Musk Hurriedly Promotes 'American Coding Version of DeepSeek,' Comment Section: 'Not Even as Good as Free Alternatives...'
 06/01 2026
06/01 2026
 527
527
With DeepSeek and Xiaomi Aggressively Cutting Prices, and Anthropic and Google Rolling Out Innovations, Musk Can No Longer Stay Calm.
This morning, Musk made a high-profile repost on the xAI platform, attempting to drop a bombshell in the AI developer community.
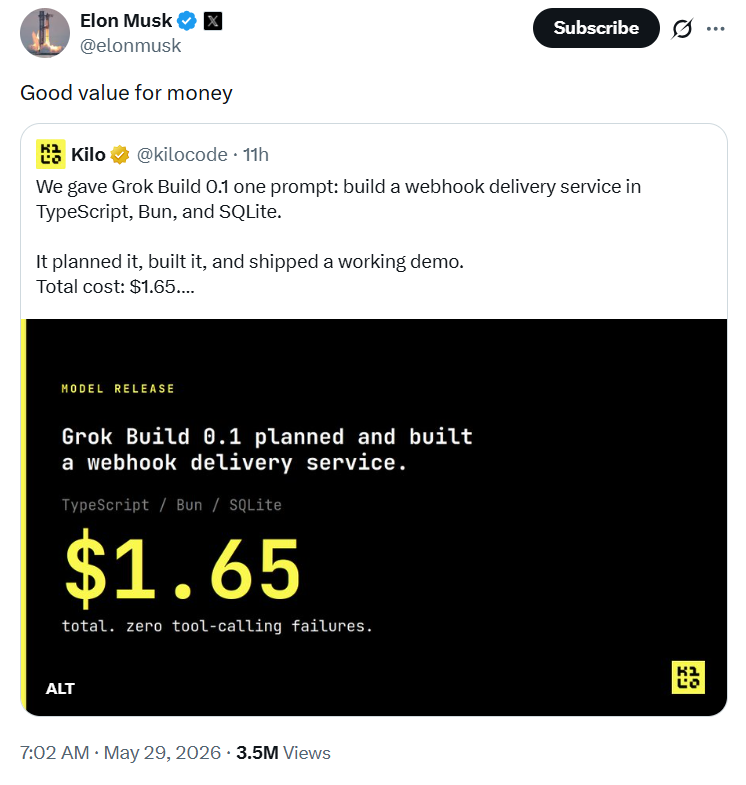
The incident began when the renowned agent platform Kilo Code released an extremely counterintuitive yet rigorous real-world test: Given only a vague and open-ended instruction, xAI's newly released coding model, Grok Build 0.1, was able to fully plan, write, and ultimately deploy a Webhook backend microservice with complex retry mechanisms, secure signature verification, and database persistence capabilities in an extremely short time.
What was even more eye-catching was the final bill—the entire process was completed seamlessly at a total cost of just $1.65. Musk himself liked and reposted it, leaving a highly provocative comment: 'Good value for money.'
Today, with GPT-5.5's pricing still exorbitant and Claude Opus 4.8's computational tax weighing heavily, xAI's Grok Build 0.1 operation inevitably evokes comparisons to China's approach of redefining AI coding cost-effectiveness through ultimate (extreme) pricing.
However, in the developer community, there's a saying: 'Musk's mouth, deceiver's prowess.' Is Musk truly creating an 'American Coding Version of DeepSeek,' or is it just another 'American Soybean Buns'? Don't celebrate just yet. Stripping away the veneer of real-world testing and considering the global AI competition landscape alongside insights from senior engineers' source code analysis, this is, in fact, a clever act of self-preservation and high-stakes gambling.
01 Self-Preservation Plan
To understand the positioning of Grok Build 0.1, one must look beyond Musk's countless daily tweets and instead examine the survival predicament of xAI's Grok series models.
Earlier, Google's release of Gemini 3.5 Flash was met with poor reception, earning it the nickname 'American Soybean Buns.' However, in my view, this title fits Grok even more aptly. After all, among the current global top-tier large models, xAI's position is quite awkward.
