Why Is the Gemini Experience Becoming Increasingly Clunky? High-Quality AI Is Pricier, While Free Options Are Dumbing Down
 06/04 2026
06/04 2026
 409
409
Launched with a bang, only to steadily decline in intelligence during use.
Lately, if you judge solely by Google's promotional materials, you'd likely assume Gemini is practically unbeatable.
For video creation, there's Omni; for image generation, Nano Banana. Gemini 3.5 Flash outshines 3.1 Pro, and Gemini Spark can even automate tasks for you. From the launch event to the official blog, Gemini appears to be a versatile powerhouse, excelling in almost every aspect.
Indeed, Leitech also sang its praises when covering Google I/O some time ago. However, after actually using it these days, Xiaolei increasingly finds Gemini 3.5 Flash somewhat underwhelming.

(Image source: Google)
The letdown isn't in its benchmark scores or basic capabilities. On the contrary, many of its features still rank among the industry's best.
The issue arises when these touted new features are put to the test in everyday use. There's always an indescribable sense of awkwardness. You know it's powerful, but it just doesn't feel as satisfying to use; you're aware that many features are available, yet you never quite feel like you're utilizing them to their fullest.
This sense of disconnection isn't unique to Gemini recently; it's a trend in the large model sphere: manufacturers flaunt the upper limits of their capabilities, but users are left grappling with the actual experience. The former is increasingly impressive, while the latter doesn't necessarily keep pace.
And Gemini 3.5 Flash might be the clearest embodiment of this contradiction, with too many flaws to overlook.
Let's start with the most glaring issue.
Quotas.
Google quietly overhauled the quota rules for member subscriptions on the eve of I/O 2026, shifting from a fixed number of messages to a compute-based quota system.
In simpler terms, Gemini used to count interactions separately, with usage of image, video, audio, and text large models being independent of each other and resetting every 24 hours.
Based on past experience, Pro members could generate 5 videos and 50 images per day, with text usage seemingly limitless.
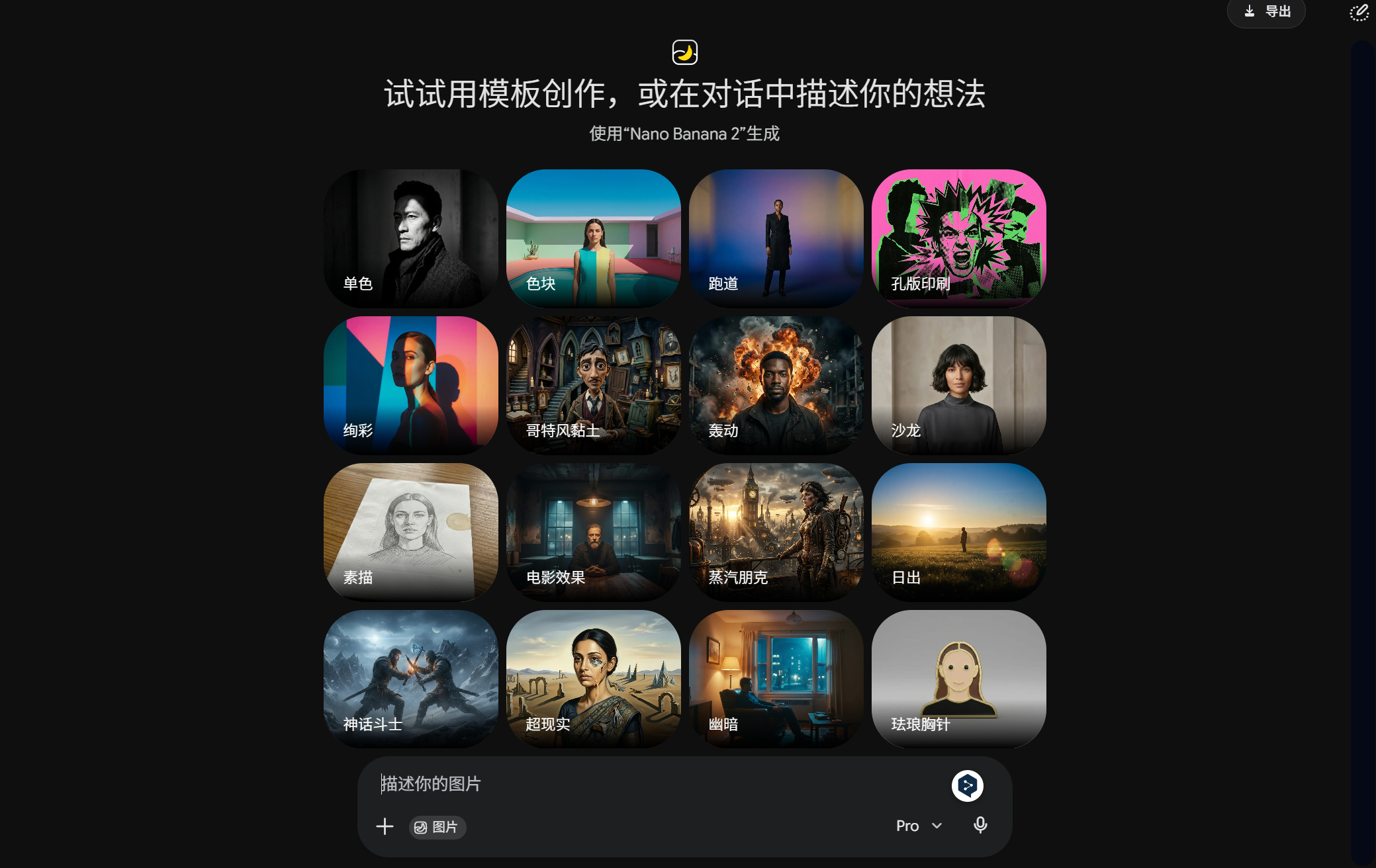
(Image source: Leitech)
After the change, Google imposed both a weekly limit and a temporary limit that resets every five hours.
