Search Will Enter the Third Phase of Its Lifecycle: Search as Code
 06/03 2026
06/03 2026
 600
600
By 2026, as large models transition from dialog boxes to intelligent agents, the requirements for search have undergone a qualitative transformation.
The most intuitive shift is that two search engine giants, both domestically and internationally, now prioritize AI-generated answers at the top of their search result interfaces, followed by various relevant links.
A deeper transformation lies in the fact that search results were previously intended for human consumption, with users sifting through a pile of web links as needed. Today, however, search functionality is primarily designed for large language models, requiring only concise text in return.
But is this the ultimate form of search? Perplexity has offered a negative response along with a landmark technical blog post, declaring that search will enter its third phase: Search as Code (SaC).
In Perplexity's tests, SaC not only outperformed OpenAI and Anthropic across the board in complex tasks but also achieved a nearly impossible 85% cost reduction.
While the data may seem unrealistic, the profound thinking behind the architecture is worth acknowledging.
01 The Dusk of Search
Since OpenAI introduced the large language model ChatGPT, the term 'search engine' has been mentioned increasingly less frequently. To understand SaC, one must first grasp why existing search architectures are no longer suitable.
As previously mentioned, both Google abroad and Baidu domestically were originally designed for humans. Human capacity for information reception and processing frequency has clear upper limits, necessitating only the most intuitive and fixed result search pages. This monolithic service model of 'input keywords → search engine black-box processing → return top N results' has unknowingly dominated internet information for decades.
After the emergence of large language models, Perplexity once led a wave of 'answer engines,' enabling models to integrate and refine content from multiple web pages, attempting to enhance model understanding, reasoning, and generation through optimized information density. However, fundamentally, the model remained a passive recipient of information at the end of a predefined unidirectional pipeline.
Yet, the sudden arrival of the intelligent agent era has transformed search users from humans to large language models, rendering the previous 'monolithic service' model an obstacle.
Today's intelligent agents, in a broad sense, go far beyond simply asking questions; they require practical computer operations to complete tasks. Within Perplexity's internal Perplexity Computer project, researchers found that a single complex research task might trigger hundreds or even thousands of retrieval operations within just a few minutes. This high-frequency, nonlinear demand directly forces traditional 'monolithic services' to confront three challenges that threaten their viability:
1. Coarse Context:
Large models are highly sensitive to context, yet traditional 'monolithic services,' to ensure information recall rates, often flood models with massive amounts of redundant information. This approach, akin to transporting dozens of tons of seawater to find a needle in a haystack, results in rapidly exploding context windows, translating into soaring inference costs and frequent hallucinations.
2. Failure to Leverage Domain Knowledge:
Cutting-edge models already possess profound 'search experience,' knowing which official channels to query for knowledge-intensive information rather than relying on third-party sources. However, under fixed API retrieval modes, the model's inherent insights cannot intervene in the underlying search retrieval logic.
3. Inefficient Dialogue Turns and Context Pollution:
Under traditional function calling (Function Calling) modes, intelligent agents must complete a cycle of 'model inference → trigger tool → receive results' for each retrieval, deduplication, and filtering operation. This not only accumulates delays but also fills the model's context with vast amounts of intermediate garbage information. Perplexity's data shows that truly useful information often gets drowned out in this process.
02 Deconstructing Search
While Perplexity's proposed Search as Code may sound abstract, its core idea is straightforward:
Enable models to orchestrate search code rather than call search interfaces.
