Li Auto Unveils MindVLA-o1: How Can One Model Truly Understand the 3D World?
 03/24 2026
03/24 2026
 491
491

By Xiong Yuge
Edited by Ziye
On March 17, at NVIDIA GTC 2026, Zhan Kun, Head of Foundation Models at Li Auto, delivered a speech unveiling the next-generation autonomous driving foundation model, MindVLA-o1.
On the 18th, Li Xiang, Chairman and CEO of Li Auto, released a dialogue with Zhan Kun on Bilibili, providing further insights into MindVLA-o1.
This is a native multimodal model that unifies vision, language, and action within a single architecture, adopting a multimodal MoE Transformer framework that integrates 3D visual encoding, world modeling, and reasoning capabilities.
Li Auto outlines MindVLA-o1's capabilities: enabling autonomous driving to see farther, think deeper, act more stably, evolve faster, and deploy more efficiently.
As a VLA (Vision-Language-Action Model), MindVLA-o1 offers immense imaginative potential.
"When vision, language, and action are unified into a single model, it is no longer just an autonomous driving model but is evolving into a general-purpose agent for the physical world. Based on the same VLA model, it can control not only vehicles but also extend to robots," Zhan Kun summarized at GTC.
Under the spotlight, Li Auto has taken another step toward becoming an embodied AI enterprise.
1. Perception, Thinking, and Action: The Three Keys to Physical AI
To understand MindVLA-o1, one must first grasp the issues with current mainstream autonomous driving technologies.
Initially, the logic behind intelligent driving technology was quite "simple." Engineers programmed clear rules for the driving system, with different rules for various road conditions, supplemented by high-definition maps that mapped every road in detail. However, rules are infinite, and there will always be the next "exception."
Around 2021, the first technological transformation in the autonomous driving industry began: Engineers directly fed large amounts of human driving data to the model, allowing it to learn on its own. End-to-end models take visual signals as input and output actual operations, directly learning human driving behavior.
This aligned with the industry's intuition—the more driving data, the better the performance, emphasizing the value of data.
From that year onward, Li Auto began developing its own assisted driving systems and shifted to end-to-end models in 2024. However, by 2025, Li Auto found that as training data reached larger scales, a ceiling gradually emerged.
Li Auto revealed that after accumulating 10 million Clips of training data, the company's R&D team waited five months, only to see the model's average intervention-free mileage increase by about 2x, far below expectations.
Li Xiang once bluntly compared end-to-end models to "monkeys driving"—their essence is imitation learning, where the model can learn driving actions but never truly understands the physical world.
Without causal reasoning, the model cannot understand irrational behaviors; without deep thinking, it cannot make complex decisions through pattern matching alone; and with insufficient safety awareness, it cannot make preventive judgments in complex scenarios.
"Today, whether embodied AI is working or training, it's all based on 2D videos. But this is not how humans truly operate in the physical world," Li Xiang explained. "Most model developers want to jump straight to adult-level tasks and train intensively. But they completely overlook the most critical training space and capabilities for children aged 0-6."
Humans build their understanding of the world during childhood, falling and getting back up in three-dimensional space, calibrating judgments of distance and speed through real perception and feedback. AI skips this stage and thus can never truly understand "driving."
This is the backdrop for the emergence of VLA models. Perception, thinking, and action—from the initial architectural design, these three modalities are placed in the same representation space for unified training.
In August 2025, Li Auto launched the world's first mass-produced VLA driving model with the delivery of the Li Auto i8. MindVLA-o1 is the latest advancement built upon this foundation.
