MiniMax Faces an Uphill Battle to Reclaim Its Initial Vision
 06/05 2026
06/05 2026
 431
431

On Children's Day, MiniMax, which had maintained a low profile for some time, made a grand entrance with the launch of its new-generation model, MiniMax M3. In the official's nearly impeccable 10,000-word technical announcement, M3 was hailed as an all-powerful 'six-sided warrior'.
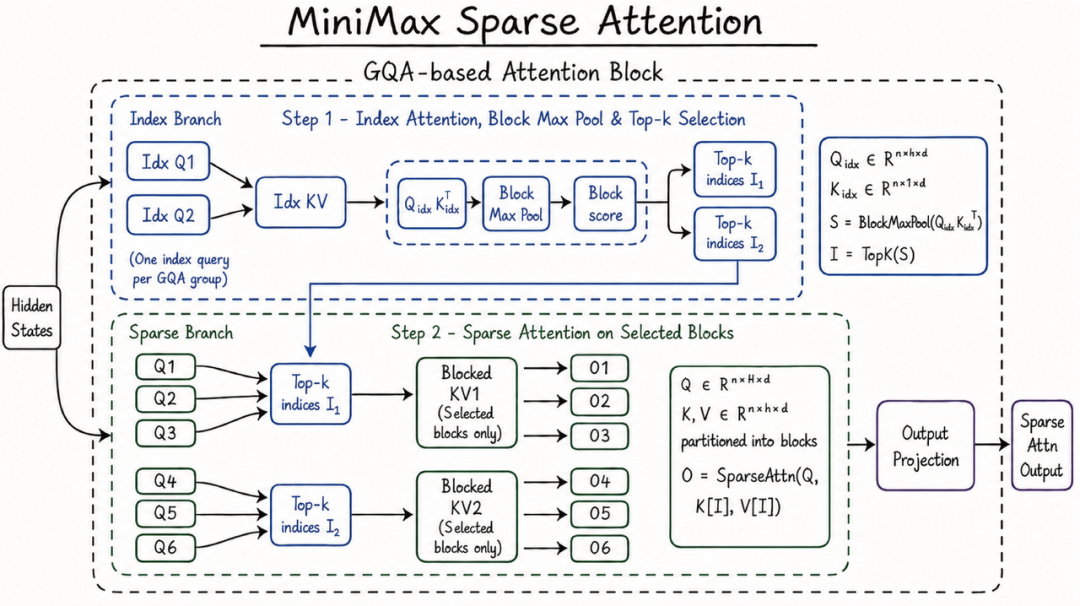
Leveraging MiniMax's latest technological breakthrough, the MSA (MiniMax Sparse Attention) sparse attention architecture, M3 effortlessly handles ultra-long contexts of 1 million tokens, natively processes multimodal data, and can even autonomously run for 12 hours to independently reproduce award-winning papers from ICLR 2025. More surprisingly, the official claimed that M3 outperformed two globally top-tier models, GPT-5.5 and Gemini 3.1 Pro, in authoritative evaluations.
'M3 is the first model in China to possess all these elements and is currently the only open-source model.' This bold assertion in the official press release seemed to prematurely claim victory.
However, before Children's Day was over, a wave of negative news began to surface. Within three days, the celebratory bubble had thoroughly burst before it even had a chance to rise. Whether in official tweets or promotional videos, discussions about technological breakthroughs were met with a deafening silence, replaced instead by a flood of refund requests.
Behind this dramatic turn of events lies MiniMax's arrogance and its calculated approach to commercial operations. Stripped of the glittery benchmark scores in its technical reports, M3 found itself in the ruthless competitive arena set by DeepSeek and Xiaomi's joint efforts last month, in terms of both actual capabilities and pricing.
01 Pricing with 'Mysterious Confidence'
The first crack in M3's glossy facade was its extremely incongruous pricing strategy.
Let's first examine the technical report. The official spent considerable effort boasting about extreme optimizations in computational costs: Based on a 1 million-token context window, M3's computational load per token is only 1/20th of the previous generation's model, with over 15 times acceleration advantages during the decoding phase.