Now, all task usage is calculated based on Token consumption and other factors. If the model engages in more complex thinking, even if the reply content remains unchanged, it costs more than before.
The question then becomes: how am I supposed to know how much computing power a task will consume for the model?
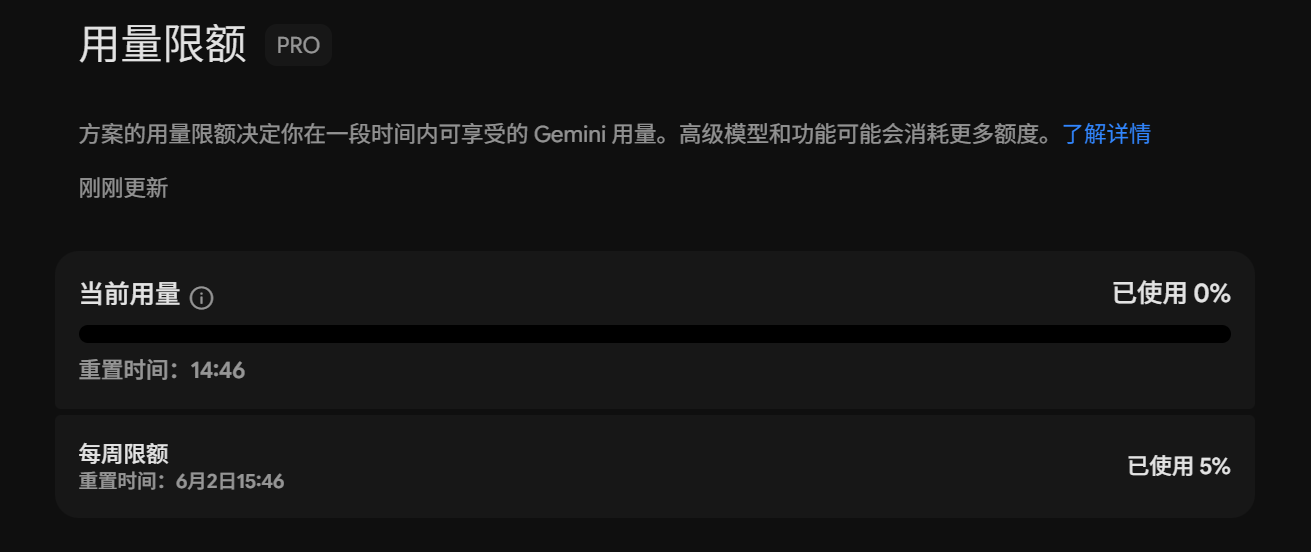
(Image source: Leitech)
Not only that, but the various previously categorized functions are now all lumped together under this usage quota. Whether it's video, image, in-depth research, or Agent, if one function depletes the quota, you're left unable to do anything else for the next few hours.
From personal experience, generating a video with Omni Flash consumes about one-third of the Pro subscription quota. If you want to modify the video, it uses at least half of the Pro subscription quota—it's just not sustainable.
What impacts the experience even more than quotas is routing.
This isn't just a personal gripe; many users have encountered similar situations recently. One minute, it's smoothly generating images, but then, in the middle of a chat, Gemini suddenly claims it can't generate images and insists it's just a text model, incapable of handling such tasks.

(Image source: Leitech)
The most amusing part is that sometimes it only provides text without any accompanying images.

(Image source: Leitech)
This would be understandable if it happened occasionally, but when it becomes a frequent occurrence, users are left scratching their heads, unsure whether a feature has failed or if the model has incorrectly switched modes.
There are similar issues at the capability level.
Gemini 3.5 Flash always gives the impression that it can handle tasks, but often not reliably. For the same math or reasoning problem, sometimes the answer is impressive, but if you ask again a few hours later, the result might be completely different.
