Model Crisis: Navigating the Challenges of AI Evolution
 06/04 2026
06/04 2026
 576
576
Recently, through interactions with AI developers and leaders of enterprise intelligence projects, we've discerned a palpable sense of fatigue within the industry regarding AI.
Developers frequently lament, "There's an overwhelming amount to learn, and selecting the right models is daunting."
In the past, when a single model clearly outperformed others in overall capability, developers could simply opt for it. If a model had limitations, subscribing to a few others sufficed. However, the current landscape lacks a dominant model, and token prices continue to climb. Developers now find themselves constantly switching models, understanding their unique characteristics, meticulously calculating costs, and repeatedly testing and comparing them in specific business scenarios. This has led to significant learning fatigue and decision-making hurdles.
A popular saying has emerged in Silicon Valley: the more one understands and utilizes AI, the more anxious they become. Far from reducing work hours, it significantly increases them.
What if developers bypass the selection process and directly opt for top-tier models? The outcome is often "you get what you pay for, but paying ten times more only yields a 30% increase in value."

The costs are so prohibitive that even Microsoft felt the pinch, recently announcing the discontinuation of Claude Code and its migration to the in-house GitHub Copilot CLI. Companies without backup models, like Uber, faced monthly Claude Code tool expenses ranging from $500 to $2,000 per engineer, leading Uber to exhaust its annual AI budget by April this year.
These challenges represent the "sweet burdens" exclusive to the global top 1% of technical elites.
For the majority of ordinary people, the AI experience is fragmented and fraught with helplessness.

Some argue that AI is not a tool for equality but a lever for polarizing groups.
Top-tier large models have become exclusive tools for the elite, amplifying their existing advantages, while the general public remains in a constant state of fear and anxiety about being left behind. To keep pace, non-technical professionals are compelled to learn AI, only to discover that tasks that could be completed in half an hour with Excel now take days with AI.
The current AI landscape has become bizarre: no one benefits effortlessly; everyone is passively anxious and internally drained. What has caused this? With 2026 halfway over, it's time to discuss the mid-game crisis of models.

In education, there's a concept known as "selecting the top students." A school prioritizes high-achieving students from the entire region, creating an appearance of high teaching standards when, in reality, it's due to the abundance of quality students. Once selection is no longer possible, graduation rates regress to the mean. The same logic applies to why AI is increasingly fatiguing for developers.
In the past, when a dominant model existed, developers could simply lock in the top model—using Deepseek R1 for Q&A in early 2025, Seedance 2.0 for video generation in 2026, and GPT for graphic text layout—to achieve optimal results with one click. This was the dividend of selecting the best. However, the era of "selecting the top" has temporarily stalled.

Some may wonder: with new models continuously emerging, some with impressive breakthroughs and widespread impact, why can't we still "select the top"? The change lies in the fact that while new models are still being released, the magnitude of breakthroughs and performance gains with each update has diminished. The leading shelf life of top models has also been drastically shortened. Previously, a top model's advantage could remain stable for months, allowing users and developers to rely on it without worry of being surpassed or needing extensive research. Now, the workload for screening, evaluating, and switching models has surged. Blindly "selecting the top" is no longer feasible, making the process more exhausting than before.
The ceiling on base model capabilities was anticipated by the industry, but 2026 truly marks the "wolf is at the door" moment.
On one hand, computing costs have skyrocketed. The Scaling Law has hit a wall; brute force no longer yields miracles. The direct impact of rising costs is that the return on investment for achieving performance leaps through scale has plummeted to an all-time low. Only leading model factories like Google and OpenAI, which still have resources to spare, can afford to stack resources to achieve breakthroughs that feel impressive.
Simultaneously, high-quality corpus data is nearing depletion. Many users sense that AI Q&A has fallen into a cycle of self-generation and mutual distillation. AI-specific phrases like "steadily catching you" or "let me give you the most direct and objective..." are contagious across models. Some joke that "GPT's language is becoming increasingly internationalized," which essentially reflects a global lack of new, high-quality corpus injection, preventing the widening of capability gaps.
In a model market where "selecting the top" is no longer viable, user selection costs have soared. Users must now tailor models to specific scenarios, expending significant time and effort to compare options and balance effectiveness, cost, and context.