Following normal business logic, if computational costs can be reduced exponentially, it should lead to more cost-effective pricing, allowing MiniMax to preemptively secure a foothold in China's second major large model price war. However, MiniMax did the opposite. Not only did the actual usage costs become higher than the previous generation's model, but it also implemented a 'double standard' approach that left domestic developers thoroughly disheartened.
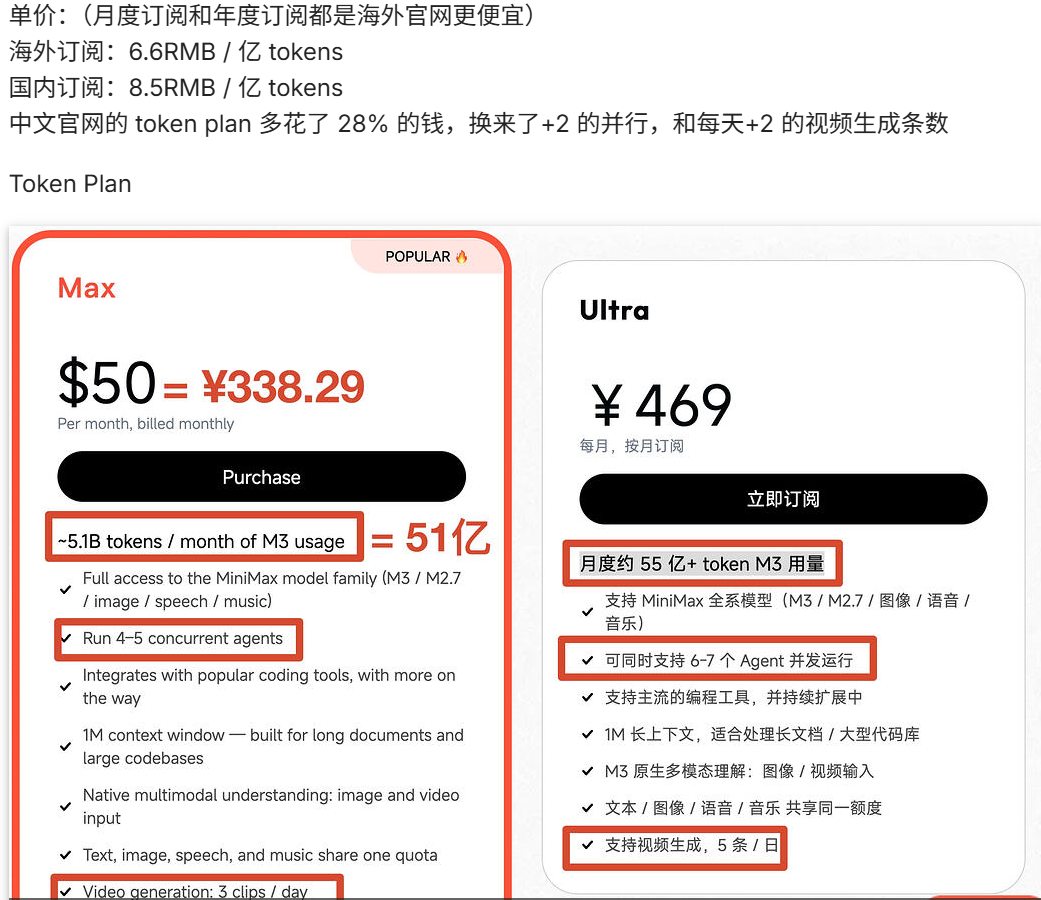
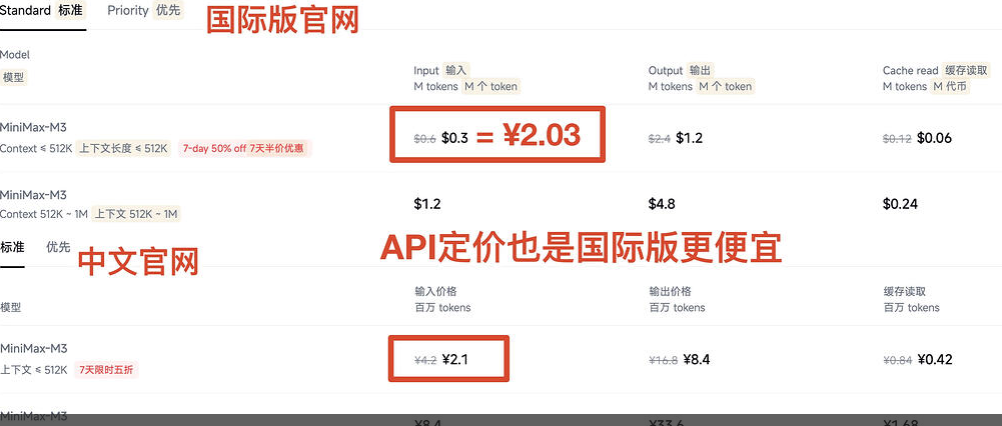
Image Source: https://linux.do/t/topic/2286885
On the evening of its release, discrepancies in pricing between MiniMax's Chinese and English official websites were exposed. In terms of per-unit price, domestic subscriptions cost 8.5 yuan per 100 million tokens, while overseas subscriptions cost 6.6 yuan per 100 million tokens. Regarding Token Plans, domestic users had to pay 28% more but only received two additional Agent concurrent executions and two extra video generation credits.
In other words, domestic users had to pay 28% more for the same domestic AI service on their home turf. This is highly unusual, as mainstream domestic large model manufacturers, including its competitor Zhipu, typically charge significantly more for overseas subscriptions in their pricing strategies.
In an environment where DeepSeek and Xiaomi have driven API prices down to bargain levels, and international users have numerous preferred options from OpenAI, Anthropic, and Google, MiniMax's double standard instantly eroded goodwill among domestic developers.
However, this was just the beginning of the storm.
02 Silently Slipping Away Rights and Benefits
This set of operations should seem familiar to domestic developers, as it closely mirrors Zhipu's actions two months earlier. For these large model startups, developer users willing to spend real money on annual subscriptions to high-tier packages costing hundreds or thousands of yuan are one of their core assets. These developers, possibly distributed across various enterprises, serve as loyal users expanding the model's application scope for Minimax. However, this group, which should have been the most cherished, became the most severely exploited in the M3 release.