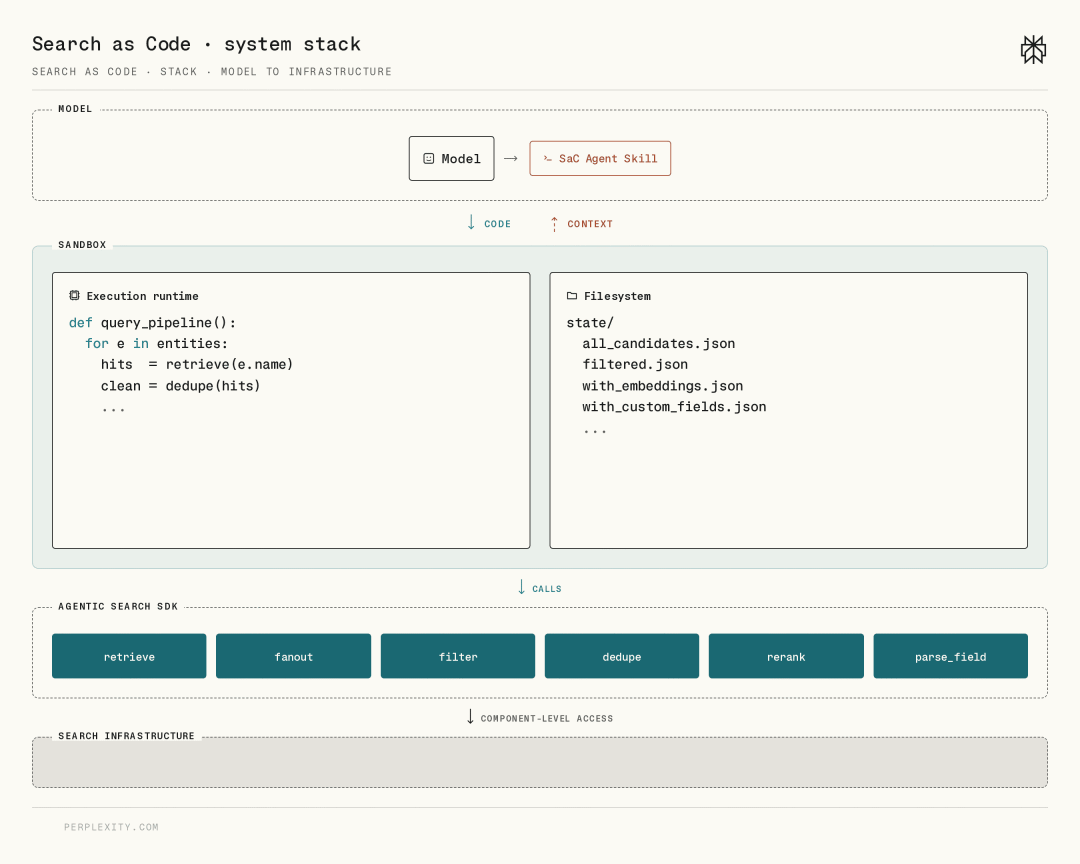
Building on this idea, Perplexity introduced 'Search as Primitives.' In computer science, primitives refer to foundational building blocks that cannot be further decomposed. SaC aims to dismantle the previously black-boxed search process into atomic components such as initial retrieval (retrieve), parallel query expansion (fanout), refined filtering (filter), deduplication (dedupe), and reranking (rerank).

To achieve these functions, SaC consists of three tightly coupled layers:
First is the model layer, typically employing a top-tier reasoning model as the 'commander.' Instead of generating keywords for text boxes, it produces complex Python code.
Next is the computational sandbox, providing an isolated, secure, and deterministic execution environment. Given the same input and code, output remains consistent, complementing the probabilistic generation of large language models. The sandbox handles operations like loops, retries, and data aggregation without requiring large language model intervention.
Finally, the atomic SDK represents the soul of the SaC architecture, offering models a set of 'specialized handles' for precise operations like retrieve, dedupe, and rerank. Rather than simply repackaging old APIs, Perplexity reconstructed the search stack, enabling the SDK to directly manipulate the internal state of the search system.
From the user's perspective, the rows of web links previously displayed during searches might have been ranked by keyword matching, timeliness, or authority. However, as long as the black box remained closed, the sorting logic remained unknown. Under the SaC architecture, models can access various detailed backend data and apply the most valuable search results based on specific task requirements.
03 The Game of Underlying Engineering
If these three architectural layers form the skeleton of SaC, then the engineering decisions embodied within the sandbox determine whether this architecture can operate stably in the real world.
When designing the execution environment, Perplexity did not blindly pursue high-performance metrics but instead delved into two highly representative technical trade-offs:
1. The Language Trade-Off:
When selecting the language for sandbox operations, the team faced a dilemma: Should they use Rust, known for its extremely high execution efficiency, or TypeScript, renowned for its strict typing?
Surprisingly, the team chose Python, the 'native language' of large language models. The rationale was Python's nearly unparalleled data processing ecosystem, exemplified by NumPy and Pandas. Meanwhile, large language models, during their pre-training phase, develop the strongest understanding and generation capabilities for Python code, significantly enhancing code generation quality.
