What Signal Does Alibaba's QianWen Embarking on Embodied AI Send?
 06/02 2026
06/02 2026
 579
579
Over the past two years, the form of AI has undergone rapid transformation. From text models capable of writing poems and code, to image models that can generate and edit images, and then to visual models that produce lifelike videos, AI's ability to perceive the world has begun to infinitely approximate that of humans.
The advent of the intelligent agent era has made people realize that AI cannot merely be a dialog box on a webpage but must manipulate computers to complete tasks. Nowadays, AI companies have formed a covert yet vast consensus: the ultimate form of AI cannot be confined to the screen but must extend into the physical world.
The term 'Embodied AI' was rarely heard last year, yet now, 2026 has been hyped as the inaugural year of 'Embodied AI'.
To secure an early ecological position and avoid being outpaced by competitors, Alibaba's Tongyi Qianwen team has officially submitted its first answer in the field of embodied AI: Qwen-VLA.

In fact, this is another clear manifestation of Alibaba's strategy of 'emphasizing ecology + comprehensive coverage.' VLA, which stands for Vision-Language-Action, not only marks Qianwen's entry into the embodied AI track (Chinese term meaning 'track' or 'field'), but also sends a strong signal to the industry: Alibaba aims not to perform 'bug fixes' for individual robots but to create a foundational model that governs all scenarios.
01 The Robotics Industry is Calling for a 'Qin Shi Huang'
Before dissecting the hardcore technology of Qwen-VLA, it is essential to first understand the commercial pain points it attempts to address.
The current robotics industry generally faces severe fragmentation issues. During product launches, companies inevitably have to answer the question of which field (Chinese term meaning 'field' or 'domain') embodied AI will prioritize for implementation, with possible answers being home use or manufacturing. However, these answers are too broad. In actual demonstrations, we often only see home robots folding clothes and industrial robots sorting items.
In other words, a robot that folds clothes cannot sweep the floor or chop vegetables, and a robot that sorts items cannot tighten screws. Robots from different brands require separately customized algorithms to cover a few additional niche application scenarios.
From a technical perspective, this clearly contradicts the concept of Artificial General Intelligence (AGI).
From a commercial logic standpoint, this 'specialized machine for specialized use' model directly results in extremely high research and development as well as delivery costs, completely failing to benefit from the economies of scale in the era of large models. As long as the marginal costs of the system cannot be reduced, the vision of robots entering every household will remain mere armchair strategist (Chinese idiom meaning 'empty talk' or 'theoretical discussion').
Qwen-VLA's ambition lies precisely here: it aims to be the 'Qin Shi Huang' of the embodied AI field, achieving 'standardized cart tracks and unified written language.'
Upon closer inspection, this approach is almost identical to Alibaba Qianwen's strategy for large language models: although its flagship model may not match the performance of top foreign models, its open-source models of varying scales have become the most mainstream foundational models globally. Even Anthropic's newly released Opus 4.8 has been found to possibly have distilled from the Qwen series models.
Returning to the field of embodied AI, within its architecture, different components such as desktop robotic arm grasping, dual-arm coordination, and visual language navigation are unified and abstracted into the same underlying mathematical problem: predicting the next continuous action trajectory to be executed under specific conditions of visual observation, language instructions, and robot morphology.
This means that a single general strategy model can span multiple hardware platforms with different forms. Once this 'general unification' approach succeeds, the reuse rate of robot software will increase exponentially, which is Alibaba Qianwen's breakthrough point for commercial implementation in the field of embodied AI.
02 The 'Brain + Cerebellum' Technical Approach
Having clarified the commercial logic, we can delve into the technical aspects.
Embodied AI represents a more advanced form of AI than existing large language models and intelligent agents, with interaction with the physical world becoming a fundamental skill it must possess. Therefore, having the model learn in a simulated world becomes an indispensable step.
Currently, there are two primary technical routes for world generation in models: one relies on video generation to reconstruct the world, such as OpenAI's Sora and Google's Genie, while the other relies on 3D spatial generation to explicitly model the world, such as Li Feifei's World Labs.
However, Alibaba Qianwen's Qwen-VLA did not continue to explore along these established paths but instead chose a fused route of 'VLA unified strategy model + diffusion action generation + simulated reinforcement learning.'
None of these three professional terms are newly proposed concepts, but this route has not been attempted before. Existing VLA models primarily focus on 'predicting what the next frame will look like,' whereas Qwen-VLA explicitly states that, compared to visual prediction, it emphasizes generating action signals that intelligent agents can directly execute. In other words, it does not predict future frames but directly outputs intuitive physical parameters such as joint angles and chassis direction.