The belated apology and compensation announcement failed to cover up the issue with sweet talk. Developers in the technical community used rigorous testing scripts and data reports to uncover the truth behind the official's so-called 'lossless migration and generous compensation': It was an extremely precise word game and accounting manipulation.
The first layer of manipulation involved a deceptive billing dimension.
It must be acknowledged that the Token Plan, in its literal sense, is a reasonable billing method. The original old packages charged 'per API call,' which many users handling long text processing tasks (such as complex programming projects, immersive translations, etc.) found to be cost-effective.

Taking advantage of the M3 release, the official also forcibly changed the billing model to 'per-token charging,' similar to mobile data plans. This should have made billing more transparent and allowed users to monitor usage more conveniently. However, in user testing, although the packages included billions of tokens, M3 consumed them much faster than the previous generation's M2.7 model. High-tier packages that once lasted a month might now only last a few days. From a technical perspective, M3 likely has issues with cache hit rates and tool invocation efficiency.
The second layer of manipulation involved a usurped multimodal pool.
This is the easiest aspect to overlook and the most fatal blow. In the old packages, text model and multimodal model quotas were calculated independently. However, the new Token Plan lumps image generation, TTS voice generation, and video generation into an opaque shared consumption pool.

Obviously, multimodal functions consume far more resources than text models. Having the system generate a few images or a video segment could consume tokens equivalent to an hour of programming tasks.
The most difficult aspect to explain is the discrepancy between nominal and actual token quotas.
