NVIDIA Goes Wild! DeepSeek V4 Inference Costs Slashed by 80%
 07/02 2026
07/02 2026
 400
400
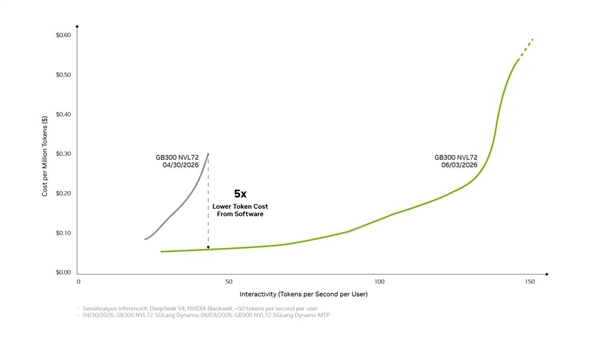
Kuaikeji, July 2nd news: NVIDIA announced that its Blackwell platform, through full-stack inference software optimization, has reduced the cost per token for the DeepSeek V4 model by up to one-fifth within a month.
As enterprises transition from AI pilots to production-scale AI factories, infrastructure decisions have shifted from peak chip specifications to how many useful tokens can be delivered per yuan, per watt, and within latency targets.
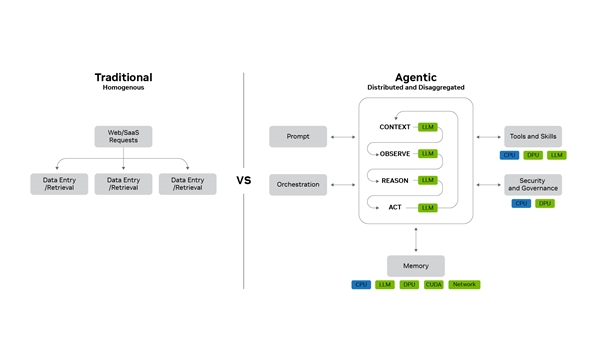
NVIDIA has achieved a significant reduction in token costs through a three-tier architecture. The production operations layer handles distributed service orchestration and auto-scaling, the application acceleration layer optimizes runtime through compute-communication overlap and kernel fusion, and the infrastructure access layer directly leverages GPU, networking, and system capabilities.
With multiple technologies combined, the Blackwell platform can increase token throughput per GPU by up to 20-fold. These technologies include disaggregated services, large-scale expert parallelism via NVLink, NVFP4 precision, and multi-token prediction.
NVIDIA has identified cost per token as a core metric for AI's total cost of ownership, with the Blackwell platform reducing it to the industry's lowest level.
Multiple inference service providers have already benefited. Baseten leveraged the TensorRT-LLM open-source library to serve DeepSeek V4 Pro on Blackwell, boosting token output per second by up to 50%.
Cognition utilized the Dynamo inference framework to manage GPUs, enabling scalable reinforcement learning workloads without building from scratch. Together AI employed TensorRT-LLM to accelerate Cursor's path from model optimization to production endpoints.
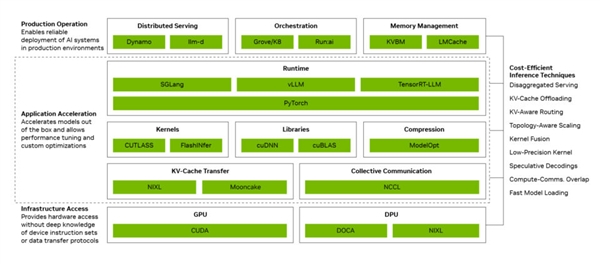
The open-source ecosystem has further amplified full-stack advantages. Mainstream frameworks like PyTorch are natively built on CUDA, enabling new research findings to run immediately on NVIDIA GPUs.
After DeepSeek V4's release, frameworks like vLLM and SGLang promptly provided deployment solutions for Blackwell, achieving up to a 5-fold performance improvement within a month.

-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?
-
![]()
NVIDIA Goes Wild! DeepSeek V4 Inference Costs Slashed by 80%