RoboArena Dream Shattered! The Embodied AI Ranking Craze Unravels as a Data Deception
 06/22 2026
06/22 2026
 418
418

Text by | Conversational AI Relative Theory
Just two weeks ago, Qianxun Intelligence appeared to be the shining star in the embodied AI landscape.
Firstly, Qianxun Intelligence's self-developed embodied base model, Spirit v1.6, soared to the top of the RoboArena rankings, outperforming NVIDIA Cosmos3 and Physical Intelligence's Pi0.5, and "shattering the Silicon Valley monopoly."
Secondly, Qianxun Intelligence secured a staggering 1.5 billion RMB in Series A+ funding, bringing its total investment to nearly 5 billion RMB within just three months—a record-breaking feat for the embodied AI sector.

These two pivotal milestones, both highlighted in a June 3 WeChat post by Qianxun Intelligence titled 'Dual Triumphs! Qianxun Intelligence's Spirit v1.6 Dominates North American 'Embodied Olympics,' Secures 1.5 Billion RMB in Series A+ Funding,' signaled a convergence of technological leadership and financial reinforcement at a critical juncture. Everything seemed to align seamlessly.
In the post, RoboArena was lavishly described as the 'North American Embodied AI Olympics,' a 'World-Class Authoritative Leaderboard,' and the 'Chatbot Arena for Robotics.' These labels collectively painted a vivid picture: this was no ordinary ranking but a pinnacle event on the global stage.

Capital follows rankings, and rankings bolster funding—a tightly intertwined dynamic.
But within days, the facade began to crumble.
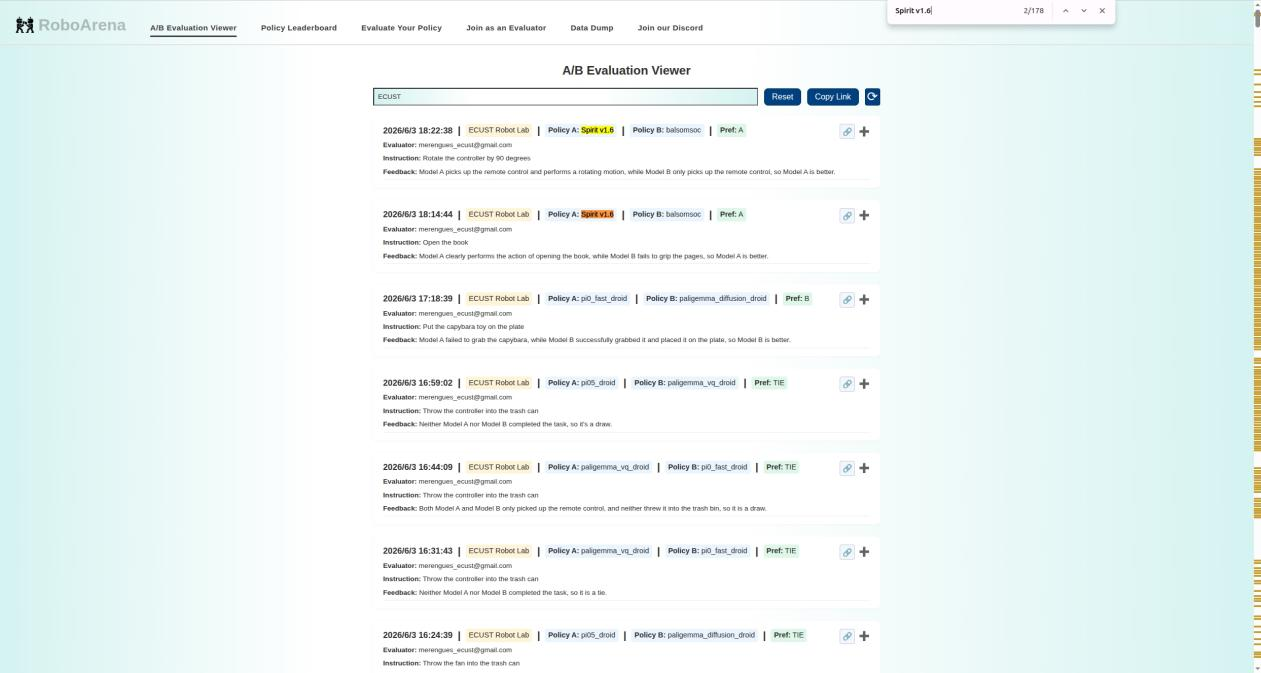
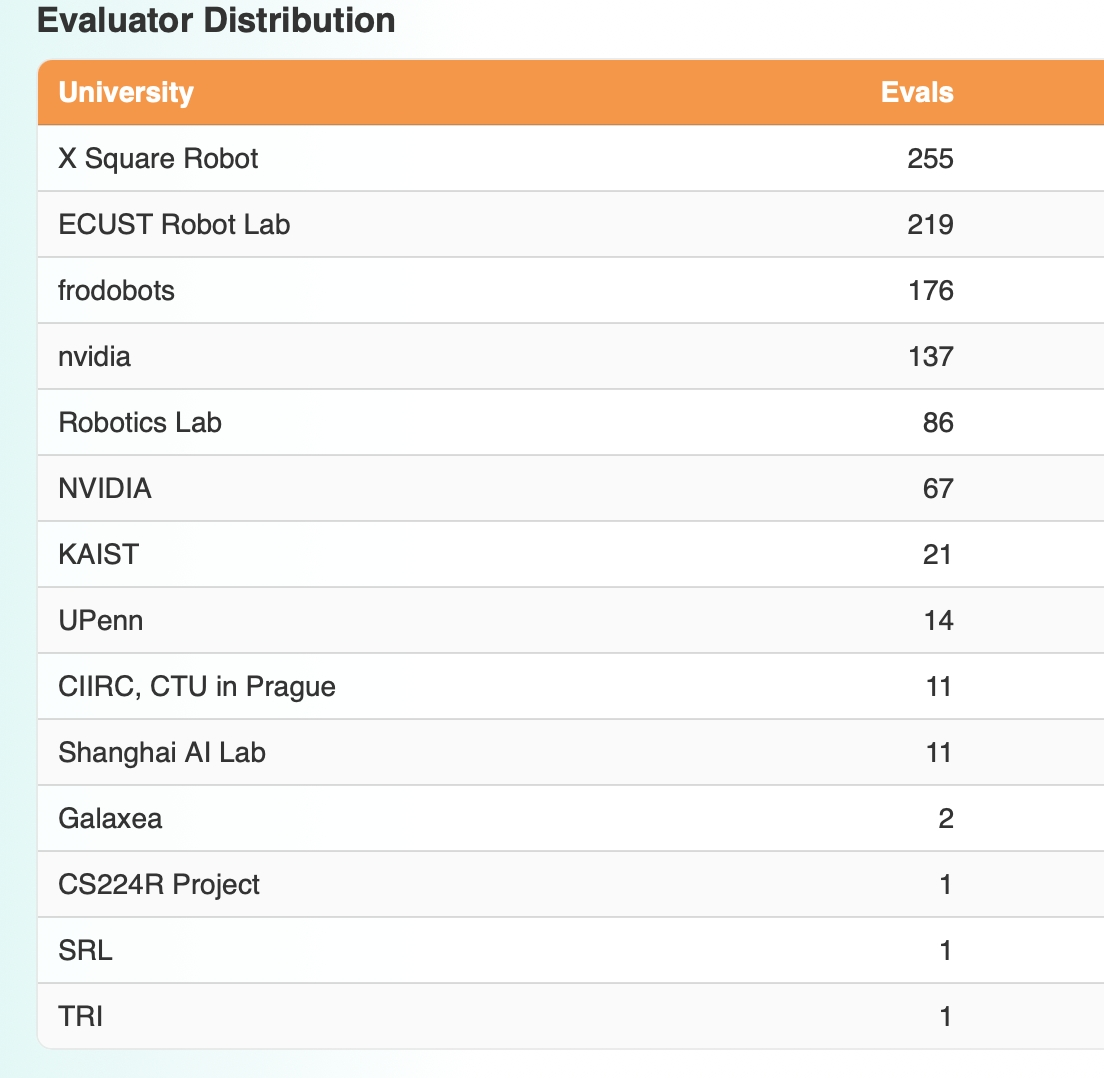
Observers spotted irregularities in Spirit 1.6's evaluation data on RoboArena. Out of 310 evaluation records, 72% of the scores originated from just two accounts—ECUST Robot Lab (179 attempts, 97% win rate) and Robotics Lab (45 attempts, 86.7% win rate). In stark contrast, NVIDIA tested the same model 21 times with a 0% win rate.