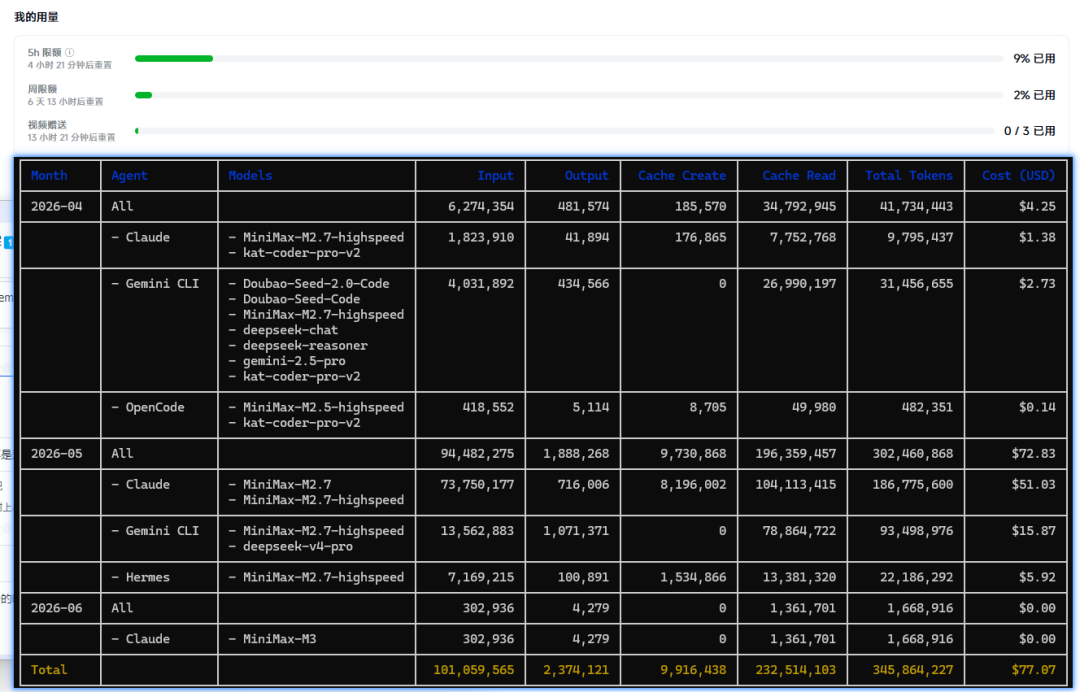
Image Source: https://linux.do/t/topic/2283892
One user demonstrated M3's token consumption over a 5-hour period. Based on the proportion, the upper limit appears to be around 10 million tokens every 5 hours. If accurate, the weekly limit would not exceed 80 million tokens, and the monthly limit would not exceed 400 million tokens. For MiniMax's loyal long-time users, this means 'paying the most and getting hit the hardest,' with a cliff-like shrinkage in actual available benefits.
When an AI productivity tool starts calculating every penny with its users, the collapse of trust is imminent.
03 'Disastrous' Public Relations
As various actual evaluations and accounting posts fermented across major communities, calls for refunds grew louder. Cornered, the MiniMax official finally released a half-baked apology announcement in the middle of the night.

This announcement deserves to be a case study in how not to do PR. Its opening line boldly declared, 'Let's still be happy at the tail end of Children's Day~'
Facing a group of developers who had just been forcibly migrated to new plans, had their billing quotas secretly altered, and had their original rights stripped away without clear reason, the official chose this flippant and sarcastic opening.
Setting aside the arrogance revealed in the language, the announcement's content was equally difficult to accept logically. It perfectly avoided all core contradictions: It said nothing about the double standards in domestic and international pricing or addressed the total quota shrinkage caused by token-based billing. Instead, it proposed a compensation plan:

Even in this hastily proposed compensation plan, there was differentiated treatment for long-time subscribers. In the comment section, developers didn't hold back with their sarcasm: 'The official drained more than half of my tank, then apologized by saying, 'As compensation, I allow you to floor the accelerator today.' What good does that do?'
To date, under the Xiaohongshu post with the most comments, the only official reply is a user's praise: 'M3 is much stronger than M2.7!' Other users' questions seem to have sunk into the ocean.
