What Changes Will Happen in the Industry When Intelligent Driving Enters the Era of Physical AI?
 06/05 2026
06/05 2026
 498
498
If you've watched a few automotive launch events recently, you might have noticed a recurring term: large physical AI models. XPENG talks about it, Li Auto talks about it, Momenta talks about it, and even NVIDIA, a chipmaker, talks about it. The frequency with which this term appears makes it feel like more than just another marketing gimmick—it seems to be an industry trend. So, what exactly does physical AI refer to? How does it fundamentally differ from the previously discussed end-to-end, BEV+Transformer approaches? When intelligent driving systems start to be driven by physical AI, what real changes will occur in the driving experience?
Why Has Autonomous Driving Reached a Point Where Change Is Inevitable?
Before physical AI became a buzzword, the mainstream technical approach in the intelligent driving industry was end-to-end. End-to-end uses a single neural network to mimic the driving behavior of human drivers. By exposing this network to vast amounts of driving data, it can learn driving actions. In an end-to-end large model, the input is camera footage, and the output is steering wheel angle and throttle/brake signals. It does not require engineers to manually write rules or to treat perception, decision-making, and control as separate modules. The network itself learns the basic operations of driving from the data.
Now, the end-to-end approach has indeed proven viable and is advancing rapidly. Urban navigation-assisted driving is being implemented in more and more vehicle models, and performance in highway scenarios is becoming increasingly stable. However, as end-to-end models are applied, the industry quickly discovered another issue: their performance significantly declines when faced with unfamiliar scenarios. Zhou Guang, CEO of Yuanrong Qixing, used a metaphor to describe this problem: developing intelligent driving is like sitting on a seesaw. You tune a particularly complex intersection in Shanghai, only to find issues at an intersection in Shenzhen. You smooth out urban congestion and cut-ins today, only to encounter problems with sharp mountain turns tomorrow. It's like pressing down one gourd (a Chinese term meaning 'problem') only to have another float up—always patching loophole (loopholes). He calls this phenomenon the seesaw effect.

Image Source: Internet
So, what is the root cause of this problem? In essence, end-to-end models memorize driving behaviors rather than understanding why they should be performed. What they learn from training data is a statistical correlation—that a certain visual input most likely corresponds to a certain operational output. The model does not know that the obstacle in the scene is a rolling box or understand how the trajectory and speed of the box are influenced by physical laws. It has simply seen similar scenes before and mimics the corresponding operations. When encountering scenarios rarely seen in the training set, such as a tricycle pulling an oversized load slowly turning at a township (township) market intersection, accompanied by a few pedestrians carrying vegetable baskets and walking erratically, the model's generalization ability is very limited.
Li Xiang, CEO of Li Auto, once straightforward (bluntly stated) that traditional end-to-end models are essentially imitation learning. They can only receive visual signals combined with vehicle speed to output motion trajectories and do not possess a causal understanding of the real physical world. Even if they can handle most generalized scenarios, they will encounter problems when faced with unseen complex situations. This is precisely the core issue that physical AI can address.
What Is Physical AI?
We can start with a simple comparison. Models like ChatGPT and DeepSeek, which are familiar to everyone, process information from the digital world, such as text, images, and videos. You ask them a question, and they give you an answer. They do not need to know the value of gravitational acceleration, understand how many times a ball will bounce when dropped on the ground, or care about how many pieces a cup will shatter into when it slides off a table. These things have no impact on their work because they are always dealing with symbols and information.
The things processed by physical AI are entirely different. Its inputs come from sensors in the real world, such as cameras, LiDAR, and millimeter-wave radars. Its outputs are control signals that alter the state of the real world, such as steering wheel angle, brake pressure, and throttle opening. It must understand physical laws like friction, inertia, momentum, and motion trajectories because these laws determine whether each decision it makes is valid.
Take a simple example: physical AI needs to know that the same braking force on a slippery road will result in a longer stopping distance or that a rapidly spinning wheel that suddenly locks up may cause the vehicle to skid sideways rather than stop in a straight line. For it, these are not abstract pieces of knowledge but computational conditions that must be relied upon when making decisions.