More dramatically, RoboArena officials swiftly issued a statement. Following a retrospective investigation, they removed a batch of suspicious evaluation data and updated the rankings. Spirit 1.6's name vanished from the leaderboard.
From inflated rankings to promotional announcements, securing funding, and ultimately being ousted from the rankings—all unfolded within days. Everything happened too swiftly, but objectively, this was no ordinary ranking fluctuation; it was a test of the industry's credibility.
How was RoboArena manipulated in this orchestrated scheme?
Let's first understand how RoboArena operates.
Objectively, RoboArena was not designed as a game that could be easily gamed. Its core logic draws inspiration from the large model domain's Chatbot Arena: evaluators are unaware of which model they are testing (double-blind), opponents are randomly matched via the ELO algorithm, and evaluation data comes from real-world environments across global institutions.
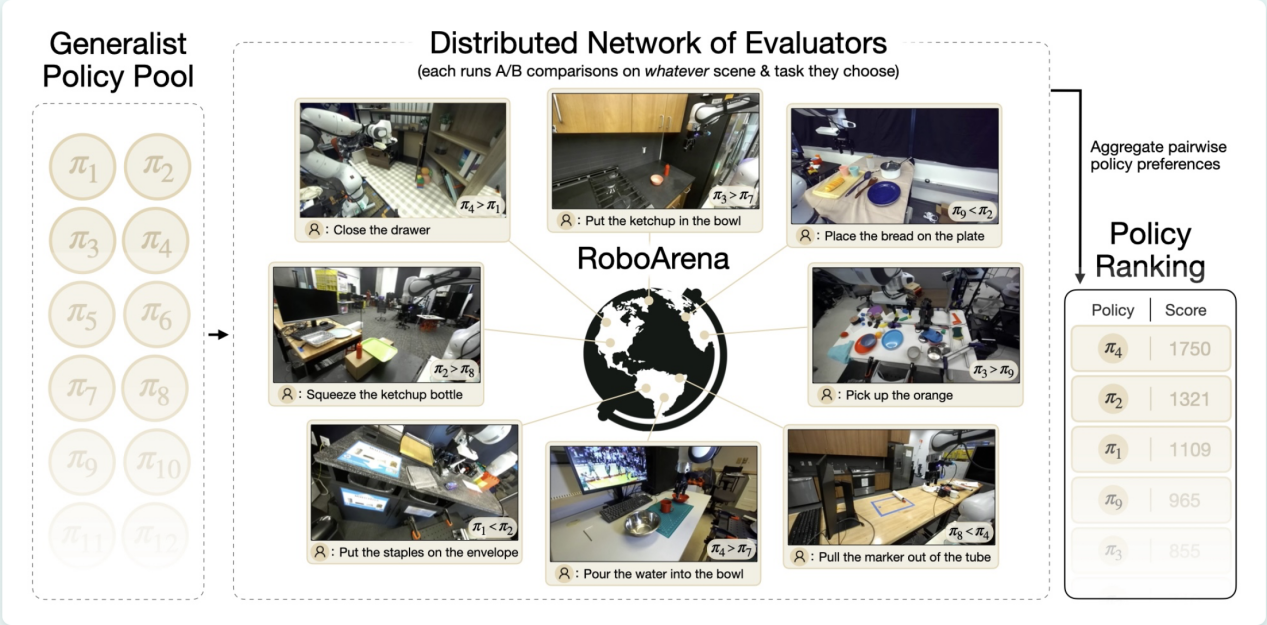
Theoretically, manipulating your own score carries a high barrier. You cannot control your opponent, the evaluation environment, or the evaluator's judgment. This mechanism appears robust against cheating.
But the phrase 'theoretically' often marks the starting point for all vulnerabilities.
Firstly, RoboArena operates as an open-registration distributed evaluation framework. Any institution can register as an evaluator and conduct tests on their deployed robotic hardware.
While this design was originally intended to decentralize and diversify evaluations, it also introduced a simple loophole: to manipulate scores, you just need to register an evaluator account for yourself.
ECUST Robot Lab and Robotics Lab registered into the system on May 26. From that day onward, Spirit 1.6's evaluation records began to surge.