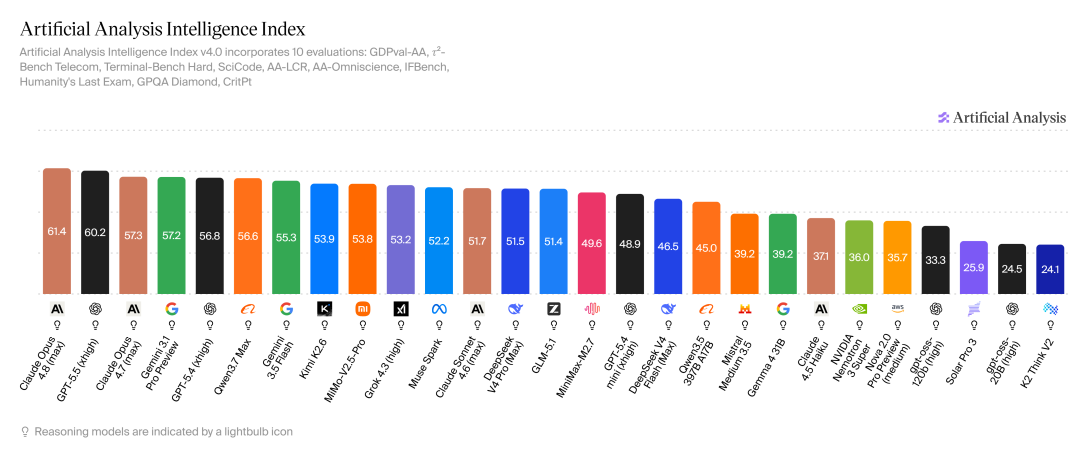
According to the latest ranking data from authoritative evaluation agency Artificial Analysis, while the Grok series models remain competitive in some parameters, they are now surrounded by the 'Sino-American Alliance' on the core Intelligence Index rankings.
Leaving aside the global top three—OpenAI, Anthropic, and Google—Alibaba's Qwen3.7 Max, Yuezhi Anmian's Kimi K2.6, and Xiaomi's recently discounted MiMo-V2.5-Pro have all comprehensively outperformed Grok in multiple benchmark tests.
In the more specific fields of Coding and Agentic capabilities, xAI's performance is even more lackluster, having long been pushed out of the top ten and largely ignored in the developer community. Grok's only remaining stage is on the x platform, where it shines with its multimodal capabilities and relaxed content restrictions—truly deserving of the nickname 'American Soybean Buns.'
In this situation of 'being outperformed in all aspects and having its ecosystem eroded,' Musk, fresh off a legal defeat against OpenAI, felt the pressure and decisively chose a very clever strategy: copying the playbook of Anthropic, xAI's partner and OpenAI's biggest rival, by pursuing a vertical programming specialization route.
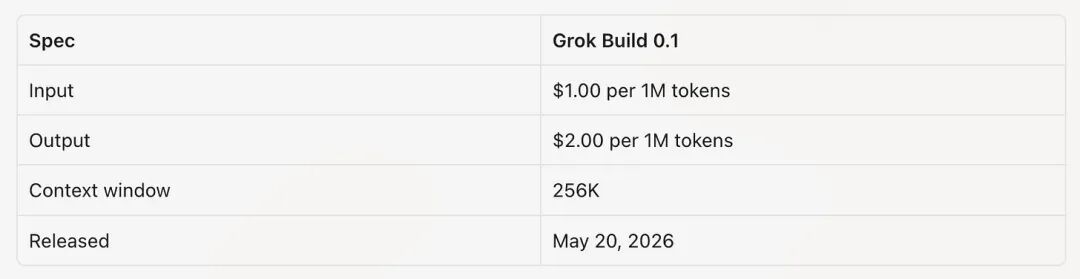
Grok Build 0.1 is the first product of this approach. Its pricing is highly aggressive: $1 per 1M tokens for input and $2 per 1M tokens for output, less than one-tenth of GPT-5.5 and Opus 4.8's pricing.
Musk knows that developers worldwide share a common trait: extreme sensitivity to price and performance. He aims to reclaim xAI's rightful niche by offering 'trial-and-error freedom.' Even if a generated code doesn't work on the first try, it's no big deal to spend a few cents to rerun it. Thus, Musk is attempting to forcefully breach OpenAI's moat through this 'cheap labor' model, starting with the vertical niche of programming.
02 Good Value for Money
Objectively speaking, Kilo Code's real-world test did justice to Musk and Grok. It demonstrated not only code generation capabilities but also astonishing Agentic workflow logic—so much so that some seasoned backend engineers felt a twinge of professional crisis.
After reviewing Kilo Code's technical report, two key strengths of Grok Build 0.1 stand out:
First, architect-level planning depth.
This new model's approach aligns almost perfectly with that of a human architect—it refuses to act blindly and instead asks 'why' first.
'Build a microservice using TypeScript, Bun, and SQLite'—this is already an instruction from a technically savvy product manager. Yet, upon seeing this, countless programmers might already be groaning: the task is extremely open-ended, lacking strict architectural planning or specific requirements.