Image Source: Internet
In simple terms, physical AI is a class of intelligent systems capable of perceiving the real physical environment, understanding the physical laws within it, and taking action in that environment. Its core characteristic is not its size but its connectivity with the world—its cognition and actions must conform to the constraints of the physical world.
For autonomous driving, physical AI does not simply allow the system to memorize what to do when it sees something from the data. Instead, it enables the system to internally construct a dynamic understanding of the current environment, including the position, speed, and motion trends of each object. Then, based on its understanding of physical laws, it predicts what will happen in the next few seconds and finally selects a safe and efficient operational plan. In this process, it utilizes both semantic understanding capabilities (e.g., interpreting traffic lights and traffic police gestures) and physical reasoning capabilities (e.g., predicting where a rolling ball will go).
With this conceptual foundation, we can understand why today's intelligent driving systems need to upgrade from end-to-end to physical AI.
Two Paths, One Goal
Over the past year, the industry has diverged into two main technical directions: VLA and World Model. Their goal is the same—to enable intelligent driving systems to possess a holistic understanding of the physical world—but their implementation paths differ. Yesterday, we discussed the choices made by various automakers regarding these two approaches (Related Reading: Which Is More Suitable for Autonomous Driving: VLA or World Model? Why Do Automakers Have Different Choices?).
VLA stands for Vision-Language-Action. Its basic idea is to introduce the capabilities of large language models into autonomous driving. After a visual encoder extracts image features, a language model first describes the scene (e.g., "There are pedestrians crossing the intersection ahead quickly") and then an action module decides how to operate based on this description. The advantage of this design is that the system can understand complex semantic information. Actions like a traffic police officer gesturing for passage, which are difficult for traditional systems to understand, can be interpreted by VLA through the language model's semantic understanding capabilities, knowing that the gesture means 'let me go first.' Similarly, it recognizes the rules represented by names like left-turn waiting areas and bus lanes.
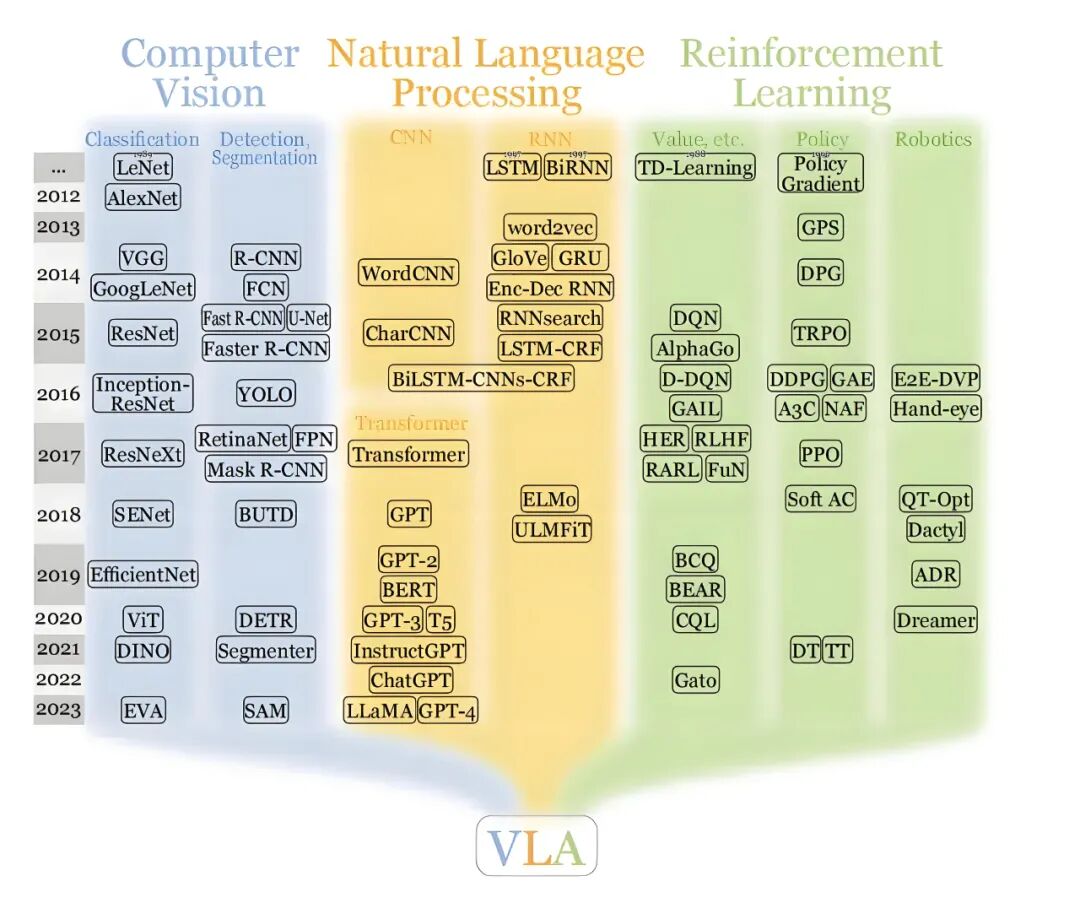
Image Source: Internet
However, VLA also faces several challenging issues. The language descriptions themselves can be ambiguous. Subtle differences, such as between "a pedestrian is moving quickly" and "a pedestrian is jogging," can lead to entirely different decision outcomes. Language model reasoning typically takes 200 to 500 milliseconds, while autonomous driving requires a response time of under 100 milliseconds in emergency situations. Additionally, the training data for language models cannot exhaustively cover all possible states of the physical world, and they still face generalization challenges when dealing with extremely rare scenarios.
The World Model takes a different approach. Its core method is not through language but by directly constructing a dynamic representation system of the environment in three-dimensional space. The World Model continuously receives sensor data, updates its internal understanding of each object's position, speed, and motion trajectory, and predicts how the environment will evolve in the next few seconds. You can think of it as a physical simulator running inside the system, where AI can pre-evaluate various operational plans in the simulator and only execute the optimal result.

