
 12/11 2025
12/11 2025
 555
555
Behind this response lies a decade-long debate over technical routes within China's intelligent vehicle industry:
◎ Should autonomous driving models opt for VLA (Vision-Language-Action) or World Models?
◎ Is autonomous driving merely a 'software function,' or does it represent a comprehensive embodied intelligence system?
◎ In the L4 autonomous driving era, what will truly determine an automaker's fate: data exclusivity, software-hardware integration, or in-house chip development?
These questions delve into three critical issues:
◎ What constitutes the optimal technical route for autonomous driving?
◎ Why is Li Auto placing its bets on embodied intelligence?
◎ Can Li Auto's VLA truly bring about a structural enhancement in the driving experience?
These are hotly debated topics with no current consensus; practical results will be the ultimate arbiter of who is right or wrong.

Question 1: Why does Lang Xianpeng assert that 'VLA is the premier model for autonomous driving'?
Lang Xianpeng's response is as follows:
VLA stands out as the optimal solution due to its emergent cognitive abilities concerning the physical world and its capacity for deep integration with embodied intelligence systems, with data being the decisive factor.
We can understand this statement in light of the enhanced experience provided by the OTA 8.1 update. What occurs when the model deeply integrates with the system? The noticeable improvement in experience is a direct result of the VLA technical route.
The smoother stopping at red lights is achieved by upgrading visual perception from 1K to 2K and extending the recognition distance from 100 meters to 200 meters. This enables the vehicle to detect red lights earlier and the model to plan deceleration sooner, resulting in 'early, smooth, and natural' stops and eliminating the previous sense of lag. This exemplifies 'overall system capability': enhanced perception, more accurate models, and steadier behavior. The change lies not in the model itself but in its deeper integration with the system.
More accurate judgments at intersections are achieved by retraining the VLA model with approximately 6 million high-quality driving data clips. The outcome is more natural switching between main and auxiliary roads, no unnecessary lane change attempts, and no hesitation at intersections. This is attributed to the data closure constructed by millions of vehicles, supplemented by world model-generated data to fill in difficult samples. The world model acts as an 'exam setter' for VLA rather than an 'examinee.'
Why not a GPT-style world model? Why not an end-to-end approach?
Primarily because the physical world is too intricate for world models to directly make 'behavioral decisions.' VLA excels at 'understanding scenes → selecting actions' and can deeply collaborate with the perception, planning, and actuators of actual vehicles.
Large models across the industry generally pursue 'abstract world understanding,' whereas assisted driving necessitates 'precise physical behavior.' VLA directly connects vision, language, and actions, making it a model tailored for operating in the real world.
Li Auto's stance here is that 'VLA represents the shortest path to achieving L4.'
Question 2: Why will embodied intelligence shape the future of autonomous driving?
In the second segment, we interpret that embodied intelligence ultimately hinges on overall system capability, with future competition centered on 'who can transform a car into a robot.'
The 'four pillars' of embodied intelligence are perception (eyes), model (brain), chip (heart), and body (physical structure).
This framework carries significant technical implications: weak perception renders even the strongest model ineffective; a strong model with sluggish actuators still results in a poor experience; insufficient chip computing power renders all capabilities theoretical; and an unstable body (wire-controlled chassis) compromises safety.
As long as one component relies on suppliers, a true automotive robot cannot be built. Autonomous driving is not about competing on models but on system iteration speed, with data being the cornerstone for iteration speed. Vehicles generate massive amounts of driving data daily, enabling the VLA model to update its world understanding almost weekly.
Li Auto believes that VLA is the most versatile architecture for the 'next-generation robotic system.' Lang Xianpeng's confidence in declaring 'VLA as the premier autonomous driving model' stems from its versatility for the future.
◎ VLA has already demonstrated 'emergent physical cognition' in autonomous driving;
◎ The visual-language-action sequence of VLA is highly aligned with robotic control structures;
◎ VLA can be universally applied to automotive robots, AI glasses, and future home robots, with world model-generated data further training VLA to acquire a more versatile physical understanding.
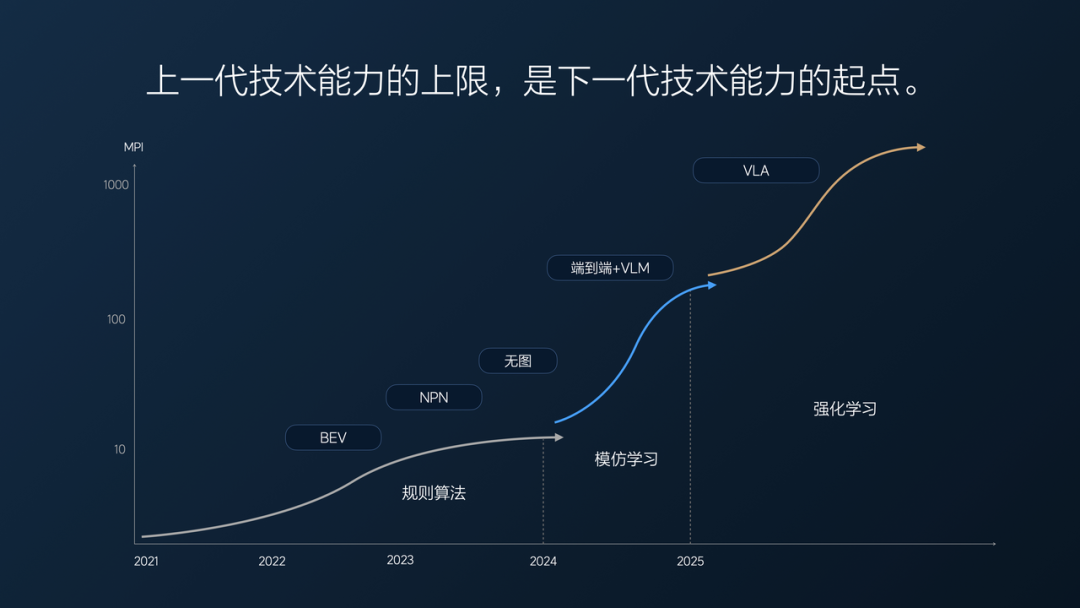
From Li Auto's perspective, world models are not the 'ultimate solution' for autonomous driving. The world model + end-to-end route represents one path, while the VLA + embodied intelligence system represents another. These two paths are expected to diverge significantly in the next 3-5 years.
Summary
The current discourse centers on what capabilities automotive robots should possess, how models should integrate with systems, and the debate over autonomous driving routes has escalated into a debate over embodied intelligence routes.
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?