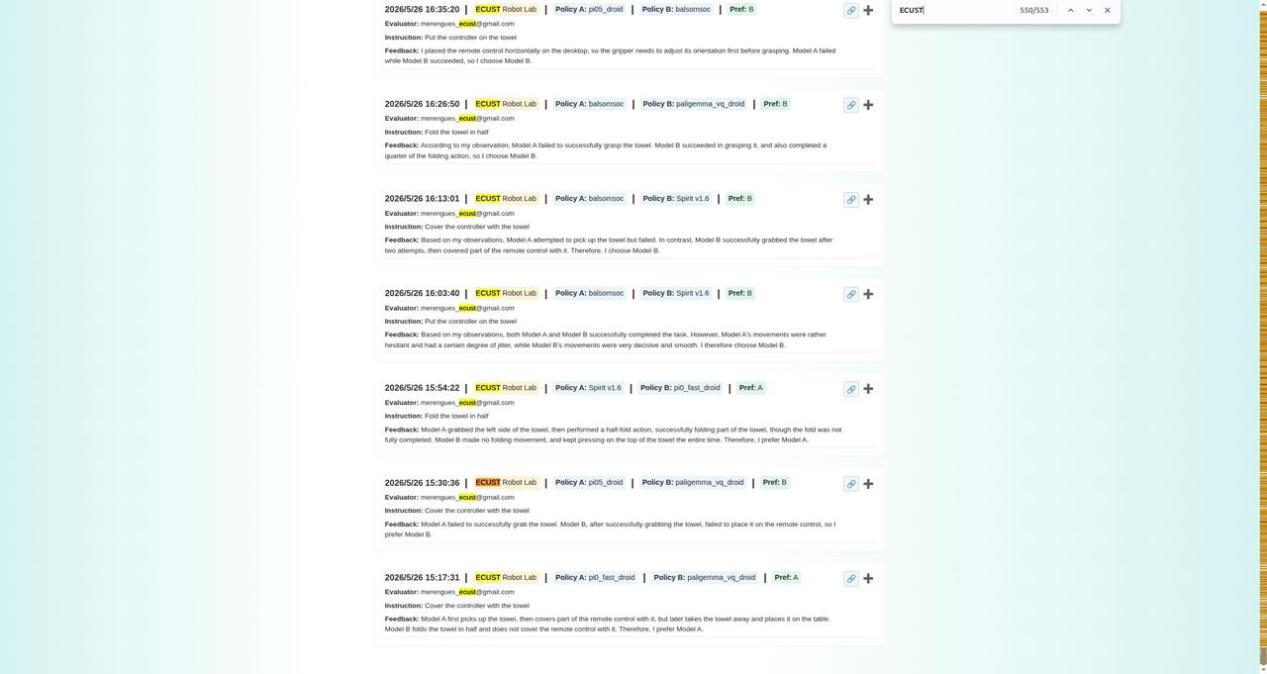
Interestingly, when another embodied AI company, X Square Robot (Autonomous Variables), registered its evaluation account, it directly used its full company name. This move was telling—it essentially tore away the industry's fig leaf, revealing that evaluators were not 'third-party independent institutions' but 'insiders.'
Secondly, under normal circumstances, an evaluator should conduct relatively balanced tests across multiple models on the leaderboard. This is the fundamental logic of a distributed framework—data dispersed among various evaluators gains statistical significance only when aggregated.
However, after ECUST Robot Lab and Robotics Lab joined, they focused almost exclusively on repeatedly evaluating Spirit 1.6. ECUST Robot Lab conducted 276 evaluations, with 179 (64.5%) targeting Spirit 1.6. Robotics Lab conducted 142 evaluations, with 45 (31.7%) on Spirit 1.6. Together, these two accounts contributed 72% of Spirit 1.6's total evaluation data.
72% of the data came from two 'insider' accounts. The remaining 28% originated from genuinely independent evaluators, whose results starkly contrasted with the first two accounts.
The picture was becoming clear.
But there was more.
The ELO ladder mechanism was designed to ensure you only face opponents of similar rankings—the stronger your opponent, the more points you gain for a win and lose for a defeat. This system aimed to prevent ranking inflation by facing weaker opponents—defeating weak teams was inefficient; climbing required defeating stronger ones.
Yet Spirit 1.6's evaluation records revealed a clever workaround: instead of targeting weaker opponents, it avoided stronger ones, strategically sidestepping genuine threats.