Image Source: Internet
The World Model has a natural advantage in grasping spatial relationships and motion laws because it essentially learns the evolutionary laws of the physical world. However, it is not as good as VLA in understanding the traffic rules established by human society. It can calculate how objects will move but may not necessarily understand the meaning of a traffic police officer's gestures or the rules indicated by road signs.
Today, a consensus is gradually forming in the industry that these two paths are not mutually exclusive choices but can be integrated. The core characteristic of physical AI is precisely the incorporation of both semantic rule understanding and physical law reasoning into the decision-making process.

How Is Integration Achieved in Physical AI?
How is integration achieved in physical AI? Currently, there are several relatively mature approaches in the industry, each with its own focus.
One approach involves reconstructing the traditional VLA. Take XPENG's second-generation VLA as an example. It removes the intermediate step of language translation. Visual signals are no longer first converted into textual descriptions and then translated into control instructions by an action module. Instead, they are directly mapped from visual features to vehicle control signals. After the system perceives the position, speed, and motion trends of obstacles, it directly outputs steering wheel angle and acceleration/deceleration commands.
By skipping the reasoning process of the language model, the overall latency of the system is significantly reduced. XPENG's published data shows that its decision-making latency can be controlled within 80 milliseconds. Since the system retains the semantic understanding capabilities brought by the language model, it can still understand the meanings of traffic light colors, traffic police gestures, and textual information on road signs.