In terms of architecture, Qwen-VLA follows bionics to design a framework similar to the collaboration between the human brain and cerebellum:
The brain is responsible for cognition and understanding. It uses the Qwen3.5 multimodal model as its center (Chinese term meaning 'hub' or 'core'), which needs to comprehend the environment and understand complex human language instructions, even accurately judging spatial relationships, such as instructions like placing an object of a certain color next to another object of a different color in the demo.
The cerebellum is responsible for controlling fine movements. The Qwen team abandoned traditional output heads and instead connected an action decoder based on a diffusion model with 1.15 billion parameters. This is indeed the most cutting-edge approach in the current AI industry because robotic arm movements must be smooth, continuous, and high-frequency, and diffusion models inherently have advantages in generating such fine-grained continuous trajectories.
After determining the aforementioned architecture, the focus shifts to the training phase. As is well known, training multimodal models like VLA is not on the same level of difficulty as large language models. Therefore, Qwen designed a textbook-like four-stage training method:
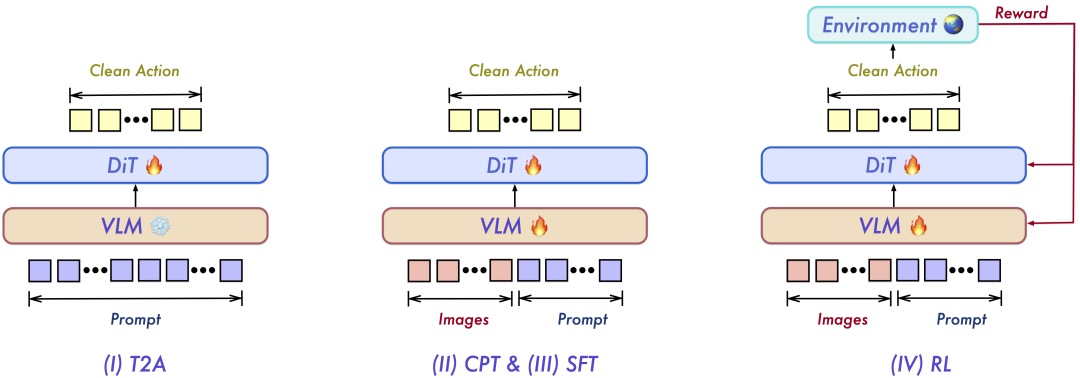
1. T2A
As the name suggests, this stage involves pre-training from text to action, treating actions as a 'decompression' of language. During this phase, the model does not even need to interact with images but simply builds a series of 'muscle memories' for action trajectories in the cerebellum by reading language instructions like 'pick up the cup,' which are action priors.
2. CPT
This stands for continuous multimodal pre-training. The model is only allowed to 'open its eyes' after acquiring 'muscle memory' because it must not only strictly follow instructions but also understand the real scene in front of it. At this step, the cognitive large model connects with the action decoder, and the 'pick up the cup' action learned with closed eyes corresponds to the specific position, shape, and color of the cup in front of it, achieving visual alignment.
3. SFT
This refers to supervised fine-tuning. The model's ability to 'pick up the cup' proves that it has the basic capability to perform tasks. The next step is to teach it how to work like a human. Researchers select the most standard and highest-quality real human operation videos for the model to learn from step by step, such as folding clothes or cleaning up bowls and chopsticks. This so-called imitation learning aims to teach the model the most standard actions.
4. RL
Reinforcement learning is a paradigm for training all models. Simply watching videos and imitating can never solve a real and frequently occurring problem: the tendency to 'rote memorize.' If the cup is placed slightly askew or the hand slips, the result could be a floor full of broken glass. The model also would not know how to correct itself and would simply crash. Therefore, the model must undergo training in a virtual simulation environment with simple rules: the standardness of actions is not important; completing the goal will be rewarded. Only in this way can the model learn to correct itself through countless failures.
03 Barren Data Nutrients
Moravec's Paradox tells us one thing: actions like walking and grasping, which are extremely simple physical tasks for humans, are incredibly difficult for AI. The core reason has been widely acknowledged: a severe lack of data.
There are trillions of texts on the internet, but the parameters of physical actions in the real world are infinitely close to zero.