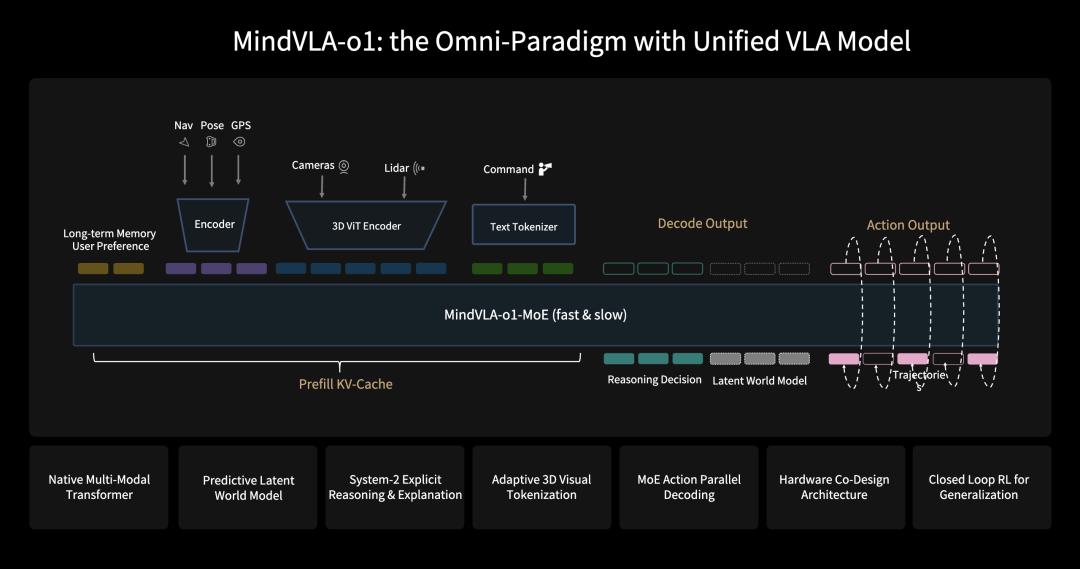
Core Design of MindVLA-o1, Source: GTC Presentation
This update redesigns the entire architecture based on MoE (Mixture of Experts), controlling the scale of activated parameters while expanding model capacity, and restructures it into three layers:
First is the perception layer.
Li Auto designed a self-supervised 3D ViT (3D Vision Transformer) visual encoder. During training, it simultaneously incorporates both visual and LiDAR (Light Detection and Ranging) data—the former providing rich semantic information, the latter offering accurate three-dimensional geometric structure, enabling the model to learn both geometry and semantics in the same representation space.
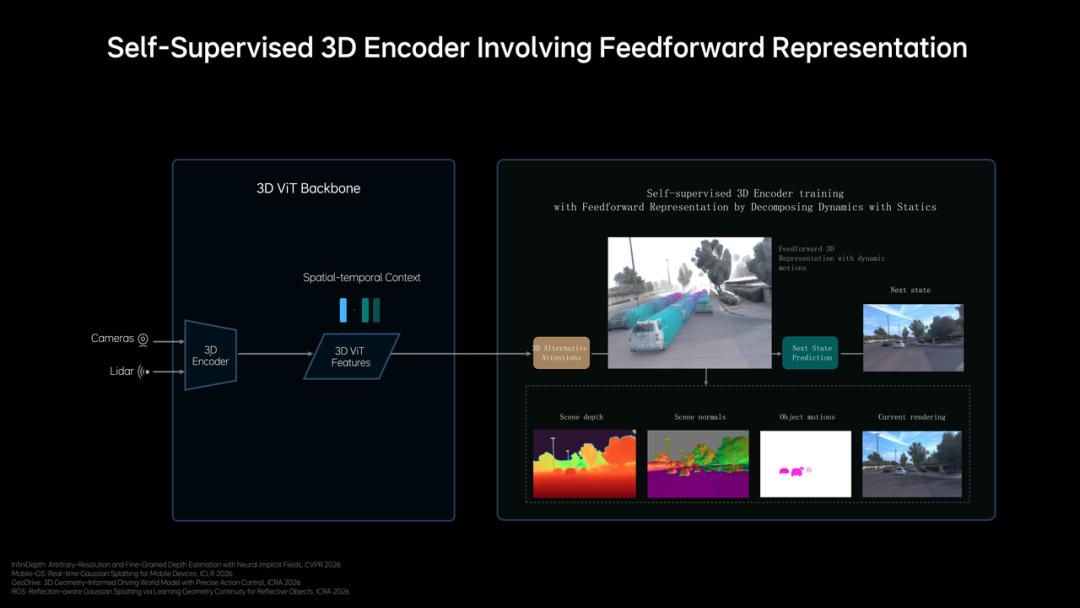
Architecture of the Self-Supervised 3D Visual Encoder, Source: GTC Presentation
To further enhance scene understanding capabilities, the training also introduces feedforward 3DGS (3D Gaussian Splatting) scene representation: The system decomposes the scene into static environments and dynamic objects, modeling them separately, and uses "next-state prediction" as a self-supervised signal to drive the model to simultaneously learn depth information, semantic structure, and object motion.
