Chip Enthusiasm Fades, Large Models Step into the Spotlight - The 'Dual Powerhouses' Make Their Mark on the A-Share Market, and the Journey is Far from Over
 06/05 2026
06/05 2026
 519
519

The talk of the town in the market these days is Jensen Huang's 'Midas touch'.
On June 1st, at GTC Taipei 2026, Huang Renxun made a clear statement: From an industry standpoint, tokens are assets and have evolved into a profitable revenue stream.
This brings to mind MiniMax, which recently launched M3. Its Token Plan Plus offers a staggering 600 million tokens for just 49 RMB and 1.8 billion tokens for 119 RMB—an aggressively competitive pricing strategy. According to official statements, this provides roughly 15 times the usable capacity of comparable overseas services at the same price.
If the dominant narrative in A-share AI over the past two years revolved around computing power and chips, that narrative is now being rewritten.
With Chips Becoming More Expensive, Who Will Utilize the Computing Power?
Where Does the True 'Divergence' Lie in A-Share AI?
Computing power chips and servers have garnered significant capital due to their clear path to revenue generation, high order visibility, and straightforward import substitution logic. As of the latest data, the total market capitalization of the electronics sector in A-shares has surpassed 20 trillion RMB, accounting for over 17% of A-shares and ranking first among all industries.
However, rotations in the tech market are always abrupt. Research from CITIC Securities notes that after the AI hardware hype cools down, capital will inevitably seek the next 'value洼地' (value trough).
So, the question arises: Who will utilize the computing power amassed on top of chips?
The answer is clear: Large models and the application layer. Chips serve as infrastructure—without demand from large models, computing power remains idle silicon.
M3's 'Triple Threat': 1M Context, Native Multimodality, and Cutting-Edge Coding
Meanwhile, China's 'application puzzle' is rapidly coming together, with M3 being the most impressive piece to date.
On June 1st, MiniMax officially unveiled its new-generation general large model M3, boasting three core capabilities: 'cutting-edge coding + 1M ultra-long context + native multimodality.' It became the first domestic general large model to simultaneously integrate these three top-tier features and the only one globally to achieve this level as open-source.

1. Architecture: M3 employs a self-developed Sparse Attention Architecture (MSA). The traditional Transformer's full attention mechanism is a double-edged sword—computational costs grow quadratically with sequence length. Expanding context from 100,000 to 1 million tokens increases computations by 10,000 times. MSA reduces per-token computations to about 1/20th of the previous generation, with inference performance over 4 times better than mainstream open-source solutions.
This is why 1M context isn't just about 'fitting more words.' What matters is that when a model tackles complex tasks, it needs to simultaneously comprehend project structure, dependencies, historical implementations, test cases, error logs, and even product documentation. Only with sufficiently long context can it act like a true engineering collaborator, making judgments within complete context.
2. Native multimodality: M3's design philosophy isn't just 'can it see images' but to train the model from scratch to treat text, images, videos, and desktop operations as unified tasks. The entire training data pipeline was rebuilt, with multimodal pre-training data reaching hundreds of terabytes. Text and visual semantic spaces are highly aligned at the bottom layer, enabling the model to directly understand prototypes, design drafts, screen recordings, and desktop operations—seamlessly connecting 'seeing' with 'acting.'
3. Coding capabilities: This is where M3 truly shines. On the BrowseComp benchmark for core AI agent capabilities, M3 scored 83.5, surpassing Claude Opus 4.7's 79.3 and ranking in the global top tier. It also performed exceptionally well on SWE-Bench Pro, demonstrating genuine potential to challenge overseas coding models' 'code throne.'