The anger among veteran users sparked by these operations needs no elaboration. A user named @mozilong on the Linux.do forum argued forcefully in MiniMax's official Feishu group. Faced with questions, the official's ultimate solution was to simply kick the user out of the group.
If you can't solve the problem, solve the person raising it. This logic doesn't work in the developer community, which values contractual spirit. These operations are tantamount to digging one's own grave.
So, what force compelled the official to hurriedly modify rules, issue apologies, roll out compensation, and even immediately design refund channels overnight?
Probably not a sudden attack of conscience, but a beating from capital.
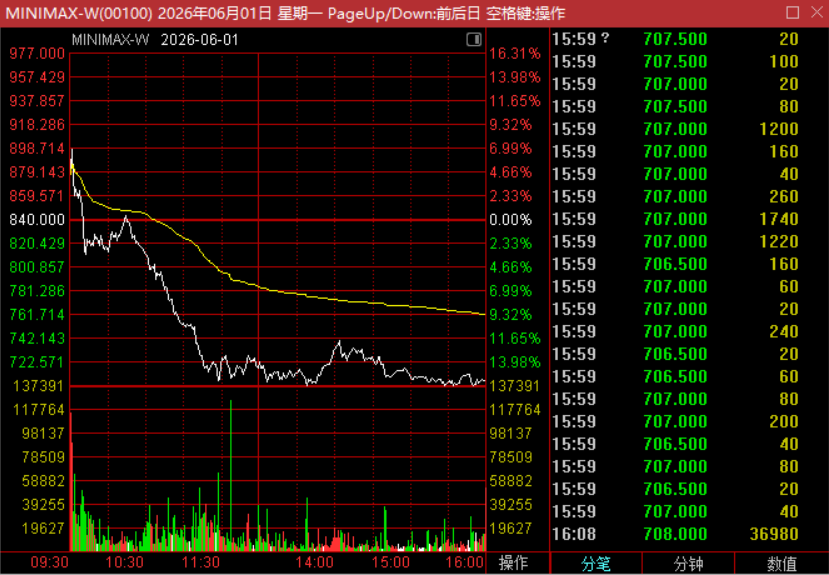
On June 1st, in the Hong Kong stock market, after a brief opening, MiniMax's stock transformed into a kite with a broken string, experiencing a waterfall-like collapse. The stock price slid from the 898 range down to a low of 707, with intraday losses approaching 20%, leaving a tragic long negative candlestick on the K-line chart.
This abnormal phenomenon of the stock price falling instead of rising after the new model's release is the market's most authentic vote.
04 The Imminent 'Kill Zone'
If the counterproductive operations in commercial strategy merely accelerated the collapse of reputation, the third-party evaluations released three days after the launch directly negated MiniMax M3's technological narrative.
On June 4th, AI evaluation agency Artificial Analysis released its latest ranking data. This report, which MiniMax had likely pinned high hopes on to prove its model's superiority over domestic competitors, instead delivered a resounding slap in the face.
MiniMax M3's evaluation data appeared highly anomalous: While it couldn't compete with international top-tier models in intelligence and agency capabilities, it did rank first among domestic models. However, its performance in programming capabilities was nothing short of disastrous.