The resulting 3D ViT representation fuses spatial structure and temporal context information, providing a high-quality three-dimensional world representation for subsequent thinking and action layers.
For 3D perception, the training data mix has also been reconfigured, heavily incorporating 3D data and autonomous driving text-image data, actively reducing the proportion of literary and historical data, and adding future frame prediction generation and dense depth prediction tasks to specifically stimulate the model's understanding and reasoning capabilities in 3D space.
Next is the thinking layer.
The thinking layer consists of three interconnected mechanisms: explicit reasoning, future prediction, and fast-slow thinking coordination.
The language model introduces a System-2-style (slow thinking system) explicit reasoning mechanism—distinguished from intuitive rapid responses, the model can conduct deeper analysis and decision-making in complex scenarios.
Building on this, the model also embeds a Predictive Latent World Model, enabling autonomous driving not only to understand "what is happening now" but also to simulate "what will happen next."
Since directly generating future images is computationally expensive, Li Auto chooses to complete predictions in Latent Space: The system first encodes current visual inputs into a set of Latent Tokens as a compact representation of the scene, then uses the world model to deduce future states based on these tokens.
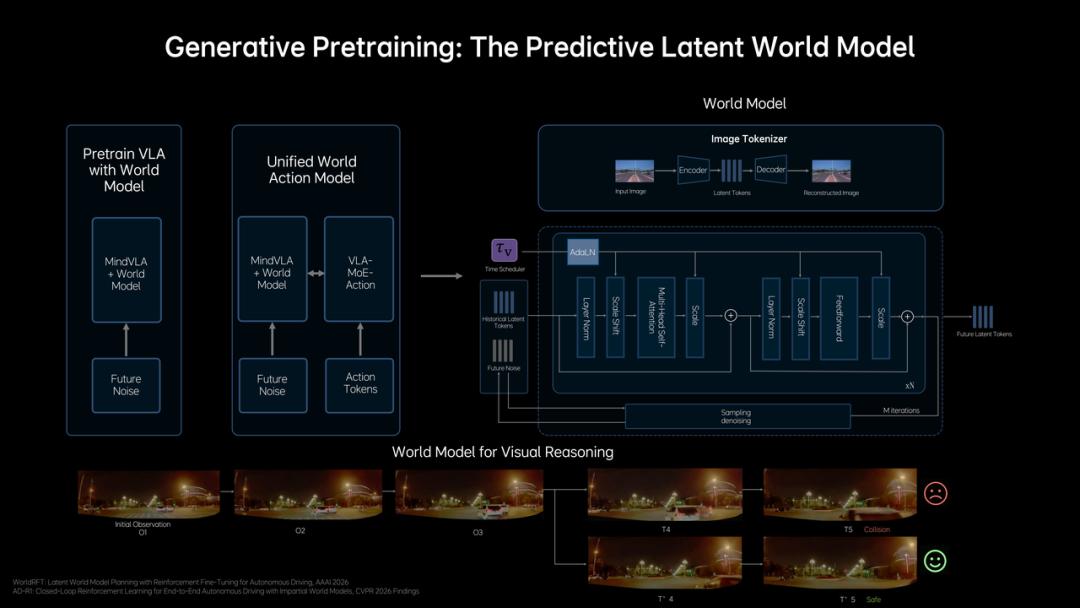
Architecture of the Predictive Latent World Model, Source: GTC Presentation
This world model undergoes three stages of training: In the first stage, it uses massive video data to learn to represent the future in latent space; in the second stage, it strengthens future deduction capabilities within the MindVLA-o1 framework; in the third stage, it jointly optimizes the world model, multimodal reasoning, and driving behavior under the same objective.