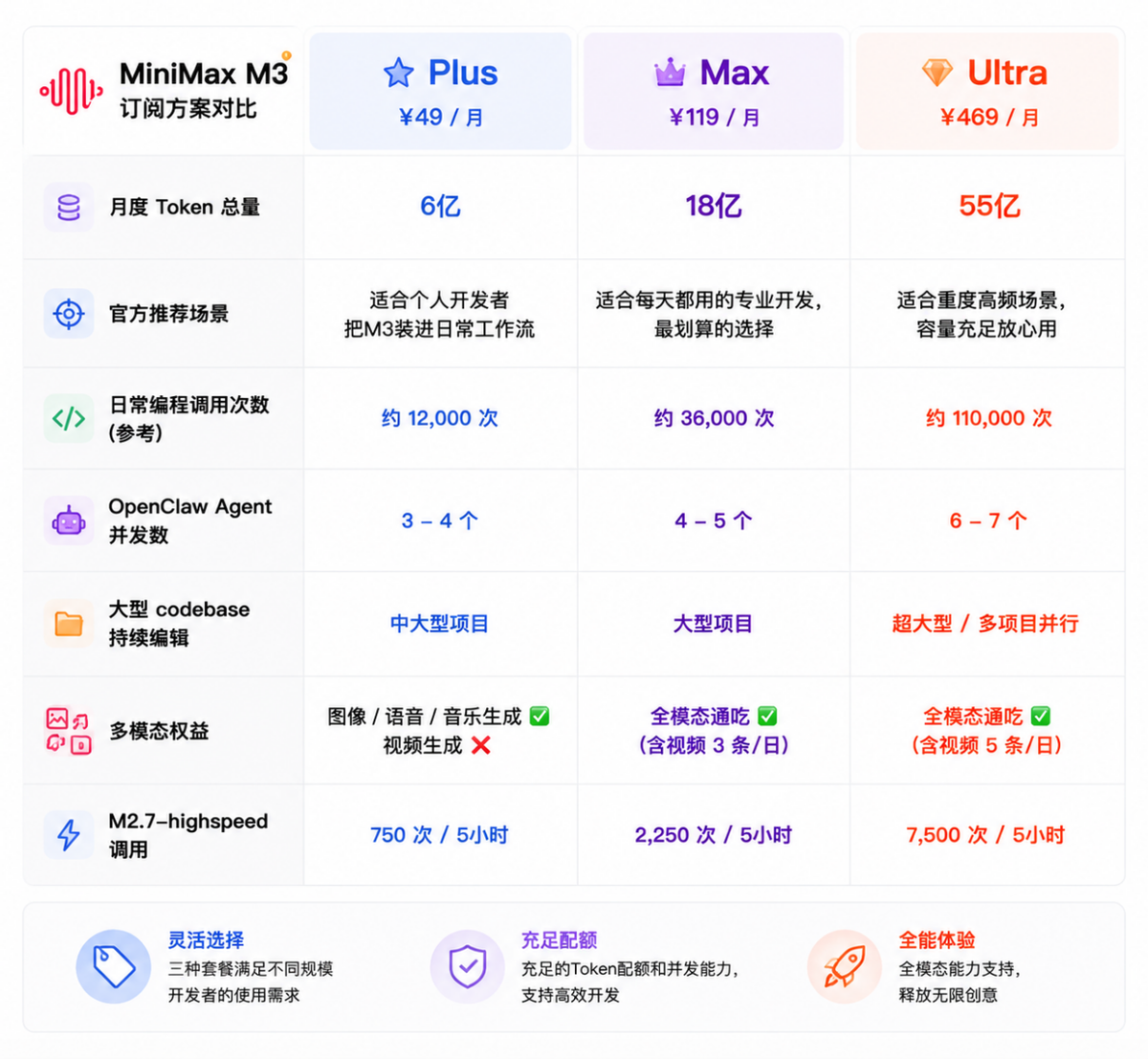
The Plus version offers 600 million tokens/month for 49 RMB, consuming 10-15 times more computing power than Claude Pro at the same price point. API pricing is 4.2 RMB per million token inputs, cheaper than Zhipu's GLM-5.1—all thanks to MSA's cost advantages, making low pricing sustainable. With 'open-source + low pricing + long context + coding,' MiniMax is positioning itself as the 'NVIDIA' of the agent era.
My Perspective: Don't Just Focus on Benchmarks—Prioritize Developer Stickiness.