Image Source: Internet
Another approach takes the World Model as the main body and introduces reinforcement learning as the training mechanism. The World Model provides the system with a virtual training environment that conforms to physical laws, while reinforcement learning is the core method that drives the system to continuously learn through trial and error in this environment. The system repeatedly rehearses in the virtual environment, trying different driving strategies and receiving rewards or penalties based on the quality of the driving results. If an operation is both safe and smooth, the system receives positive reinforcement; if it leads to danger or discomfort for passengers, the system is penalized. After a vast amount of virtual rehearsals, the system eventually figures out the optimal driving methods on its own.
This approach fundamentally differs from the imitation learning of traditional end-to-end models. Imitation learning exposes the model to large amounts of human driving data and attempts to replicate human behavior. However, reinforcement learning allows AI to break free from the framework of imitation and explore on its own in virtual rehearsals: If I were the driver in this scenario, how should I drive best?
Momenta's R7 reinforcement learning World Model and Pony.ai's PonyWorld 2.0 both adopt this approach. PonyWorld 2.0 even possesses self-diagnosis capabilities. The system can automatically analyze the failure reasons for each driving decision—whether the issue lies in the perception stage or the planning direction—and generate targeted training scenarios based on the diagnosis to address weaknesses.

Image Source: Internet
Li Auto's MindVLA-o1 model, unveiled at NVIDIA GTC 2026, deeply integrates the above two approaches. Its core is a native multimodal MoE Transformer that simultaneously performs several tasks: it enables the model to perceive both semantic information and three-dimensional geometric structures through 3D spatial understanding; it introduces a predictive latent World Model to simulate the evolutionary trends of future scenarios in a latent space; and it adopts a closed-loop reinforcement learning strategy to continuously explore and optimize driving strategies using a virtual simulator.
What Substantive Changes Will Physical AI Bring?
If the above technical paths can ultimately prove viable in large-scale applications, autonomous driving will undergo several fundamental changes, all of which will be directly reflected in the daily user experience.
The first change is that the system's ability to adapt to unfamiliar scenarios will be significantly enhanced. Traditional models struggle particularly hard when dealing with long-tail problems, whereas physical AI will perform differently in long-tail scenarios. World models can automatically generate these never-before-seen scenarios in a virtual environment, and the generation process follows real physical laws. For example, the speed and rebound trajectory of a rolling ball, as well as the direction and distance a cardboard box is blown by the wind, are all results that conform to physical calculations. The system learns to handle these situations in advance in a virtual environment, so when it encounters real-world scenarios, it will no longer be in a state of having never seen them or being unable to handle them.

Image source: Internet
Another change is that driving decisions shift from statistical correlation to causal reasoning. When traditional autonomous driving faces risky scenarios, it essentially makes probability-based judgments. For instance, if a scenario is highly similar to one in the training data where the driver braked, then it will brake here as well. However, physical AI can attempt to understand the causal relationships between events. For example, if the vehicle ahead suddenly slows down, the system will determine whether it is due to an obstacle in front of that vehicle or the hesitant driving style of the driver ahead. In these two cases, the response strategies of the host vehicle should differ. In the former case, the host vehicle needs to decelerate in a timely manner, while in the latter case, it can maintain cruising. In the era of physical AI, the system does not simply imitate statistical patterns but attempts to clarify the causal chains between events to make more accurate responses.
Furthermore, physical AI can upgrade from imitating a few excellent drivers to exploring optimal driving strategies on its own. The best level that traditional end-to-end models can learn will not exceed the average performance of drivers in the training data. In other words, if the drivers in the training data do not handle certain scenarios well, the model will also learn suboptimal handling methods. However, with physical AI combined with reinforcement learning, the system can continuously trial and error and self-optimize in a virtual environment, gradually exploring driving strategies that are better than those in the training data. Safety and comfort constraints are designed as part of the reward function, and the AI will naturally find the optimal balance between the two during its deductions.
Summary
The emergence of physical AI has transformed the development of the autonomous driving industry. It no longer pursues competitions based on specific metrics such as how fast the system can drive or how complex road conditions it can handle. Instead, it focuses on whether the system possesses an overall cognitive ability of the real physical world. This is why more and more companies are beginning to regard physical AI as a strategic direction. From the perspective of the technological evolution path of the entire industry, this change has just begun, and the subsequent pace of evolution may be faster than many people anticipate.
-- END --
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