2. The State Trade-Off:
The second decision concerned how intelligent agents should remember intermediate state data. When an intelligent agent executes long-duration tasks spanning hours, it inevitably generates vast amounts of intermediate retrieval results. How should this data be stored?
The team faced two distinct solutions:
REPL Mode (Interactive Interpreter): Similar to Jupyter Notebook, variables remain persistently in memory, accessible to the model whenever needed.
File System Serialization Mode (Serde): Requires the model to explicitly convert data into JSON format and write it to the sandbox's disk.
REPL mode appears more convenient but becomes a glaring pitfall when handling long-path tasks. As tasks progress, memory fills with numerous hastily defined temporary variables, leading to namespace pollution—a programmer's nightmare—causing confusion for the model in subsequent steps.
Therefore, Perplexity ultimately opted for the more cumbersome file system serialization approach. After processing data at each step, the model must adopt a 'declarative' and rigorous attitude, explicitly packaging, labeling, and storing data on disk. Undoubtedly, this represents an engineering 'strong constraint.' While it requires the model to write a few extra lines of code, it significantly enhances logical clarity and traceability for intelligent agents executing complex tasks.
04 Balancing Performance and Cost-Effectiveness
Perplexity's research did not stop at theoretical analysis; they not only released a new benchmark test but also established an evaluation system called the 'Cost-Performance Frontier.' This aligns with current mainstream AI evaluation systems, emphasizing cost-effectiveness over mere performance leadership.
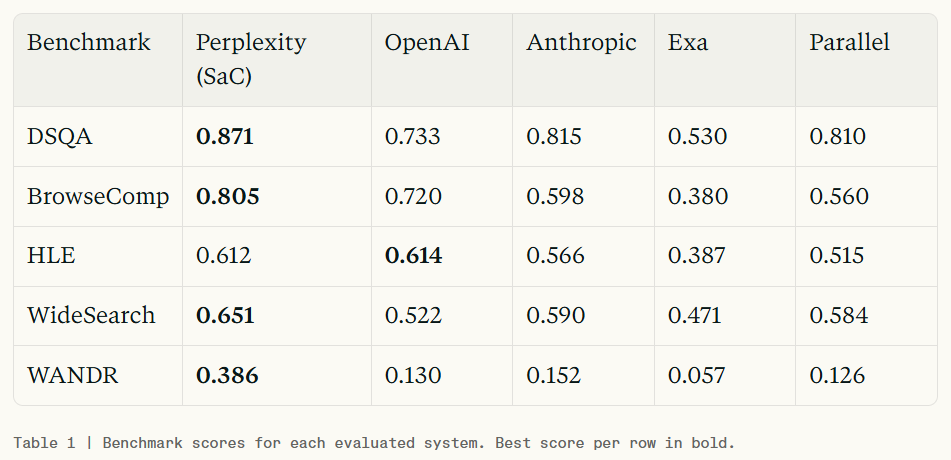
The WANDR benchmark, designed by Perplexity, specifically simulates complex, high-breadth professional research tasks.
In this benchmark test, SaC's performance nearly reached 2.5 times that of the second-place Opus 4.7. In other words, when facing complex tasks requiring cross-multiple information sources and lasting several hours, traditional 'conversational search' has completely failed, while SaC's code-driven logic demonstrates dominant efficiency.
Meanwhile, Perplexity redefined search cost-effectiveness.
They referenced an economic term here: the Pareto frontier, which refers to a state where no further optimization of one objective is possible without harming other objectives. Remarkably, SaC, under low, medium, and high reasoning intensity configurations, all miraculously lie on the optimal frontier.