Initially, Spirit 1.6 faced the then-leader DreamZero 23 times, resulting in 17 losses, 4 draws, and 2 wins—essentially no match. Afterward, Spirit 1.6 ceased competing against DreamZero, with their last PK recorded on May 31.
Later, when the model that eventually topped the rankings, Cosmos3-Nano-Policy, joined testing on May 30, Spirit 1.6 had zero recorded matches against it.
A model that reached the summit of the rankings had never genuinely competed against the top two contenders. This was not a technical inability to fight fairly but a selective avoidance of all potentially losing opponents at the evaluation strategy level.
By now, the full scope of the score manipulation was clear: first, register two 'insider' accounts into the evaluation system and use them to generate concentrated high-score data for yourself (accounting for 72% of total evaluations). Simultaneously, under the guise of 'random matching,' avoid all truly threatening opponents.
While the ELO mechanism technically remained operational, the ladder rankings' significance had been effectively undermined.
What is the embodied AI industry experiencing behind this ranking frenzy?
Of course, the most unsettling aspect of this incident is not the score manipulation itself but the timeline linking it to funding.
On June 3, Qianxun Intelligence announced Spirit 1.6's RoboArena summit in a WeChat post. On the same day, it announced the completion of 1.5 billion RMB in Series A+ funding, bringing its three-month total to nearly 5 billion RMB.
In the embodied AI sector, where technological paths remain unconsolidated, commercial validation is still in its infancy, and external unified evaluation systems are scarce, RoboArena was rapidly thrust into the spotlight as the most intuitive and capital-friendly 'technological evidence.'
Rankings, after all, are perfectly suited for inclusion in investors' due diligence materials. Unlike academic papers, they consist of numbers and positions that can be directly inserted into funding PPTs. Thus, when rankings directly influence valuations and funding rhythms, the incentive to manipulate them shifts from academic vanity to real financial gain.
However, RoboArena is far from 'authoritative.'
According to public information, RoboArena remains an academic prototype: its initial version was deployed across seven academic institutions, completing approximately 600 real-robot comparisons for seven general strategies, with evaluation hardware bound to the DROID platform (Franka Panda robotic arm) and not yet extended to other robot bodies. The paper's authors also noted the need for ongoing validation of its ranking results' correlation with real-world performance.
In other words, this evaluation framework described as a 'world-class authoritative leaderboard' is still considered a 'promising research direction' in academia, far from an industry-recognized standard.
Yet in Qianxun Intelligence's narrative, all these caveats vanished. RoboArena transformed into a deified 'Olympics.' Clearly, packaging a still-under-validation academic prototype as authoritative certification was essential for the funding narrative to hold.
Today, after the score manipulation was exposed, the consequences extend beyond Qianxun Intelligence alone.
Embodied AI is China's hottest AI sector and one of the most internationally watched. News of this incident has spread overseas. When Chinese embodied AI companies are discussed alongside 'ranking manipulation,' the entire industry's international credibility risks being tarnished.
More troublingly, it harms genuinely diligent companies. After a firm secures nearly 5 billion RMB in funding through ranking manipulation, teams that refrain from such tactics and instead persist in laboratory research face relentless scrutiny: 'Is your ranking genuine? How can you prove it?'
The 'bad money drives out good' phenomenon quietly begins and spreads from here.
If people conclude, 'Since rankings can be manipulated anyway, what's the point of investing in technology?'—that would be the worst outcome of this incident.
Of course, this controversy has its silver linings.