The fast-slow thinking mechanism is also integrated into the same model: In simple scenarios, the model directly outputs Action Tokens without going through a reasoning chain; in complex scenarios, it first passes through a fixed, concise CoT (Chain of Thought) template before outputting actions.
In terms of efficiency design, speculative reasoning with a small vocabulary is used to significantly accelerate the reasoning chain; Action Tokens are output simultaneously in a single Transformer using bidirectional attention, while CoT reasoning is decoded word by word under causal attention, with both coexisting in the same model.
Finally is the action layer.
The action layer adopts a three-tier progressive design: an Action Expert module generates trajectories, Parallel Decoding ensures output speed, and Discrete Diffusion Refinement refines quality.
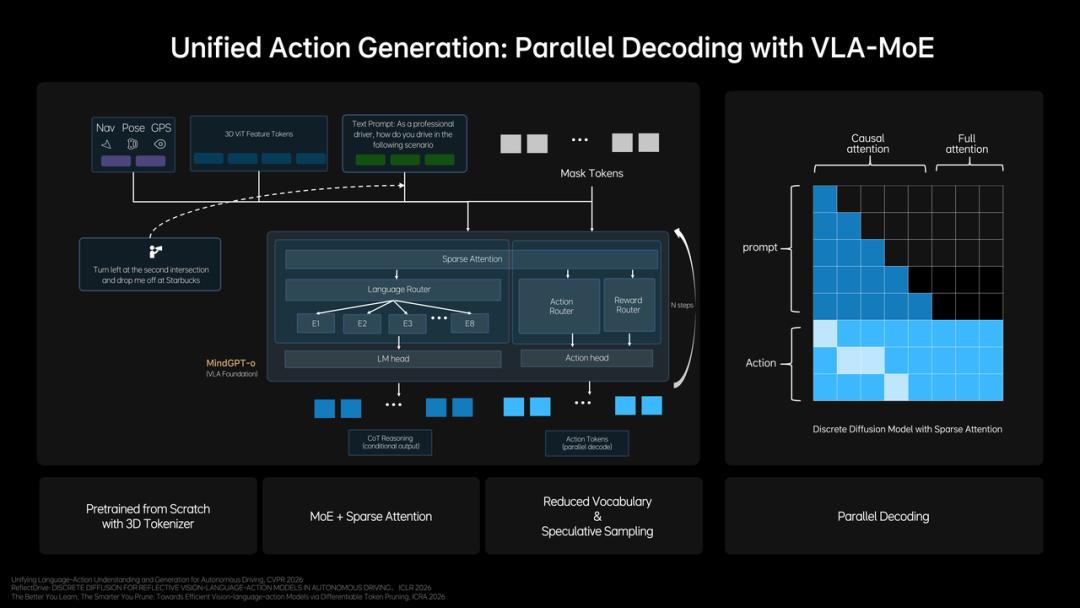
Unified Behavior Generation Architecture, Source: GTC Presentation
Specifically, the Action Expert extracts key information from 3D scene features, navigation goals, and driving instructions, combining multimodal reasoning to generate initial driving trajectories. After trajectory generation, Parallel Decoding outputs all trajectory points simultaneously rather than sequentially, offering significant efficiency advantages in long-sequence trajectory prediction scenarios.
Discrete Diffusion Refinement then performs multiple iterative optimizations on the parallel-generated trajectories, similar to progressive denoising, ultimately making the trajectories spatially continuous, temporally stable, and compliant with vehicle dynamics constraints—the entire Diffusion process is compressed to 2-3 steps using an ODE (Ordinary Differential Equation) sampler.
