Will the Computing Power Shortage Turn China's AI into a Bubble?
 06/23 2026
06/23 2026
 475
475
Yann LeCun, one of the so-called 'godfathers of AI,' recently made a chilling prediction: the bursting of the AI bubble may not be as far off as imagined—it could happen at any moment. This inference also applies to China's AI industry.
His perspective is quite clear: the bubble does not stem from AI lacking value but from it having too much. If the demand for AI cannot be supported by sufficiently low computing power costs, many companies' revenues will fall short of expectations, leading to market capitalization collapses and, consequently, a bubble.
Therefore, what this article truly seeks to explore is not whether Zhipu or Kimi is smarter, nor whether DeepSeek's approach is more brilliant, but a more pragmatic question: When everyone is queuing for tokens, can China establish a free, abundant, and continuously price reduction (price-reducing) production capacity to underpin its AI supply chain?
If we possess sufficient and affordable token production capacity when the computing power explosion arrives, today's rationing will merely be congestion before dawn. If we fail to build this chain, what the computing power shortage will produce is not just a particular product characteristic—but a bubble and its explosive aftermath.
—Introduction
Yann LeCun, one of the so-called 'godfathers of AI,' recently made a chilling prediction: the bursting of the AI bubble may not be as far off as imagined—it could happen at any moment. This inference also applies to China's AI industry.
In a June 18 CNBC interview, he presented a straightforward economic calculation: while the prices of high-end AI products continue to rise, the cost of tokens required to run them is decreasing too slowly—so slowly that nearly all companies are using investor funds to subsidize users.
His reasoning is simple: if the cost of tokens remains unimproved, the closed loop of super valuation-super market cap-rapid revenue growth will not hold. If the entire industry falls into this deadlock, proving that cutting-edge AI cannot generate sufficient revenue, the bubble will 'not last long.'
This is not alarmist talk.
Elon Musk's xAI, valued at $2 trillion after merging with SpaceX, lost $2.5 billion in one quarter while generating just over $800 million in revenue. Anthropic, the maker of Claude, spends $1.25 billion monthly renting Musk's cards to run its models. Even the usually defiant OpenAI has conceded, with Sam Altman admitting that costs are now 'a huge problem.'
This is an old tactic from the internet era—using investor money to subsidize users, first scaling up rapidly, then seeking commercialization opportunities. If none are found, the bubble will burst. AI is gambling even bigger: everyone is betting that inference costs will continue to decline, eventually outpacing burn rates. If they win, a new AI era dawns; if they lose, it will be the same mess as after the dot-com bubble.
The key lies in having sufficient and affordable token production capacity. Currently, China's AI seems to have hit this computing power capacity wall.
This June, several of China's strongest programming large models debuted: on the 13th, Zhipu open-sourced GLM-5.2, whose coding ability once ranked second globally, trailing only Claude; Kimi released K2.7 Code, specialized in programming; MiniMax unveiled M3, focused on intelligent agents. Yet, almost simultaneously, these companies did the opposite—restricting purchases.
Now, Zhipu's packages must be snatched up daily, with prices tripling in a year. Kimi and MiniMax's interfaces are frequently overloaded, with developers queuing for tokens. The giants fare slightly better, but their high-end lines also face computing power shortages, issuing multiple warnings to users.
What should ideally support future market value through infinite supply has become a 'rationed supply' reminiscent of economic scarcity—a stark irony.
But the warning signals are real and clear: if a company selling digital products begins restricting purchases, it admits that what it sells is no longer infinitely replicable software but industrial goods with limited production capacity. This is the first alarm from China's AI production capacity pool.
More critically, if operational costs never decline, what follows this alarm is not just rationing—but the bubble LeCun warned about, and its explosive aftermath.
The current computing power shortage was not caused by C-end daily active users like Doubao. What truly drove demand skyward is this year's collective bet by Chinese and even global large models on AI programming and intelligent agent scheduling frameworks.
No matter how verbose a chat may be, it consumes only a few thousand tokens at a time. A programming agent, however, must devour entire codebases, repeatedly run commands, modify files, and self-inspect—when MiniMax demonstrated M3 by having it independently reproduce a paper, it ran for nearly 12 hours. Such tasks consume tokens at dozens or hundreds of times the rate of chatting.