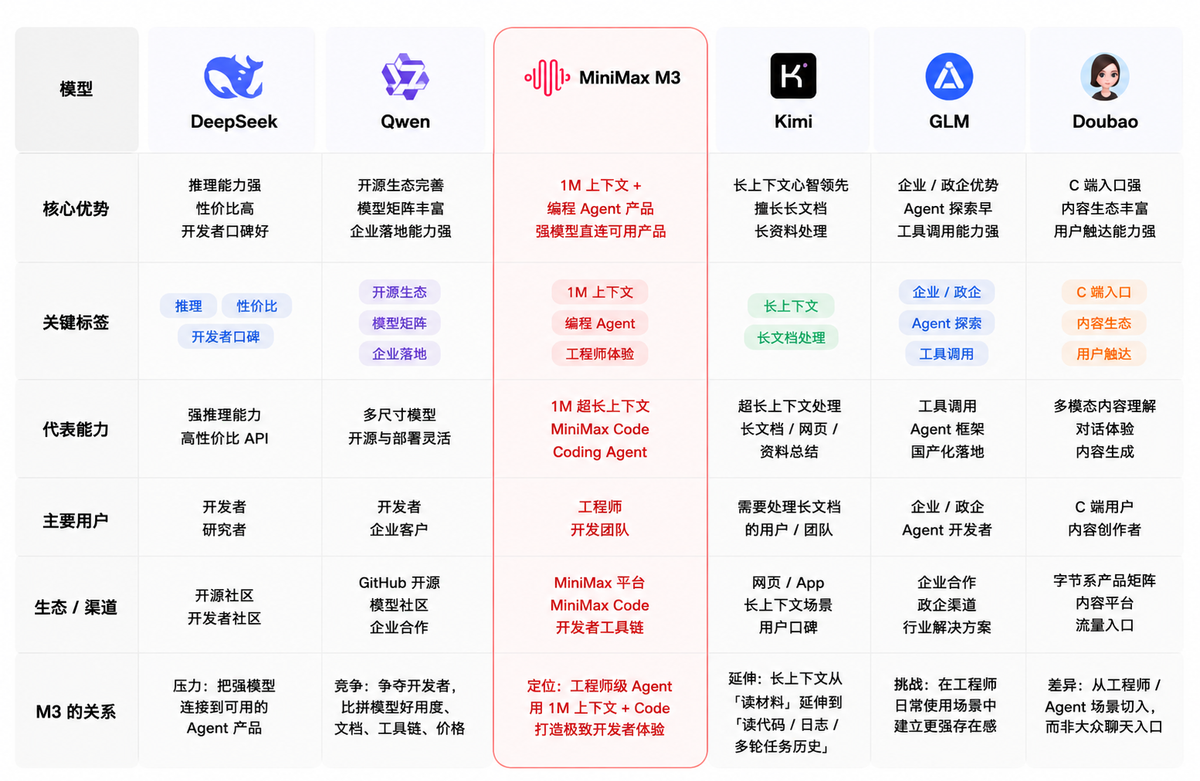
Competition among domestic models is no longer about 'who chats better.'
M3 offers a new perspective: Excelling in a single area is no longer remarkable—redefining the track (track = track/field) is what truly matters. It aims to be the domestic open-source foundation for the agent era, not just another chatbot.
On May 22nd, Zhipu launched GLM-5.1 for enterprise clients, and the market responded swiftly. By May 28th, Zhipu's stock price hit a record high of 1,618 HKD; on May 29th, it briefly touched 1,993 HKD, with a market cap exceeding 880 billion HKD.
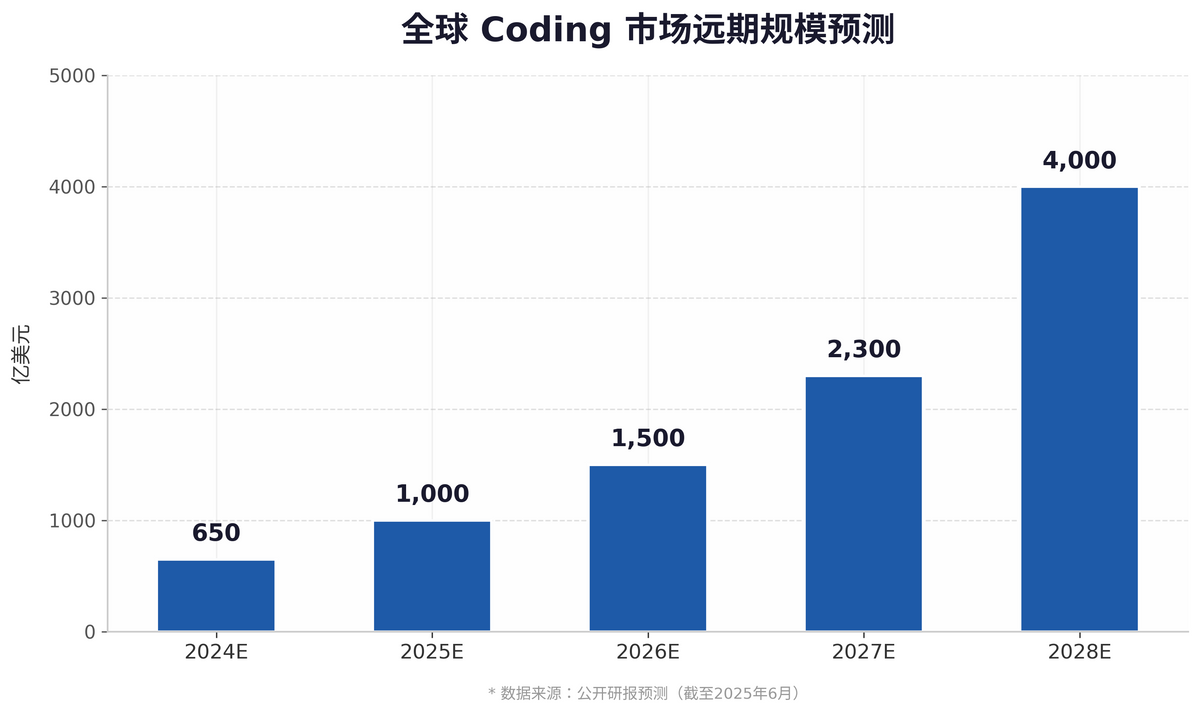
Zhipu's stock surge isn't an isolated incident. When Anthropic's ARR soared from $30 billion to $44 billion in two months and the global coding market's long-term TAM was estimated at $400 billion, coding is no longer just a technical competition—it's a commercial war over 'auditable productivity.'
