DeepSeek V4: Chinese Computing Power, Chinese Model, Chinese Pace
 04/27 2026
04/27 2026
 497
497

After much anticipation, DeepSeek V4 has finally been released. Since the beginning of the year, the industry has been eagerly awaiting V4, watching for the release date, the technical report, and the model's deployment. On April 24th, the other shoe finally dropped.
DeepSeek V4 was officially released and made open-source simultaneously. On the same day, Huawei Cloud announced its initial compatibility.
On this day, three significant events are worth noting:
The first event: AI computing power has finally entered the era of widespread accessibility, and this time it is an open-source model that is leading the way.
The second event: This release is compatible with domestic chips such as Huawei's Ascend.
The third event: Companies like Kingsoft Office and 360 have already integrated DeepSeek's new model via Huawei Cloud. As soon as the model went live, applications were already running on it, demonstrating that the cloud is the optimal platform for AI deployment.
These three events each carry significant weight. Together, they represent a watershed moment where China's AI ecosystem transitions from quantitative to qualitative change.
01
Huawei Cloud's In-Depth Optimization for Initial Compatibility
Huawei Cloud has achieved initial compatibility with the DeepSeek-V4 model.
The compatibility of DeepSeek V4 presents greater technical challenges than previous iterations. It is understood that the biggest technical hurdle for this adaptation comes from the comprehensive innovation in the model's architecture itself. According to engineers in the industry, “The Deepseek V4 model represents a significant innovation compared to previous models, with nearly complete reinvention in the Attention module and the introduction of the innovative Compressor module. This necessitates entirely new development and tuning for both model adaptation and operator adaptation.”
The greatest challenge arises from supporting the adaptation of 1M long contexts. Over the past year, the context window of models has been a focal point of industry competition. From GPT-4's 32K to Claude 3's 200K, and then to Google Gemini's breakthrough to 1M, million-level context windows are becoming the new standard for leading models. The advent of V4 also brings data to the million-scale level.
Moving from 256K to 1M is not merely a numerical increase but represents a comprehensive upgrade in KVCache (Key-Value Cache) management, inference platform stress testing, and memory scheduling capabilities. Facing this challenge, Huawei Cloud has implemented three-tier collaboration at the system, operator, and cluster levels.
The first tier is system-level scheduling optimization with PD separation scheduling. The Attention architecture in V4 introduces a new Compressor module, resulting in a completely different management logic for KvCache compared to the past. Huawei Cloud has taken several actions: First, it modified the KvCache management module in vLLM to efficiently allocate and manage different KvCache Groups, a new requirement under the V4 architecture. Second, it redesigned the PD separation module. PD refers to the two stages of Prefill and Decode. Previously, these stages were computed together, but their computational characteristics differ significantly. The core of PD separation scheduling is to allow Prefill and Decode to run on computational resources suited to their respective needs, decoupling the computational pathways, enabling independent scaling, and implementing refined scheduling to improve first-token latency, incremental latency, and overall throughput performance.
The second tier involves operator-level computational optimization through fused operators. Relying solely on general-purpose operators is insufficient for adapting V4. The Compressor module in V4 integrates numerous small operators, and using traditional atomic operators to call them one by one would result in Kernel startup overhead becoming a critical performance bottleneck. Huawei Cloud's solution is to fuse operators, combining multiple small operators into a single “large operator” for one-time execution. Particularly, the LI operator and Compressor operator incorporate numerous small operators, significantly reducing the Kernel Launch overhead of operators. Through operator fusion, layout optimization, and memory access reordering, single-card execution efficiency and end-to-end performance are enhanced.
The third tier is cluster-level architectural optimization through interconnected storage. The large-scale deployment of V4 relies on multi-machine, multi-card parallelism. Weight loading, KV Cache sharing, cross-node communication, and intermediate state transmission can each become bottlenecks. The interconnected storage architecture addresses bandwidth, latency, and consistency bottlenecks, supporting stable expansion under large-scale parallel deployment.
Through the synergy of these three layers of optimization, new model compatibility and high-performance implementation are ensured from the perspectives of scheduling efficiency, computational efficiency, and data flow efficiency.
One additional detail is that V4 employs FP4+FP8 mixed-precision training. In the context of detach (divorcing from) NVIDIA's ecosystem, this low-precision mixed training scheme is likely based on a deeply customized internal format. Combined with the recent news that the Ascend 950 super node not only fully supports FP8/MXFP4 but also introduces a self-developed, efficient HiF8 data format, this indirectly confirms that Huawei's underlying computing power architecture and low-precision mixed training technology are capable of supporting trillion-parameter large models.
02
Affordable Million-Level Contexts
Just over a year ago, the release of DeepSeek-V3 made waves in the industry.