After some developers stumbled, they adopted a blunt strategy: directly choose top-tier models to minimize hassle and errors. However, this approach doesn't work for most ordinary users.
Except for a small developer group, almost no one is willing to pay for high-priced model subscriptions. Data shows that out of a global population of 8.1 billion, only 0.3% pay for AI. In reality, once fees are introduced, people opt for more cost-effective alternatives or free models. But along with the dividend of "selecting the top," the era of freebies is also fading.
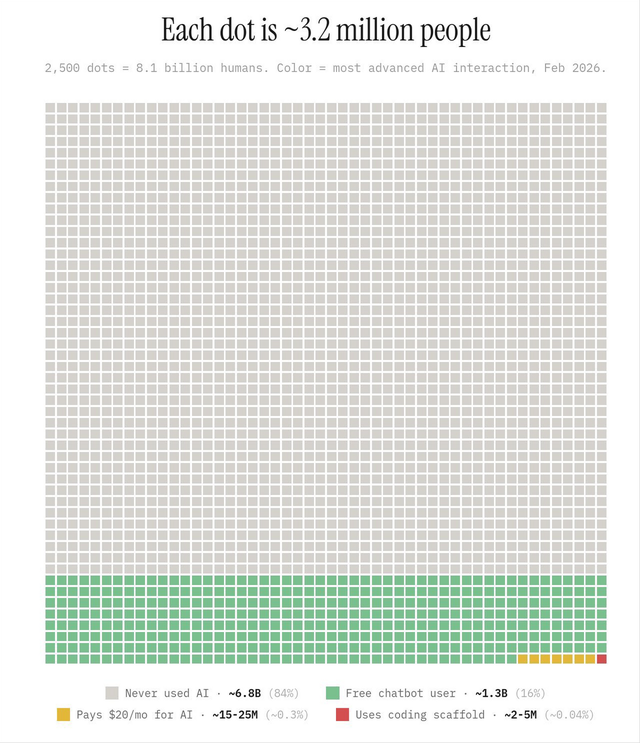
(The yellow blocks in the image represent 0.3% of the global population paying $20 monthly for AI.)
In 2026, many mainstream models' free or lowest-tier subscription versions have experienced varying degrees of degraded performance.
For instance, the creative writing capabilities of leading Chinese models have declined, with users joking that they've become "greasy." After some models adopted paywalls, users reported that the free versions became "dumber," with increased hallucinations. Overseas models have also been observed by practitioners to have sharply reduced median thinking lengths, sometimes outputting results without even reading the original files in code modification tasks.
In short, these free or low-cost models have started to "slack off."
This has led to a series of derivative issues. Many ordinary users fail to notice the degradation of inclusive models and still habitually entrust serious matters like legal affairs, problem-solving, and major decisions to free AI tools, resulting in increased accidents like flawed decisions and even financial losses.
Another issue is the widening gap between groups.
Those who understand top-tier models and can afford them leverage AI as a lever for efficiency, while the general public invests significant effort in affordable models with limited returns. Stable access to overseas top-tier models has even become a fashion statement and status symbol for some domestic high-end white-collar workers. Some have even proposed that AI creates a divide between "elite groups vs. ordinary people," which is highly misleading.