M3 matches or surpasses leading overseas models in these key metrics.
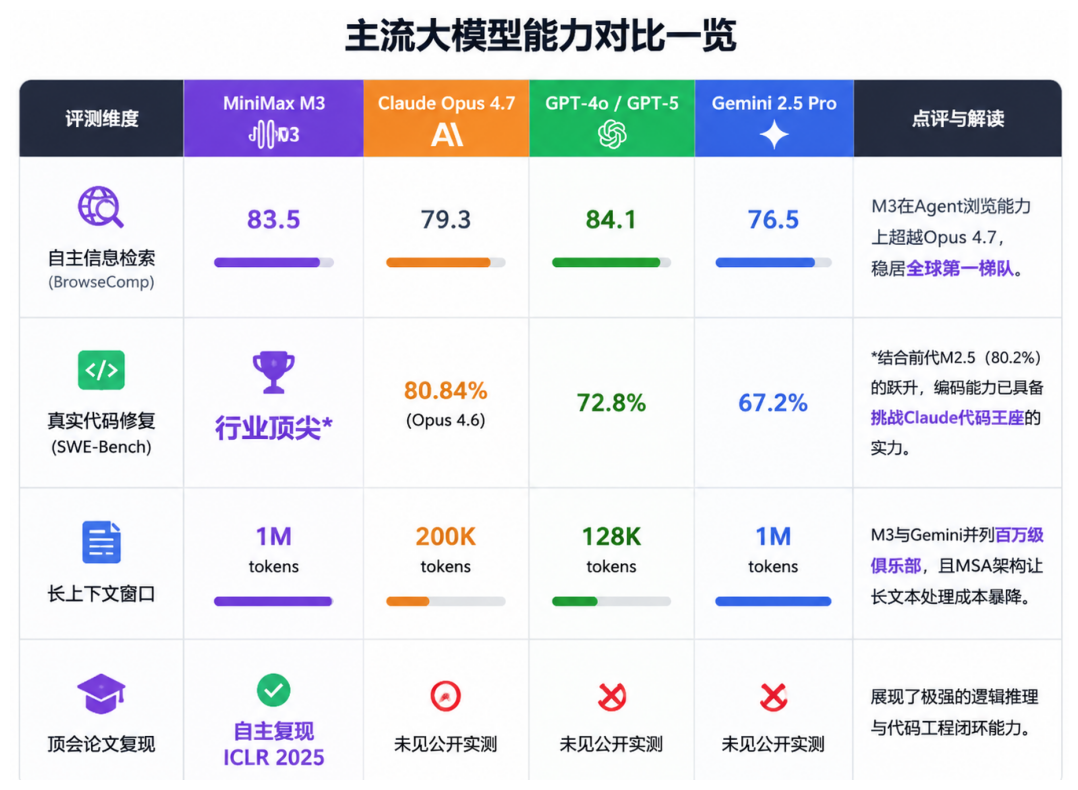
M3 strikes precisely at this strategic inflection point. On June 2nd, JPMorgan reiterated its 'Overweight' rating on MiniMax post-M3 launch, with a target price of 1,100 HKD, calling it a 'major upgrade' since the M2 series that will propel MiniMax back to the forefront of China's cutting-edge large model market.