The law of scale also applies in the field of embodied AI. To feed Qwen-VLA, Alibaba Qianwen demonstrated strong financial and engineering capabilities by constructing an extremely complex and vast data source:
Among them, 74.2% of real robot teleoperation data accounts for the absolute majority. In addition to globally open-source robot datasets, Alibaba also internally collected over 1,000 hours of real robot teleoperation data, which are trajectory data left behind by humans wearing devices to control robots. These data can be transformed into the most precious and authentic physical parameters.
Meanwhile, Alibaba Qianwen did not abandon the path of video generation, with human first-person video data accounting for 6%. This type of data is relatively easier to obtain; humans wear cameras to work and then retain stable video data. Although there are no directly usable parameters for robots, the model can still learn the action logic of human hands from this data.
The biggest advantages of the aforementioned two types of data are their high quality and effectiveness, but they rely on human operation, which leads to persistently high costs.
To address this issue, large-scale synthetic simulation (3.7%) has become the preferred choice for embodied AI companies. This approach not only reduces costs but also significantly accelerates data accumulation. The Qwen team has used simulation engines to automatically generate over 8 million trajectories of physical collisions, covering various rare long-tail scenarios.
Finally, there is general image-text data (8.5%). To ensure that the model does not forget the most basic common sense and cognition in practical application scenarios, conventional multimodal question-answering data is also included in the dataset.
04 Out-of-Distribution Generalization Capability
The criteria for evaluating the strength of a model used in embodied AI are entirely different from those for large language models and intelligent agents. No matter how well it performs in preset, controllable environments like laboratories, it may still suddenly crash when encountering unfamiliar objects.
This is also where Qwen-VLA shines. It not only matches or even surpasses several simulation-exclusive models like ABot-M0 and StarVLA but also demonstrates extremely strong out-of-distribution generalization capabilities and dynamic scene zero-shot capabilities on real dual-arm robots.
Simply put, it can grasp objects it has never seen before. During training, the model may have only seen grasping wooden blocks and cups, but during testing, the objects become toy ducks and sunglasses. As long as the user gives accurate instructions, the visual brain can accurately locate the object, and the cerebellum can quickly plan actions and successfully grasp it.
At the same time, in the real world, the lighting and background can change at any time, but the model is not affected. Changing the background to a color never seen during training or to a high-brightness/low-brightness environment, the model can still perform extremely precise actions without being disturbed by background noise.
The most challenging scenarios involve dynamically moving objects, where Qwen-VLA demonstrates its greatest advantage: zero-shot attack. In the DOMINO dynamic manipulation evaluation, for objects in constant motion, Qwen-VLA can adjust its trajectory in real-time, accurately intercept, and complete the operation without any special fine-tuning, even surpassing a large number of traditional models specifically optimized for dynamic scenarios.
05 How Far is it from True AGI?
Setting aside these exciting achievements and re-examining Qwen-VLA with an objective eye, everyone should recognize one fact: this can, at best, be considered an early exploration, and embodied AI is still far from true implementation.
The so-called 'inaugural year of embodied AI' is entirely a commercial marketing ploy. The Qwen team honestly points out several limitations of the model in their paper, which are actually issues faced by embodied AI companies worldwide:
First, the volume of action data is still too small. Compared to text pre-training data measured in terabytes, the current physical action data is far from sufficient in scale and diversity. When faced with extremely complex contact interactions, the model still lacks robustness.
Second, the optimization compromise of 'wanting both.' Against the backdrop of existing technical paths being far from AGI, VLA represents a commendable exploration thought process (Chinese term meaning 'approach' or ' thought process '). However, forcibly combining visual, language, navigation, and action generation for training necessitates confronting the optimization dilemma of conflicting goals. Some pure visual abilities may even experience performance degradation after introducing action training.
Third, the lack of tactile feedback results in empty performances. The implementation of embodied AI requires various physical contacts, yet current input still heavily relies on vision, lacking the deep integration of force feedback, tactile, and proprioceptive senses. Without solving the fusion problem of multimodal sensors, robots will never be able to work 'with their hands' like humans.
Fourth, long-duration tasks remain a pain point. Most existing evaluations involve short tasks lasting a dozen seconds. How to enable robots to autonomously plan and decompose steps during tasks lasting several hours and even automatically recover from failures remains an open challenge that cannot be directly borrowed from the experience of intelligent agents.
In short, transitioning from observing and interpreting to actively working represents a fundamental leap that cannot be achieved overnight.
The release of Alibaba's Qwen-VLA proves that the path of 'converging fragmented physical controls using a unified large model foundation' is entirely feasible.
Only when algorithms truly begin to sense gravity, friction, and spatial obstacles can the tide of artificial intelligence truly reach the shores of the physical world.
Reprint Authorization
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