Thus, on the same day MiniMax released M3, it abandoned its long-used monthly subscription model for token-based billing, with heavy users reporting costs doubling or tripling.
American practitioners have calculated even starker ratios: one developer tracked tokens burned using Claude and ChatGPT's $200 monthly plans, arriving at the precise figure of $2,048—exactly ten times the original cost.
The days of 'unlimited monthly usage for a few dozen dollars' appear to be over. Moreover, this will not be an isolated case—the pricing logic of infinitely replicable software is deemed unsuitable for AI, being replaced by capacity-based pricing. This will become the industry norm.
Logically, these companies should not lack computing power. Zhipu is backed by Tencent, Alibaba, Ant Group, Meituan, and Xiaomi; Kimi's largest shareholder is Alibaba, holding a 40% stake, with Tencent also participating. With such powerful cloud computing backers, rationing should not affect them.
The issue is that the backers themselves are running low on resources.
The 2026 computing power shortage is not due to a single component shortage but a simultaneous depletion across chips, storage, packaging, networking, and data centers. Industry experts predict this tension will last at least two more years.
An ICT vendor representative put it bluntly: 'Two million yuan used to buy eight GPU servers; now it buys four or five. Vendors would rather breach contracts than deliver.'
In March, Tencent Cloud led with price hikes for some of its Hunyuan products, with individual (individual) prices surging fourfold. Alibaba Cloud and Baidu Cloud followed within hours. Even large model companies with robust AI cloud foundations face shortages—this is the current reality of China's AI production capacity.
Of course, pricing is not uniformly rising. DeepSeek permanently reduced V4-Pro interface prices to a quarter of the original, with Xiaomi's MiMo slashing costs by 90%. Tencent Cloud cut prices for DeepSeek models hosted on its platform by 97%—caching reduced invocation costs to two and a half cents per million tokens, cheaper than a phone call.
This seems contradictory to 'capacity shortages,' but it aligns with the rationing dilemma: they represent two ends of the same shortage. Price cuts come from efficiency-focused players like DeepSeek and Xiaomi, which optimize caching and sparse architectures to drive down costs. Rationing affects in-demand programming models like Zhipu's, where higher capability fuels higher demand. Even Tencent hedges its bets—raising prices for its Hunyuan models while subsidizing others' DeepSeek. Prices are not uniformly rising or falling but diverging by tier.
More tellingly, the tacit understanding (tacit understanding) between startup model companies and capital backers has subtly shifted.
When internet giants invested in these model companies—especially those developing their own AI—they had two motives: technically, backing an external team as insurance for self-research; commercially, binding a long-term customer through capital—'you take my money and buy my computing power, creating a win-win.'
But when computing power becomes scarce, this 'VIP' invested client tastes the flip side of binding: some cloud giants openly prioritize scarce computing power for their high-value businesses, relegating invested startups to the back of the queue. Ultimately, your landlord, creditor, and competitor are often the same entity.
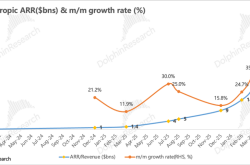
Thus, interfaces remain overloaded, packages rationed, and money burned regardless. According to prospectuses, Zhipu spends 70% of R&D budgets on computing power, accumulating $6.2 billion in losses over three and a half years. MiniMax, also spending 70% on computing power R&D, lost about $9.2 billion in the same period, with its annual procurement cap from Alibaba Cloud rising yearly.
This shows a consensus: binding no longer guarantees priority. What remains is an unsolvable dilemma: with limited capacity, only those who can afford it and endure will survive.
Cornered, a new idea emerges: if backers are unreliable, can companies rely on themselves?
The relationship between model companies and investors was once a mutually beneficial arrangement: you invest, I buy your computing power, you profit, I gain capacity. But when the backer's pool runs shallow, this tacit understanding (tacit understanding) crumbles. Model companies must awaken from this seemingly win-win dream and find their own path.
Only two routes exist: squeeze efficiency to the extreme or embrace domestic production capacity.
The former will be discussed next; first, adapting to domestic chips—a path where the general direction aligns. Zhipu entrusted GLM-5's training cluster to Huawei's Ascend, delivered exclusively by Digital China using Ascend and Kuntai servers. It also trained GLM-Image entirely on domestic chips earlier this year, creating the first top-tier multimodal model trained domestically.