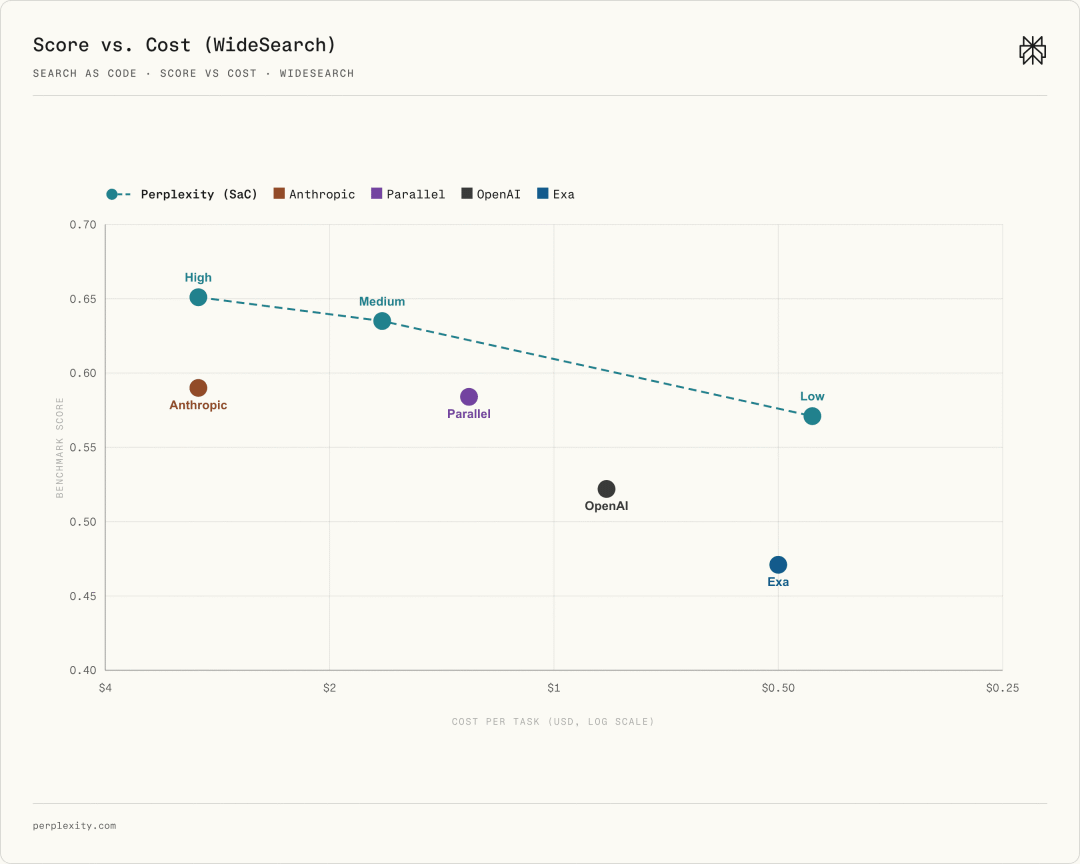
Under low reasoning intensity, its cost is lower than pure API retrieval while outperforming some competitors. Under medium reasoning intensity, for single-task costs below $1, the SaC architecture has achieved comprehensive superiority over other architectures.
Objectively speaking, since Perplexity's presented data all originate from its self-constructed evaluation system, it inevitably faces 'self-promotion' skepticism. However, more importantly, these outstanding data validate a shift in AI development patterns: search efficiency is transitioning from increasing model parameters to optimizing architectural orchestration.
05 The Future of Computing Architectures
The conclusion of Perplexity's technical blog post is a masterstroke, brimming with profound thought.
Search as Code is not merely a commercial slogan shouted by Perplexity; it reflects a grand transformation in software design.
Throughout the history of computer science, two distinct computing forms have endured:
One is deterministic instruction, running on CPUs, characterized by rigorous logic suitable for batch processing, sorting, and parallelization.
The other is token-space reasoning, a unique capability of large models, excelling at handling uncertainty, understanding semantics, and formulating strategies.
The true significance of SaC lies in its perfect fusion of these two computing forms.
Models represent probability, needing to decide 'what evidence is needed' and 'how to resolve contradictions'; while code and sandboxes are deterministic, handling vast and cumbersome I/O operations and logical filtering.
Perplexity even proposes a more cutting-edge vision: joint design. In the future, models may no longer 'learn' to write code but could co-evolve with SDKs during the training phase, directly understanding low-level search signals.
This technical blog post can be interpreted as a roadmap for all intelligent agent developers. If developers are still designing search plugins for intelligent agents, they are reinventing the wheel.
Search as Code posits that search should not be an endpoint but a transparent process freely manipulable by models. When 'Search as Code' becomes standard for intelligent agents, their upper limits will no longer be constrained by 'what they see' but by 'how they search.'
Perhaps this architectural revolution lies on the inevitable path toward AGI.
Reprint Authorization
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