DeepSeek acted like a catfish, bringing the price of AI large models down from “exorbitant” to “accessible to all.” The cost of API calls was one-hundredth that of GPT-4, yet the performance could go head-to-head with it. This is the most lasting impression DeepSeek has left on the entire industry.
However, over the past year, the industry's playing field has changed. From the explosion of AI Agents to the widespread adoption of million-character long texts, token consumption has surged exponentially. The industry now faces a paradox: AI is becoming more useful, but it is also becoming more expensive.
Therefore, the market's greatest expectation for V4 is not just an increase in technical specifications but rather: When will million-level AI accessibility truly be realized?
DeepSeek has responded: From now on, 1M contexts will be the standard for all official DeepSeek services. At the same time, it continues to maintain a strong competitive edge in pricing. V4-Flash input (cache hit) is priced at 0.2 RMB per million tokens, while V4-Pro limited-time discount input (cache hit) is as low as 0.25 RMB per million tokens. It is expected that the Pro price will be significantly reduced after the batch launch of the Ascend 950 in the second half of the year.
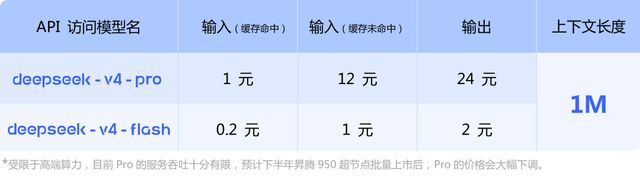

The confidence behind this “more for the same price” approach stems from the deep convergence of two technical routes.
The first route is DeepSeek's “cost-effective” approach at the algorithmic level. From V3 to V4, DeepSeek has delved deeper into the Mixture of Experts (MoE) route. V4 features 384 experts per layer, with 6 experts activated each time. Through this extremely fine-grained expert segmentation and intelligent routing, V4 doubles the model parameters and enhances capabilities while keeping the actual activated computational load within a reasonable range. In simple terms, users do not need to pay for the “dormant” parameters in the model.
The second route is Huawei Cloud's computing power support at the infrastructure level. Reducing model costs is just the first step. To make the technology truly “affordable,” cloud computing power must also become more accessible. Huawei Cloud plays the role of the “popularizer” here. First, it lowers barriers to entry. Huawei Cloud's MaaS platform provides developers with a deployment-free, one-click V4-Flash API calling service. Small and medium-sized enterprises and developers do not need to worry about the underlying chips and can access the platform without managing clusters themselves. Second, it expands coverage. Currently, Huawei Cloud is compatible with over 160 mainstream large models in the industry. Whether for large-scale enterprises or startup teams, suitable access methods can be found within Huawei Cloud's AI infrastructure. Finally, it continuously optimizes costs. Through model distillation, quantization compression, and efficient inference, Huawei Cloud has reduced the barrier to using million-level contexts to a highly commercially competitive level, making “affordability” a reality.
This accessibility is not simply a “price reduction promotion” but is built on the three-tier collaboration of “Ascend chips—CANN heterogeneous computing architecture—Huawei Cloud services.” It is the result of hardcore engineering capabilities.
Of course, the breakthrough of domestic computing power did not happen overnight. According to DeepSeek, due to the current limitations in high-end computing power supply, the service throughput of V4-Pro is still constrained. However, it also sets a clear expectation: After the batch launch of the Ascend 950 super node in the second half of the year, there is further room for price reductions.
The continuous decline in computing power costs will not only drive software adoption but also directly trigger the rapid proliferation of intelligent edge devices. When the inference cost for million-character contexts drops to a few cents, AI will break free from the confines of cloud-based SaaS and accelerate its spread to AI PCs, smart cars, embodied robots, and even the vast IoT ecosystem. Edge devices will no longer be constrained by expensive local computing power bottlenecks. By connecting to the cloud, they can instantly access the smartest “brains.”
The ultimate goal of AI accessibility is to become as ubiquitous as water and electricity. The significance of water conservancy projects is not to make every household buy a water pump but to turn on the tap and have water flow. Similarly, the significance of computing power accessibility is not to have every enterprise stockpile expensive GPUs but to enable on-demand access through the cloud. Here, Huawei Cloud serves as the “silicon-based black soil” of the AI era.
03
This Time, Chinese Computing Power Stands Tall
On the same day as the release of DeepSeek V4, national-level software companies like Kingsoft Office and 360 completed the integration of the new model via Huawei Cloud.
Do not underestimate this “Day 0” synchronous launch. In the past, the release of large models was often a “futures” event. After the model was released, the application side had to wait for platform debugging, computing power availability, and interface stability, resulting in significant delays. This time, as soon as the model went live, core business scenarios for millions of users were already running on it.
