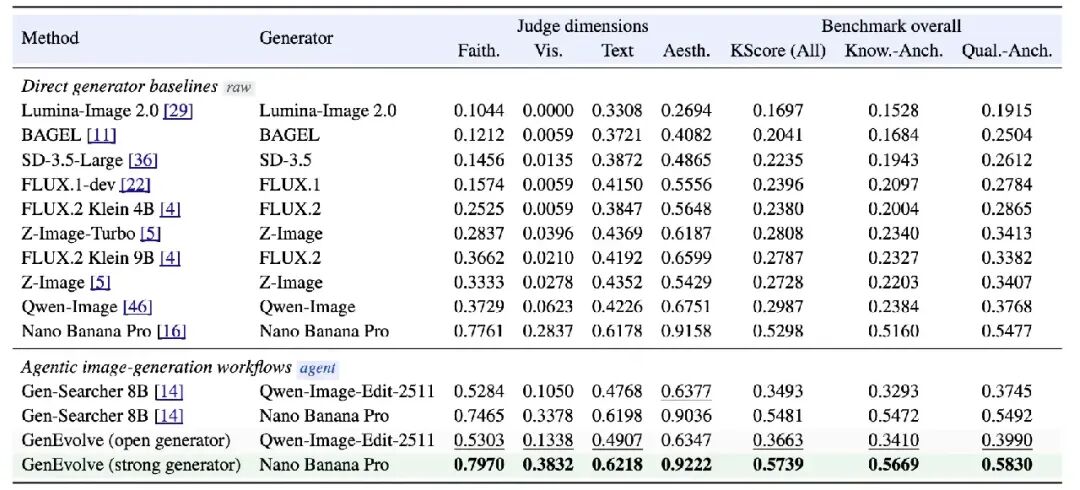
Main results on GenEvolve-Bench. GenEvolve + Qwen-Image-Edit-2511 represents the best open-source generator setup; GenEvolve + Nano Banana Pro achieves top scores in overall KScore, Knowledge-Anchored, and Quality-Anchored tracks.
From the complete table, several finer trends emerge:
Direct generators typically score well on overall aesthetics but struggle with Visual correctness when factual grounding, reference consistency, or precise layouts are required. When the base generator is fixed as Qwen-Image-Edit-2511, GenEvolve outperforms Gen-Searcher in incorporating search evidence, reference images, and generation skills into the final program. When the base generator is switched to Nano Banana Pro, the same Agent strategy continues to push the strong generator's limits, demonstrating that GenEvolve learns transferable orchestration strategies rather than prompt tricks for a specific renderer. 3) Ablation Studies: What Does Each Training Phase Contribute?
To confirm where the improvements originate, we conducted further component ablations. The results show that simply connecting Qwen3-VL to the same tool interfaces already outperforms vanilla Qwen-Image; SFT cold start further improves tool invocation and final program quality; GRPO provides trajectory-level rewards for another boost; while the complete GRPO + SDL achieves the highest KScore.
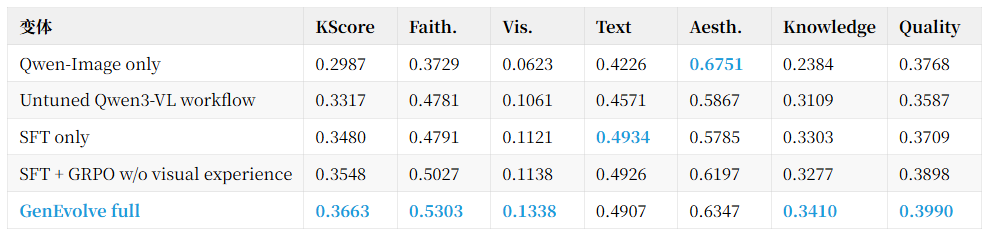
These results illustrate two key points:
First, knowing how to use tools and using them effectively are two different things. The Untuned workflow already has tool access, but without trajectory supervision and visual feedback, it is difficult to consistently produce high-quality prompt-reference programs.
Second, GRPO's scalar reward can inform the model which trajectory is better, but SDL provides more granular token-level credit assignment: it distills reusable experiences from the best/worst trajectories onto key action tokens, leading to continued improvements in the three most critical dimensions: Visual correctness, Knowledge-Anchored, and Quality-Anchored.
4) Cross-benchmark extrapolation: Outperforming GPT-4o on WISE
We additionally conducted extrapolation on WISE, a publicly available knowledge-intensive image generation benchmark:
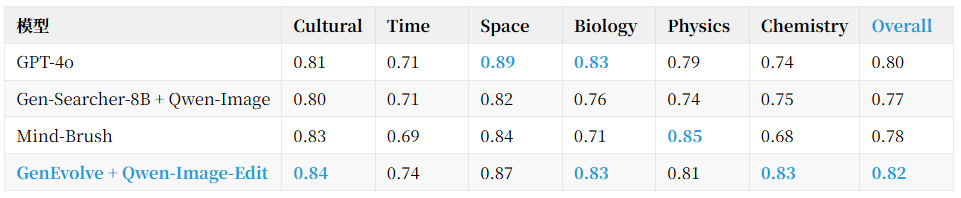
Note: GenEvolve underwent no in-domain fine-tuning on WISE, relying solely on cross-task transfer: using an 8B open-source policy + open-source Qwen-Image-Edit renderer, it surpassed GPT-4o on WiScore Overall; in chemistry, it outperformed GPT-4o by 9 percentage points.
5) Qualitative comparison: Why do we say it "orchestrates" rather than "flaunts tools"?
The two most typical types of failures in qualitative results are repeatedly observed in many baselines (including some commercial systems):
Knowledge-Anchored failure: The model either fails to search or the retrieved facts do not truly integrate into gen_prompt, resulting in identity dislocation, anachronisms, and structural proportion distortions. GenEvolve tends to extract key facts and explicitly incorporate them into the final program's ordinal bindings and hard constraints, ensuring that "adopted facts" truly appear in the image. Quality-Anchored failure: Many systems produce outputs that "look similar" in terms of text, counting, and layout but contain spelling errors or correct counts with collapsed layouts. GenEvolve proactively activates specialized skills (text_rendering / quantity_counting / spatial_layout / material_consistency, etc.) via query_knowledge and writes verifiable hard constraints into the program, making these dimensions more stable.
Qualitative comparison on GenEvolve-Bench. Orange: Relies on external knowledge; Blue: Relies on internal generation skills.
Extended gallery of GenEvolve + Nano Banana Pro.
Extended gallery of GenEvolve + Qwen-Image-Edit (using the same set of GenEvolve programs as the previous one, only switching the underlying renderer). References
[1] GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
Free access to technical exchange community
This is a high-quality AIGC technical community.
It covers various directions such as content generation/understanding (images, videos, voice, text, 3D/4D, etc.), large models, embodied intelligence, autonomous driving, deep learning, and traditional vision. This community is more suitable for documentation and accumulation, facilitating retrospection and review. Its vision is to connect hundreds of thousands of AIGC developers, researchers, and enthusiasts to solve specific problems encountered from theory to practice. It advocates in-depth discussions to ensure every question is treated seriously.

-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