DeepSeek went further. Its April V4 release, despite delays, premiered on Huawei's Ascend, rewriting its entire low-level code (underlying code) from NVIDIA's CUDA to Huawei's CANN to signal controllable production capacity.

Zhipu's and DeepSeek's adaptations to Ascend are essentially the same. Yet, they diverged further.
Zhipu still relies on cloud providers and shareholders for computing power; DeepSeek began moving upstream: hinting at short-term profit indifference while aggressively recruiting data center construction and management talent, pointing to self-built gigawatt-scale computing bases.
Most telling was its June funding round: founder Liang Wenfeng contributed about $20 billion as the largest investor, excluding others from the board. His resoluteness likely aims to prevent shareholder interference in this aggressive plan. If successful, it would make DeepSeek China's first pure model company with self-built massive computing infrastructure, forging a third path beyond startups and giants.
Alas, awakening is one thing; success is another. Everything hinges on domestic hardware—how robust is it?
By market share, the numbers are encouraging: domestic AI chips captured 40% of China's market in 2025, with Huawei leading at nearly half and Cambricon's revenue surging over twentyfold annually.
Zoom in, and the picture is less rosy. In single high-end chips, NVIDIA's flagship models still outperform Huawei's Ascend by four to six times on multiple metrics. Huawei must interconnect hundreds of chips via optical modules into super nodes to match or exceed NVIDIA's cluster performance, at nearly quadruple the power consumption.
Domestic hardware now offers 'viable' alternatives, not superior ones. The entire sector also faces supply shortages—awakened players see the direction, but the path to embracing domestic capacity is itself bottlenecked by capacity.
Building infrastructure and moving upstream is a long-term solution. Immediate needs can only be met by boosting efficiency through software-hardware collaborative engineering. In a sense, when computing power lacks freedom, a company's product character changes first.
Kimi's approach is embedding efficiency into its architecture.
Its inference runs on Mooncake—a cache-centric architecture that separates 'prefilling' and 'decoding' stages for separate scheduling, then pools and reuses computed KV caches across the cluster, enabling the same GPUs to serve more requests. It remains deeply tied to Alibaba Cloud, using elastic computing combinations to enhance task stability and utilization while self-developing security gateways to avoid heavy Self built computer room (self-built data center) burdens.
Mooncake founder Yang Zhilin frequently mentions 'token efficiency,' citing his team's MUON optimizer, which doubles learning efficiency as proof. He is sober (sober)—competition now hinges on inference system efficiency, not resource stacking.
Zhipu's answer is turning efficiency into a sellable product, almost brutally through engineering. Its high-speed inference engine, TileRT, statically orchestrates entire computation graphs into persistent GPU kernels during compilation, pushing flagship model output to ~400 tokens per second. Its ZCube network architecture, developed with Tsinghua University, boosts inference throughput by 15% without adding GPUs or modifying code, cuts networking costs by a third, and reduces Initial response (first-character response) tail latency by 40%. Its GLM-5 integrates sparse attention to maintain million-scale context while cutting inference costs. These efficiency gains are packaged into privatized devices deployable in customer data centers, sold to governments and enterprises.
Their focuses differ, but they point to the same reality: China's leading companies now compete not just on model intelligence but on unit token production efficiency.
Scarcity breeds innovation—a good thing. This may be a path Chinese companies persist on, but it is not globally optimal. Obsessing over efficiency carries performance trade-offs—a constraint-born strength bears the mark of that constraint.
Across the Pacific, U.S. frontier companies also largely avoid building their own data centers. Thus, DeepSeek's approach is not copying U.S. homework.
OpenAI orchestrates partnerships. Its Stargate plan, with $500 billion over four years and 10 gigawatts, has partners like Oracle and SoftBank fund and build data centers exclusively for OpenAI. Microsoft continues providing cloud services alongside Oracle and CoreWeave, while OpenAI partners with Broadcom to design custom chips. It seeks not a single backer but an infrastructure alliance where suppliers, financiers, and power providers revolve around its capacity needs—a strongly controlled infrastructure alliance.