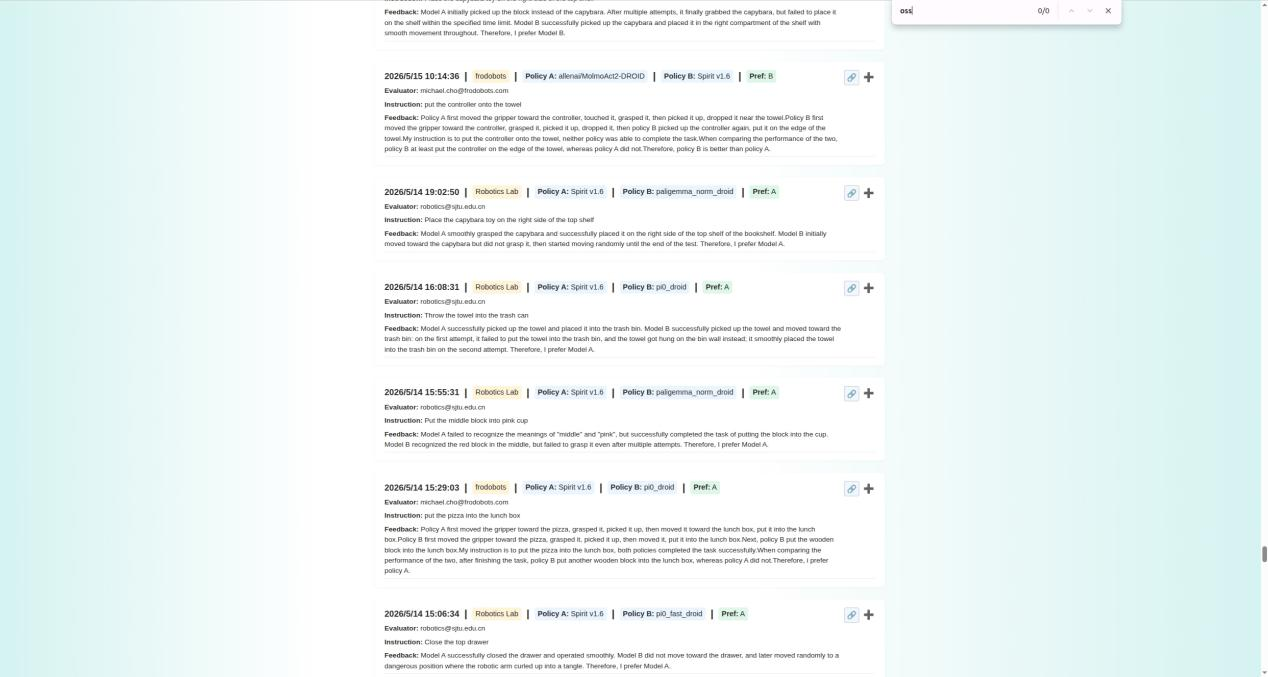
During Spirit 1.6's score manipulation, WALL-OSS was also vigorously competing for the rankings. Unable to find a way to 'exclusively test itself,' it could only compete within the compliant framework, ultimately being crowded out by the two score-manipulating accounts. As a team genuinely adhering to rules and competing on merit, being blocked by this distorted evaluation ecosystem is truly disheartening.
Additionally, Cosmos3-Nano-Policy's summit after the official rankings update proves hardcore strength. Its continued presence on the leaderboard demonstrates that a model achieving its position through legitimate evaluations can withstand retrospective scrutiny.
Admittedly, the rankings themselves are not fake. The presence of manipulation does not invalidate the entire evaluation system, but only if rules can deter those seeking loopholes.
Conclusion
According to the latest news, RoboArena has taken action—conducting retrospective investigations, excluding evaluation data with conflicting interests, and resetting evaluator access rules. This is correct and necessary.

However, this controversy should not end with 'rankings updated.'
The Qianxun Intelligence incident warrants serious attention not because it is rare but because it may not be an isolated case. When an industry's evaluation standards remain immature, yet evaluation results directly influence billions in funding, the incentive to exploit loopholes becomes systemic, not confined to individuals or companies.
The window for funding narratives built on rankings has not yet closed. But through this incident, at least one consensus can now be openly stated: the 'first place' you show your investors must be genuine.
Rankings can be updated, but rebuilding trust is far more difficult.
From today onward, the embodied AI industry has a long road ahead.
*All images in this article are sourced from the internet.
-
![]()
Oil Prices Revert to 7-Yuan Range: Are Gasoline Cars Getting a Reprieve?
-
![]()
Momenta Secures CSRC Approval: Is It Poised to Be the 'Pioneer in Physical AI Stocks'?
-
![]()
What's the Use of Having a General-Purpose Motion 'Cerebellum' for Humanoid Robots?
-
![]()
Volkswagen Starts Operating at a Production Capacity of 9 Million Vehicles
-
![]()
Interpretation of China's Auto Market in May: A Fig Leaf, Two Fault Zones, and Three Surprises
-
![]()
China's Auto Industry Accelerates Expansion in Spain: From Vehicle Sales to 'Local Manufacturing in Europe'
-
![]()
Momenta | Going Public Not for Money
-
![]()
How Much Can Doubao Make by Charging Fees?