However, Grok performed like a seasoned architect with years of experience. Instead of immediately outputting code, it first conducted online research, deeply investigated industry standards on Stripe and GitHub, and posed multiple key architectural questions to the tester:

Kilo Code dubbed this the 'planning phase,' and the total cost of this phase is probably unimaginable to most: $0.17, accompanied by a report containing an ASCII architecture diagram, Drizzle Schema definitions, and a clear risk assessment.
This 'think before you act' approach is an essential professional quality of human engineers and a key technology that helps Grok avoid the 'irrelevant answers' problem common in early AI programming.
Second, extremely smooth self-correcting capabilities.
During the coding phase, Grok was able to output code at a fluent (smooth) rate of 120 tokens per second.
Moreover, when configuring the environment, it encountered Bun's ABI mismatch and Zod's type errors—issues that would traditionally require manual intervention in Vibe Coding. However, Grok autonomously diagnosed the errors, readjusted import paths, modified configuration files, and ultimately completed 26 engineering files in one go.
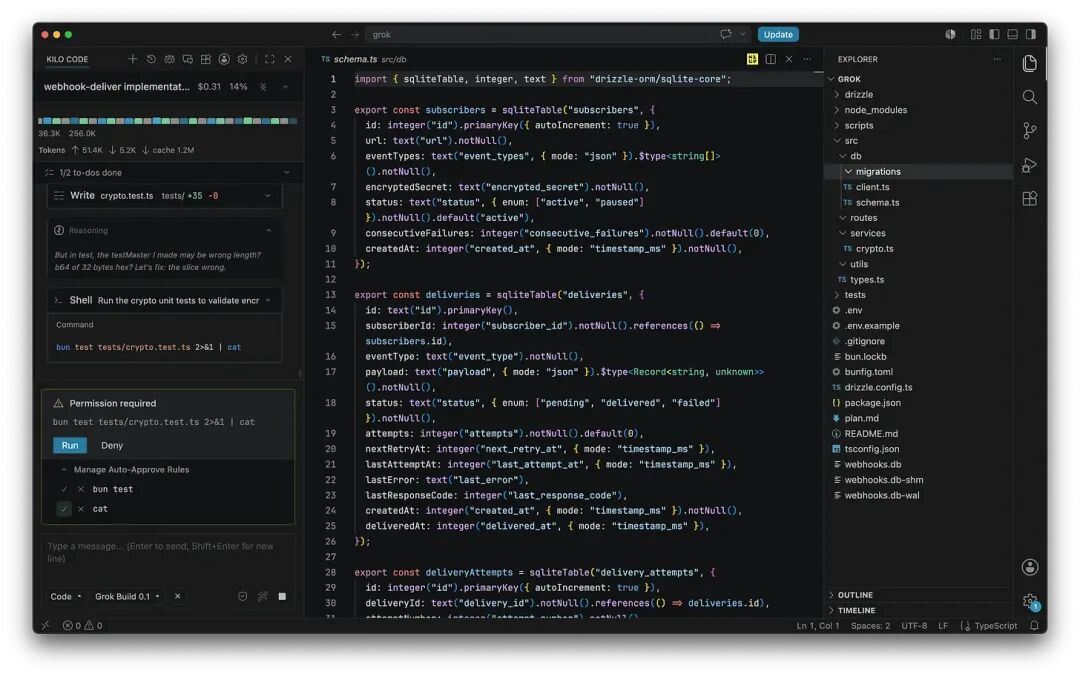
This is the feature Kilo Code highlighted: zero tool call failures throughout the process, at a cost of just $1.48. This seamless Agentic experience truly lives up to the name 'Build.'
03 Fatal Shortcomings
Just as people were preparing to celebrate the productivity unlocked for a few dollars, sober voices on social platforms and tech communities delivered a harsh blow to Musk.
Clearly, Musk is attempting to redefine the cost-effectiveness of AI coding.
Grok Build 0.1's low pricing is based on comparisons to expensive alternatives like GPT-5.5 and Opus 4.8. However, when viewed globally, the limitations of this low-price marketing strategy become apparent. In the comment section of Kilo Code's technical report, netizens directly criticized:
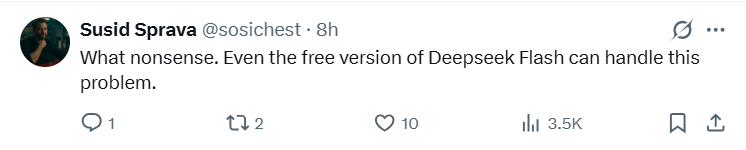
'This is nonsense. Even the free version of DeepSeek Flash can handle problems of this scale.'
The tech community Linux.do also reacted unfavorably, describing the model as 'unproactive and poorly understanding.'
This reveals an awkward reality: Musk's perceived 'bargain prices' do not hold an absolute generational advantage over the already rock-bottom prices of Chinese large models.