Anthropic pursues a multi-cloud, multi-partner, multi-long-term-contract strategy. It binds Amazon Web Services as its primary training partner, with a supercluster of over a million chips dedicated solely to training Claude, owned by Amazon but reserved for Anthropic. It signs a $100+ billion, ten-year deal with Amazon (up to 5 gigawatts) and a multi-billion-dollar deal with Google for 1 million TPUs, while also spending $1.25 billion monthly renting Musk's idle cards. The result: it spans multiple chip architectures without exclusive cloud agreements, retaining full control over model weights and pricing—a multi-partner contractual computing pool.

There may seem to be two different paths, but there is only one prerequisite: the most valuable parts of the AI industry chain—advanced chips, mature cloud platforms, self-developed accelerators, data centers capable of securing billions in financing, accessible electricity, and a global customer base—are mostly located domestically or within allied systems. Therefore, what concerns U.S. companies has never been whether they have computational power, but how high the ceiling of computational power can be raised: as alliances expand, the ceiling keeps rising. Currently, this ceiling is much higher for U.S. companies than for Chinese companies.
Although Chinese companies can also secure financial backers and form strategic alliances, the key difference is that the support they rely on is also standing in the same constrained supply chain, waiting in line.
The story on the demand side has been told enough—once intelligent agents explode in popularity, Token consumption will double every two weeks; according to IDC's forecast, by 2030, global annual Token consumption will increase more than 300 million times compared to 2025. Nearly every optimistic article calculates the same thing: how many Tokens China will burn each day in the future, as if burning more equates to greater prosperity.
But few people turn around to ask: Who will produce these Tokens? With what chips? In which data centers? Who pays the electricity bills? When programming intelligent agents account for half of all productivity scenarios, who ensures that services won't suddenly be throttled, queued, or see price hikes?
Token consumption represents demand-side prosperity, while the production capacity pool reflects supply-side reality—focusing solely on the former is a false sense of prosperity. The real keyword has never been 'computational power,' but 'production capacity': chips, memory, interconnectivity, electricity, data centers, scheduling, and pricing mechanisms. Only with this entire system can intelligence be produced continuously and at increasingly lower costs.
After all this, we return to Yann LeCun's assertion—whether through purchase restrictions, card rationing, or embracing domestic production capacity, it ultimately comes down to one race: can costs be reduced before the money runs out?
Cost reduction is crucial. For China's large model market this year, whether by raising prices for cutting-edge models or capturing the market with affordable models through price cuts, the essence remains the same—whether prices soar or crash to the floor, if companies continue to bleed money, it shows that the bursting of the bubble is not just the ramblings of optimists.
China has hit this wall earliest and hardest. Others are cutting costs amid abundant computational power, while China is cutting costs amid scarcity. Both time and scarcity are less forgiving to China's AI industry. But if this problem remains unsolved, what collapses won't just be the market value of one or two companies, but the entire cycle supporting AI—users subsidizing services with investor money, investors waiting for cost reductions to deliver returns. If those reductions never come, the cycle will collapse entirely. By then, the so-called prosperity will be nothing more than another expensive graveyard of shared bicycles.
So what this article truly seeks to ask is not whether Zhipu or Kimi is smarter, nor whether DeepSeek's approach is more brilliant, but a more practical question: when everyone is waiting in line for Tokens, can China build a set of free, abundant, and continuously price reduction -capable production capacities to support its own intelligence?
If it can, today's purchase restrictions will merely be congestion before dawn. If not, what is forced by computational power constraints will no longer be just a product characteristic—but a bubble, and the sound of it bursting.
-
Three-Year Cumulative Losses Reach 4.4 Billion! Can AI Revolutionize Yonyou’s Future?
-
![]()
Zhipu: Trillion-dollar Market Cap, Is China's Anthropic Really Here?
-
![]()
Why Are Automakers Hesitant to Offer Consumer Guarantees?
-
![]()
Targeting 12 Million in Exports! China’s Auto Industry Faces a Pivotal Test of Maturity
-
![]()
One in Six Employees at Volkswagen Faces Layoffs Amidst Largest Strategic Retrenchment in 88 Years
-
![]()
Breaking Free from Involution: How These Four Automakers Are Charting New Courses
-
![]()
From National Pride to WPS Controversy: The Dilemma Faced by Zou Tao of Kingsoft Office
-
![]()
He Xiaopeng: Ant Group's 'AI Visionary'