HK Pricing, A-Share Funding—The 'Dual Powerhouses' Return to China: This Game is Far from Over
In May, rumors of DeepSeek's first funding round ignited the market, while StepFun secured nearly $2.5 billion in financing. Earlier, Kimi completed multiple intensive funding rounds in early 2026. From the 'hundred-model battle' to accelerated capital differentiation, China's AI is now in the capitalization phase—shifting from technological faith to commercial realization.
On June 1st, Zhipu announced plans to apply for A-share issuance. MiniMax also recently began IPO counseling for A-shares. After securing international valuations in Hong Kong, both companies are now turning to the STAR Market. Since its HK listing, Zhipu's stock has surged over 12 times, while MiniMax is up over 4 times—capital markets have already voted with their wallets.
But where is the real capital pool? In A-shares.
Daily trading volume on the A-share market has consistently exceeded 1.2 trillion RMB for months. Only a market of this scale can provide large model companies with truly meaningful 'ammunition.'
For pricing, look to Hong Kong; for capital accumulation, look to A-shares.
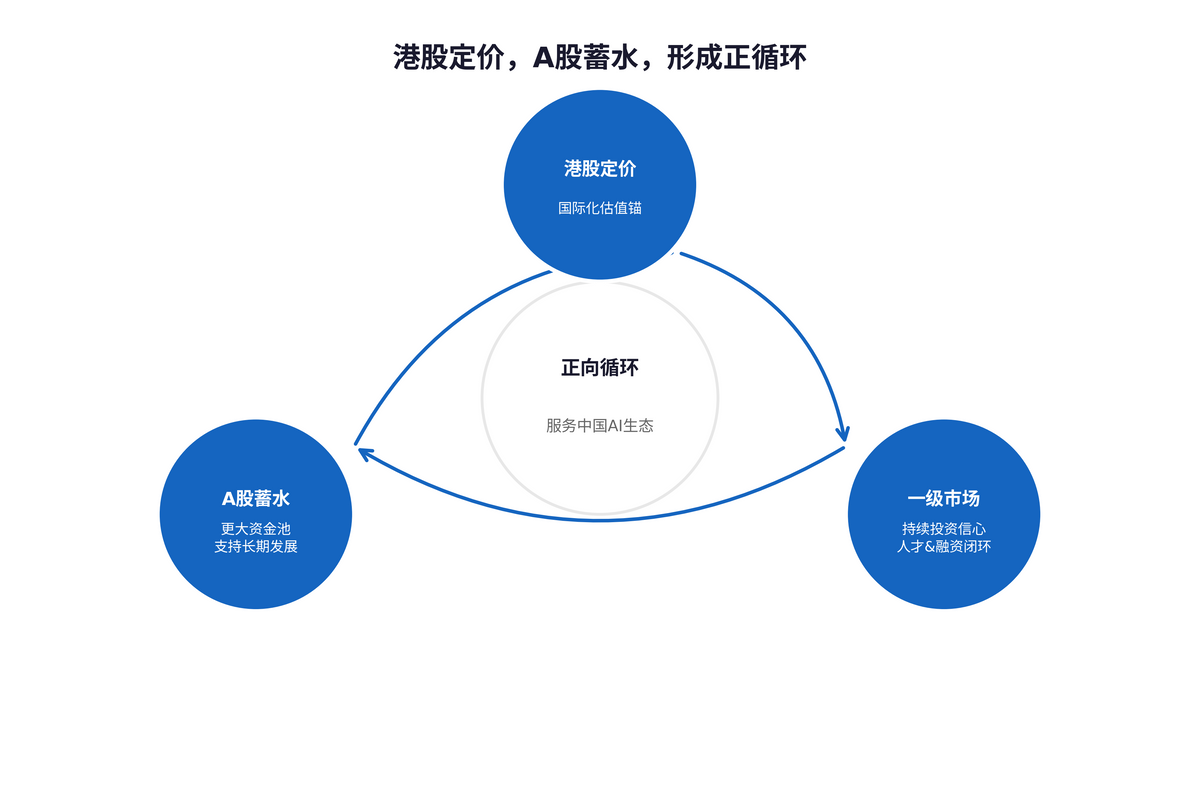
Once this virtuous cycle begins, capital flows, and primary markets gain confidence to keep investing. The positive mechanism of retaining top AI talent through equity incentives can only truly take hold within this closed loop.
Some argue that domestic large models are overvalued—yet Anthropic has filed for a U.S. IPO with a $965 billion valuation. High valuations aren't a flaw; they reflect capital market confidence.
When the 'dual powerhouses' complete their assembly on the STAR Market, A-shares will, for the first time, truly own a core asset allocation line for China's own large models.
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