This underscores a harsh but exhilarating industrial reality: Only when the underlying computing infrastructure is robust can upper-layer commercial applications run so smoothly. For a long time, the development of China's AI industry has been overshadowed by a Sword of Damocles—heavy reliance on overseas high-end GPU ecosystems. Breakthroughs in individual technologies are not uncommon, but they are difficult to string together into a complete commercial pipeline.
The initial compatibility and large-scale deployment of DeepSeek V4 on Huawei Cloud is not just a business success but also a striking ecological transformation: China's AI industry is substantially crossing the CUDA blockade and migrating toward a domestic intelligent computing ecosystem centered on “Huawei Ascend hardware + CANN heterogeneous computing architecture.”
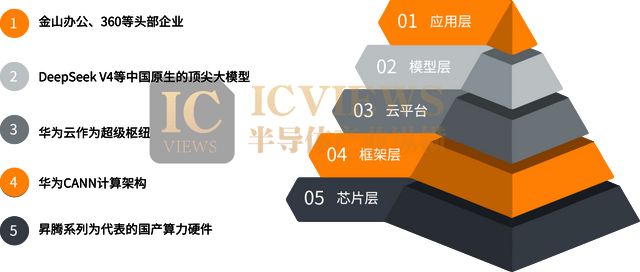
This marks the formation of a truly domestic AI full-stack closed loop. Here, we see “handshakes” at five levels: At the chip level, domestic computing hardware represented by the Ascend series has truly withstood high-pressure testing. At the framework level, underlying software such as Huawei's CANN computing architecture has achieved deep optimization for complex operators and trillion-parameter scheduling. At the cloud platform level, Huawei Cloud, as a super hub, transforms rigid underlying computing power into flexible, callable services. At the model level, DeepSeek V4, as a top-tier Chinese-native large model, provides a world-class intellectual engine. At the application level, the rapid integration by leading companies like Kingsoft Office and 360 completes the final piece of the puzzle, transforming AI into actual productivity.
The complete domestic chain of “model-chip-server-cloud platform-application” has been established for the first time and tested in a real commercial environment. This means that China's demographic dividend and vast data resources can finally run on Chinese-owned computing networks and model architectures.
This time, Chinese computing power is no longer a backup plan in NVIDIA's shadow but has truly taken its place at the table.
04
Conclusion
At the end of DeepSeek's official V4 release article, there was a quote: “Not seduced by praise, not frightened by slander, follow the path, and remain upright.” This sentiment is particularly restrained and sober amid today's fierce competition among large models.
What exactly is the “path” in the era of large models?
It is about returning to the fundamentals of business and technology. For DeepSeek, its path is to relentlessly push algorithmic limits, using a geek spirit to make models lighter and capabilities stronger. For Huawei Cloud, its path is to take root downward, becoming the most solid foundation for China's AI industry.
Bringing high-end models with million-character contexts down from their pedestal and enabling tens of thousands of developers and businesses to access them seamlessly via APIs requires overcoming countless operator optimization challenges and withstanding the pressure of large-scale cluster scheduling. What Huawei Cloud is doing is taking on the most arduous, heavy, and foundational “dirty work,” leaving complexity to the computing power platform and delivering simplicity and accessibility to the application ecosystem.
The development of China's large models has moved past the frenzy of blind benchmarking and entered the deep waters of infrastructure and cost competitiveness.
In these deep waters, we need disruptors like DeepSeek to define the upper limits of “Chinese models” and evangelists like Huawei Cloud to solidify the foundation of “Chinese computing power.” When models and computing power achieve such deep integration, and when technological innovation and commercialization form a closed loop, this is the unique “Chinese pace” of China's AI industry.
-
![]()
AI Giants Start Borrowing to Fuel Computing Power Race
-
ByteDance Initiates Largest B2B Structural Adjustment, This Time It's Truly Different
-
![]()
Let's Talk About Kingsoft Office's Mid-Year Outlook and the True Strength of Its AI-Powered Office Solutions
-
Despite 150 Million Users, Struggles Persist: AIShige Faces Tough Competition from Seedance and Kling in AI Video Monetization
-
![]()
Ensuring Safe Gear Shifting in the Automotive Industry: Transitioning from 'Product Oversight' to 'Full-Chain Governance'
-
![]()
Net Profit Soars to $133.7 Billion! Azure Revenue Tops $100 Billion, with AI Fueling Microsoft's Growth
-
![]()
Before 6G Hits the Market, the U.S. Forges a 'Rules Alliance': What Challenges Await Chinese IoT Enterprises?
-
![]()
Intelligent Driving's 'Little Blue Light' Faces Ban: Night Glare and Cut-in Risks Prompt Official Action