I've tested several classic logic problems, and often the initial analysis process is sound, with a seemingly complete chain of reasoning, but then, at the last step, there are often some inexplicable mistakes. The most ridiculous part is that it's particularly confident, maintaining the same tone even when the answer is wrong.
As for simpler calculation problems, it still makes mistakes.

(Image source: Leitech)
I know these issues might seem trivial for casual chatting, but when it comes to learning, work, or even programming scenarios, the impact is significant.
If the previous issues were at the experience level, the deeper problem actually stems from Google's recent product and pricing strategies.
In my opinion, the story Google loves to tell most this year is about Agent.
From the launch event to official promotions, almost all the focus is on Gemini Spark. Automatically searching for information, organizing it, executing tasks, and even helping users complete cross-app operations—it does sound very futuristic and aligns with everyone's imagination of an Agent.
The issue is, you need an Ultra subscription to use Gemini Spark, with prices starting at $99.99 per month and the highest-tier subscription at a limited-time price of $199.99 per month (approximately 1352.98 yuan).
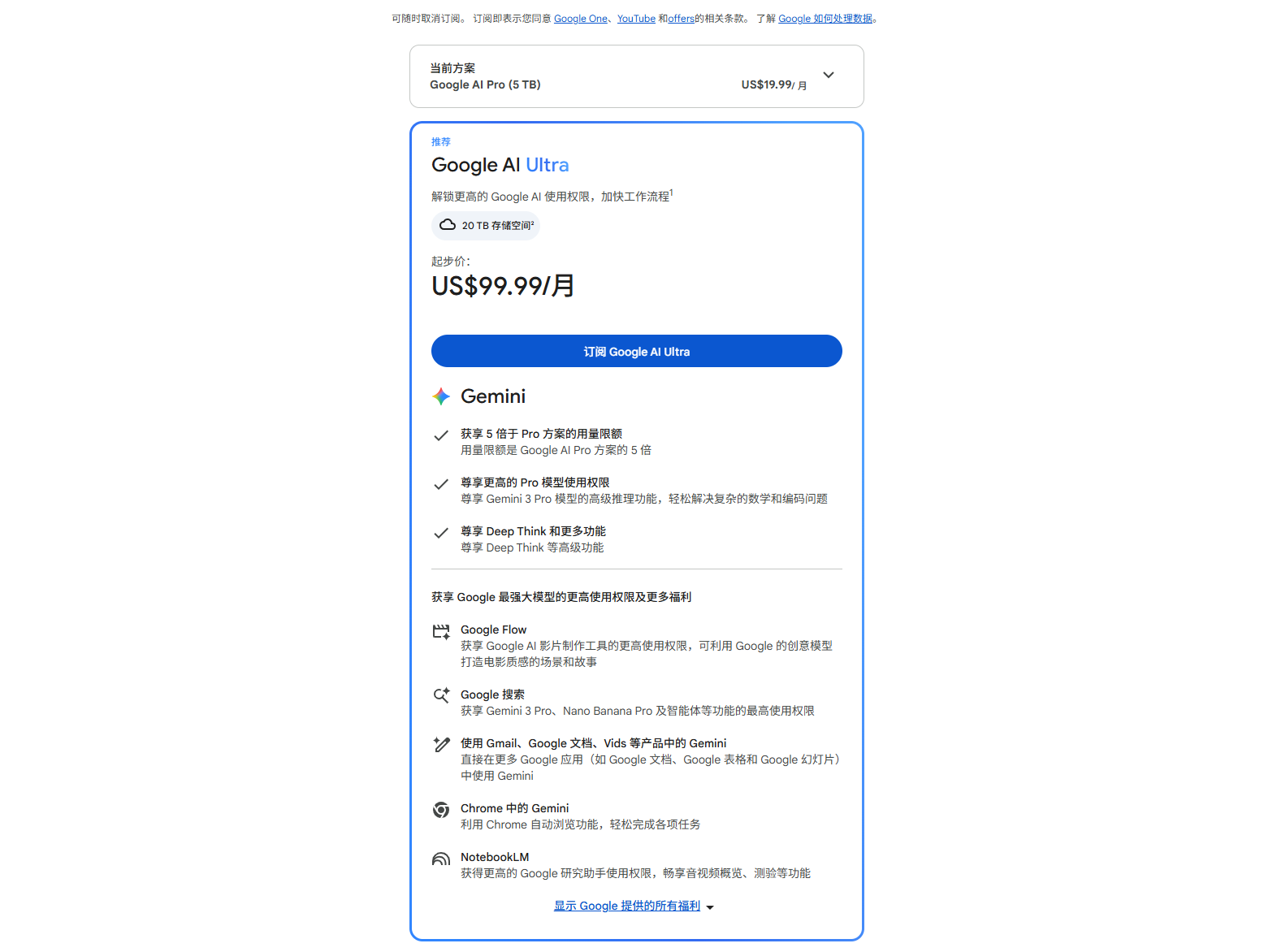
(Image source: Leitech)
Keep in mind, OpenAI and its highly regarded Codex only require $20 per month to enable.