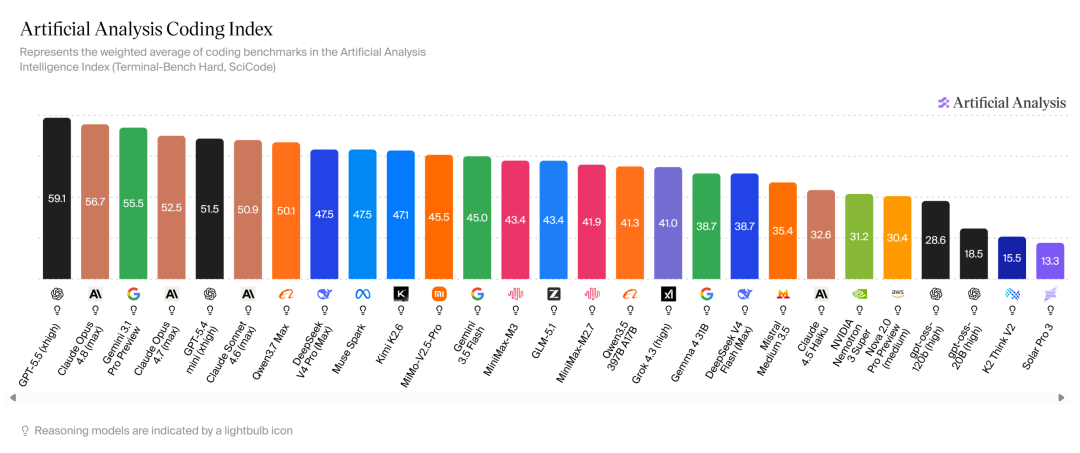
Not to mention models from OpenAI, Anthropic, and Google (the 'Big Three'), MiniMax scored even lower than earlier models like Qwen3.7 Max, DeepSeek V4 Pro, Kimi K2.6, and MiMo-V2.5-Pro. It barely tied with competitor Zhipu's GLM-5.1 and showed only marginal improvement over its predecessor, M2.7.
We know that evaluating a model's intelligence cannot be separated from programming tests. Programming prowess determines whether it's suitable to serve as the brain for intelligent agents.
Therefore, keen users quickly spotted a paradox in these rankings that defied AI scientific common sense: MiniMax M3's coding capabilities lagged, yet it was supposedly highly intelligent with outstanding agency capabilities.
This is akin to a student who can't recognize mathematical symbols winning an international math competition. In other words, this ranking, like claiming 'main =6' (a nonsensical equation), smacks of manipulation: targeted benchmark gaming.
In the AI industry, this is already a semi-open secret. If a model undergoes intense 'exam-oriented training' for specific agent evaluations during its training phase, it will naturally provide perfect answers when facing those particular test questions.
But what intelligent agents require are robust capabilities in code generation, logical reasoning, and complex environment planning. Once they step out of fixed benchmark test sets and enter real production environments, agents lacking fundamental programming capabilities are doomed to fail in delivering any commercial value.
In this context, the official announcement touts 'top-tier programming prowess' yet only lists achievements like surpassing GPT-5.5 on the SWE-Bench-Pro score and completing 1,959 tool invocations in 24 hours without human intervention. When compared to the basic coding abilities showcased in evaluations, these claims resemble a meticulously choreographed model play.
Faced with such a report card, users have every reason to question: at a time when DeepSeek has set a stringent benchmark with its solid foundational reasoning capabilities and unparalleled cost-effectiveness, why should users pay for MiniMax's M3?
05 Conclusion
From being the center of attention on June 1st to a scene of disarray by June 4th. The transformation that unfolded in just 72 hours serves as a wake-up call for the domestic large model industry: the era when a technical report and a few benchmark scores could win user recognition is gone forever.
In the latter half of the competition, the overarching theme of intense internal rivalry has already taken center stage. Technologists, with DeepSeek as a prime exemplar, persist in their quest for the ultimate cost-performance ratio (the pinnacle of cost-effectiveness) by means of foundational innovation. Meanwhile, Xiaomi, keeping pace closely, has, in tandem with DeepSeek, jointly erected a benchmark that intertwines price and performance.
Beneath this benchmark, any endeavors to manipulate users through accounting sleights of hand, to cultivate a core user base through subtle price increments, or to obscure product defects through suppression are laid bare for all to see.
DeepSeek has demonstrated that individuals are willing to overlook temporary technical deficiencies in a domestic AI enterprise and evolve alongside it through the process of debugging and refinement.
However, for MiniMax, the task of forging trust necessitates years of unwavering iteration and consistent effort. Yet, the erosion of that hard-earned trust can transpire in a mere 72 hours or less.
The window of opportunity for MiniMax to rediscover its initial ambitions and aspirations is rapidly closing.
Reprinted with the requisite permission.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