My consistent viewpoint remains unshaken: in today's AI competition landscape, models must either achieve performance leadership or ultimate (extreme) cost-effectiveness. Models stuck in the middle ground hold little practical value.
An even more fatal shortcoming is the context window, which is only 256K.
In an era where long-context models are proliferating and 1M windows have become standard for complex tasks, 256K seems woefully inadequate—even laughable. This means that while Grok excels at 'building projects from scratch,' it struggles to incorporate sufficient historical context in real-world projects with hundreds of thousands of lines of code. The result is frequent hallucinations, poor instruction-following, and lack of proactivity.
Meanwhile, Musk's marketing strategy for this model release still relies on 'refusing benchmarks and relying solely on showcasing results.' However, a year ago, Grok Code Fast 1 faced frequent criticism. While trust in third-party evaluation agencies and benchmark test results has indeed waned, as previously stated, benchmarks represent the 'passing grade,' not the 'excellence grade.' A release lacking third-party testing support inevitably raises suspicions of survivorship bias and excessive packaging.
04 Source Code Analysis
Also in Kilo Code's comment section, a comment urged everyone to remain vigilant:
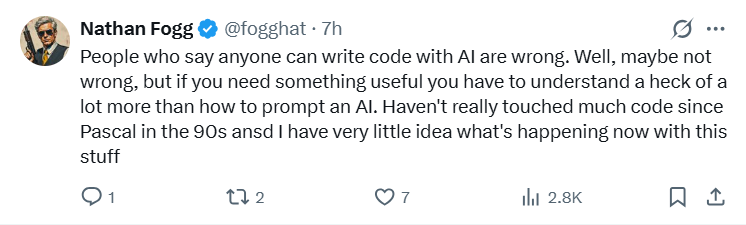
'Anyone who says AI can write code for anyone is wrong. If you want something useful, you need to understand far more than just prompts.'
Delving into the source code generated by Grok Build 0.1 for just a few dollars reveals not only a productivity leap but also a security vulnerability gamble.
While Grok's code engineering structure is highly standardization —even thoughtfully configuring SQLite's concurrent WAL mode and non-destructive retry mechanisms—professional code reviews still uncovered several critical bugs:
1. In the Webhook's most critical signature comparison link (part), Grok defaulted to using ordinary string checks instead of the anti-timing-attack crypto.timingSafeEqual. To hackers, this is akin to leaving the door wide open.
2. When querying interfaces, Grok inadvertently exposed the encryptedSecret field, which should have been securely stored. Despite being encrypted, this practice completely violates the security specifications it set in its own README.
3. Grok wrote 14 basic unit tests but failed to provide effective solutions for complex business logic such as automatic pause mechanisms and retry loop integration tests—avoiding the hard problems.
This serves as an extremely valuable wake-up call for AI developers and development enterprises worldwide, confirming two things:
First, AI will not eliminate programmers; it will only force them to become more stringent 'technical reviewers.' If developers truly believe they can write million-dollar architectures through text descriptions alone, the costs saved by using Grok for a few dollars will inevitably transform into thousands or even millions of dollars in security patches and system Refactoring (reengineering).
Second, zero-barrier coding does not mean everyone can become a programmer, does not mean developable applications can be created, and certainly does not mean commercial value can be realized. Suppose there is an outsider who knows nothing about program development but is enthusiastic about the term AI Coding. In that case, they would likely be unable to understand any of the aforementioned Grok vulnerabilities, let alone fix and improve them. Yet, these bugs are precisely what must be eliminated to achieve commercial value.
05 Conclusion
Overall, the release of Grok Build 0.1 and Kilo Code's real-world test represent an extremely successful publicity stunt for xAI.
It precisely targets developers' seemingly unrealistic fantasies of 'cheap, easy-to-use, engineering-architecture-aware, and self-debugging' tools, proving that Musk does indeed have a fighting chance in the vertical programming field. For foreign developers needing to quickly produce prototypes and validate logic, it is currently the most handy tool available.
However, there is still a long way to go if it aims to become the 'American Coding Version of DeepSeek' or reshape the global coding model rankings.
In the second half of the global AI competition, where the deep waters are being navigated, price wars alone cannot permanently maintain a moat. The ability to handle ultra-long contexts, accurately Refactoring (reengineer) complex legacy code, and strictly adhere to security baselines while generating code are the keys to xAI's potential turn the table (comeback) against the top three.
Musk has fired the first shot, but the bullet still needs to fly for a while.
At least for now, even if a need is solved for just a few dollars, users must still sit back down at their computers and carefully review every line of code to ensure hackers cannot exploit any loopholes.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