So, an interesting phenomenon arises: when watching the launch event, everyone thinks Gemini is unbeatable, but when opening the product, the first thing they see is an upgrade button.
This disconnect actually affects reputation more than missing features. Because users know the capabilities exist and that the effects are good, but they just can't access them themselves.
As for programming prices, they're not exactly cheap either.
Keep in mind, at I/O 2026, Google CEO Pichai emphasized the cost advantages of Gemini 3.5 Flash quite a bit.
According to the official pricing, Gemini 3.5 Flash charges $1.5 per million input Tokens and $9 per million output Tokens. In comparison, Claude Opus 4.7's API is priced at $5 per million input Tokens, while GPT-5.5 Pro directly charges $30 per million input Tokens.
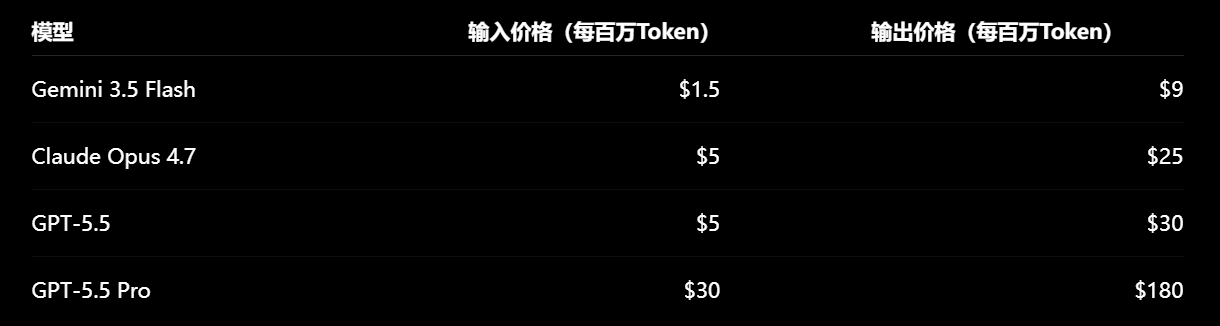
(Image source: Leitech)
Just looking at the price list, it does seem significantly cheaper, even hinting at volume-based profitability.
But price lists are just for show; for people who actually use models, what matters more is how much it costs to complete the same task.
Artificial Analysis conducted a study in their Agent review, finding that Gemini 3.5 Flash costs over $1500 to run a full set of tasks, while Gemini 3 Flash costs less than $300—a difference of over five times. Even compared to Gemini 3.1 Pro, Flash's overall cost is much higher, even more expensive than GPT-5.5.

(Image source: Leitech)
What's the problem?
The answer is simple: it talks too much.
In Agent testing, Gemini 3.5 Flash averages nearly 50 rounds of dialogue to complete a task, while many competitors finish in around twenty rounds. Don't underestimate this difference; each new dialogue requires the model to reread the previous history, and the more rounds, the faster Tokens are consumed.
It's like taking a taxi—the per-kilometer price might be cheap, but if you drive around the city three times, the total fare at the end will always be what the user sees, not the base fare.
In the end, I don't think Gemini 3.5 Flash is a failed model.
In fact, it still ranks among the industry's best. Its multimodal capabilities are still strong, video generation is still impressive, and its search integration capabilities remain Google's forte. Many of its individual features are still highly competitive in the industry.
The issue lies in the forcibly reduced usage quotas and the frequent intelligence drops due to computing power shortages.
(Image source: Leitech)
No matter how Google promotes it, ordinary users don't care about rankings or how much computing power Gemini 3.5 Flash saves; they care about whether tasks can be completed smoothly, whether results can be output stably, whether they don't have to navigate complex rules, and whether they don't have to worry about the quota suddenly running out.
This is why more and more people are starting to long for certain older model versions recently.
Keep in mind, about half a year ago, Google AI Studio still offered free users 50 daily interactions with the Pro model—a far cry from the current situation.
For Gemini, the greatest hope for the future still lies in Agent.
After all, Google has the industry's most comprehensive ecological resources. If it can truly integrate search, email, calendar, documents, and the Android system in the future, allowing Agent to help users complete more real-world tasks, it still has the opportunity to establish advantages that other manufacturers will find hard to replicate.
But at this stage, Xiaolei's evaluation of Gemini 3.5 Flash obviously won't change.
Google Gemini Large Model Agent AI
Source: Leitech
All images in this article come from: 123RF Royalty-Free Image Library Source: Leitech
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