The ultimate form of AI should be an inclusive tool accessible to all, like smartphones or computers, where flagship and budget models alike can run all essential functions smoothly. Currently, large models have transformed from equalizing tools into amplifiers of disparities—a phase issue that must be resolved.
Before solving it, we must first understand why inclusive models suddenly became less effective.
One reason is that after the industry bid farewell to the era of low-priced tokens, model factories actively reduced models' deep thinking capabilities to cut inference costs, leading to AI degradation. In this case, paying more can restore intelligence.
Another reason, which money can't easily fix, is the slowing progress of inclusive domestic models. For global developers and users, Chinese open-source models have long been synonymous with inclusivity and cost-effective alternatives to expensive overseas closed-source models. However, entering 2026, the gap between domestic open-source models and overseas counterparts has widened, with an average estimated lag of 6-12 months.
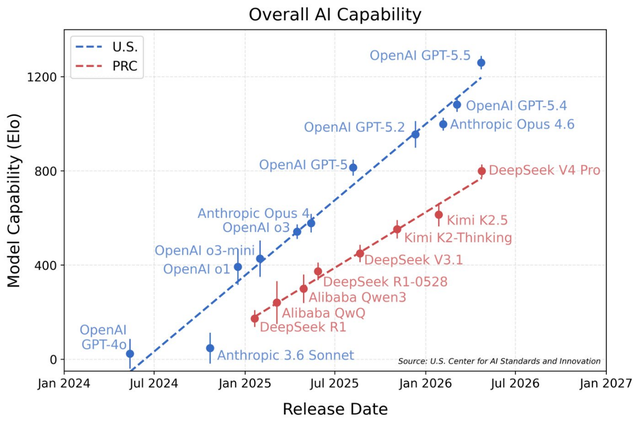
(A domestic model's capabilities match GPT 5 on a non-public benchmark, with an 8-month gap.)
The root cause remains computing power constraints. Previous optimizations through lightweight MOE architectures have limits and cannot fully replace large-scale, high-quality pre-training, which relies on high-specification computing clusters. The generational gap in high-end AI computing power remains a practical weakness for domestic models.
None of us want AI to fragment society or widen class divides. We should not exacerbate capability gaps between different groups. Therefore, addressing short-term cost pressures and mid-to-long-term computing bottlenecks remains crucial for the industry.

Enterprise demand for intelligence is the primary commercialization path and cash cow for the AI industry. In the current enterprise market, we hear mixed feedback—both optimism and concern:
The optimism stems from the real value of models. A representative from a financial digitization enterprise told us that free open-source models have enabled domestic banking to rapidly and cost-effectively deploy AI agents and digitization solutions. In contrast, U.S. banks, reliant on expensive closed-source models and hampered by outdated digital infrastructure, struggle to implement intelligent applications. This has given domestic financial technology a stronger competitive edge in overseas markets, with financial institutions in emerging markets like Southeast Asia now more willing to adopt Chinese fintech solutions.
The concern arises from the difficulty in monetizing models. Some model factories report that it's not a lack of client leads or enterprise demand but a complete absence of budgets. AI investments are almost entirely concentrated in tech companies and industry leaders, becoming the biggest bottleneck for AI-to-B business growth.

What is the key to unlocking enterprise AI budgets? Return on investment.
While fear of missing out (FOMO) drove adoption in previous years, regardless of AI's usefulness, 2026 demands tangible results and cost-effective models to persuade enterprises to invest.
The shifting winds in the enterprise market have raised the competitive bar for model factories. One could even say that the real pain begins after a new model's release. Model factories must deliver real business results, even experimental cases, to provide industry clients with verifiable outcomes.
As a result, a noticeable change is the declining hype around general-purpose large models.
Vendors are pivoting fully toward vertical scenarios, refining specialized capabilities. At some model factories' annual conferences, base models are no longer featured; instead, industry versions and user testimonials take center stage. As the value of ISV partners and industry client use cases becomes prominent, the ecosystem capabilities of model factories are growing increasingly important.
The ability to drive maximum business value at minimal cost is now a critical question for all models.

Developer fatigue, the divide between tech elites and the general public, and enterprises' dilemma between investment and returns—these emotions define the AI landscape in 2026. How long will they persist?
The answer depends on whether large models can overcome their current stagnation and return to a path of sustained breakthroughs. For now, we haven't seen a turning point in this trend.

Futurists often respond to public doubts about technological change with a saying: "Problems caused by technological development will ultimately be solved by continued technological progress."
Trading time for space, from this perspective, resolving the current model crisis doesn't solely rely on waiting for disruptive technological breakthroughs. During this plateau in model capabilities, reducing friction and fatigue in usage can buffer and dilute technical issues, buying more time and space to break the deadlock.

-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