The Diffusion model also simultaneously predicts trajectories for the ego vehicle and surrounding vehicles and pedestrians, enhancing negotiation capabilities in complex traffic scenarios through joint modeling. For long-tail scenarios with residual deviations, RLHF (Reinforcement Learning from Human Feedback) is used for correction: A large dataset of intervention data is filtered to establish a human preference dataset, fine-tuning the model's sampling process to gradually align with human driving behavior, with the safety threshold continuously improving as preference data accumulates.
From seeing to thinking to doing, this is a reconstruction that begins at the perception layer and ultimately lands in execution at the action layer, forming a complete closed loop. However, for practical applications, this is far from the endpoint.
2. From Academia to Deployment: How Li Auto Makes It Happen
Getting a solution to work in a lab and deploying it in a mass-produced vehicle are two entirely different matters.
The first challenge MindVLA-o1 faces is the inevitable computational problem.
The model's 3D ViT encoder is far more complex than mainstream "2D solutions," demanding higher computational power on the edge.

Li Xiang and Zhan Kun Discussing the Mach 100 Chip, Source: GTC Presentation
Li Auto's solution is a self-developed chip, the "Mach 100."
It is China's first automotive-grade 5-nanometer chip adopting a dataflow-native architecture, naturally suited for AI inference computing. On standard large-scale matrix multiplication tasks, Mach 100's performance is about 3x higher than the previous generation; when two Mach 100 chips actually run the VLA model, their effective computational power is 5-6x that of NVIDIA's Thor-U.
On Mach 100, Li Auto has successfully deployed a VLA model with 6x the parameter scale and 10x the computational volume of the previous generation, achieving higher frame rates and faster inference speeds, with an overall latency of just 200-300 milliseconds from sensor input to vehicle execution output.
Additionally, Mach 100 eliminates the previous-generation XCU controller, integrating and replacing it with the XingHuan OS, significantly reducing the single-unit BOM cost compared to outsourced solutions.
After solving the computational problem, training cost issues became the second "roadblock."
Large-scale pre-training of the 3D ViT and repeated iterations of reinforcement learning in simulated environments are required. Traditional gradual optimization-based reconstruction is too slow to support large-scale parallel training.
To address this, Li Auto collaborated with NVIDIA to build a 3D Gaussian Splatting rendering engine and a distributed training framework, nearly doubling rendering speed and reducing overall training costs by about 75%.
During this process, Li Auto's world simulator was also upgraded to feedforward scene reconstruction, capable of instantly generating large-scale high-fidelity driving scenes. The simulated environment can also be expanded, edited, and used to generate new scenes, not just replicating the real world.
The final challenge lies in vehicle-end deployment.
High-precision models cannot run on the vehicle end, while those that can often lack sufficient precision. To match the model to the vehicle end, the traditional approach involves extensive experimentation and repeated adjustments to the model structure, which typically takes months.
To achieve greater efficiency, Li Auto, on one hand, further improves sparsity rates through Sparse Attention mechanisms in the model to ensure real-time inference efficiency on the edge.
On the other hand, it proposes a hardware-software co-design law:
Combining the Roofline model to characterize hardware computational capabilities and memory bandwidth limitations, a unified analytical framework is established between model performance and hardware constraints, searching for the optimal balance between accuracy and inference latency among approximately 2,000 architectural configurations.
The final conclusion from experiments is quite "counterintuitive": Under computational constraints, "wider and shallower" models are more efficient than "deeper" ones.
With this achievement, Li Auto has shortened architectural exploration time from months to days.
Having overcome these three major challenges, the changes brought by the VLA model are visible to the naked eye.
For example, in January of this year, Li Auto's OTA 8.2 vehicle system update incorporated millisecond-level steering wheel and throttle action data into the world model, enabling the VLA to conduct behavioral reinforcement learning—longitudinal and lateral control no longer mechanically follow preset parameters but are dynamically output based on a comprehensive understanding of the current scene.
In seven typical urban scenarios, such as mixed pedestrian-vehicle roads, narrow road passages, and oncoming traffic on narrow roads, its performance stands out: For instance, on mixed pedestrian-vehicle roads, the vehicle predicts the movement intentions of pedestrians and non-motorized vehicles in real time, planning lateral avoidance and longitudinal speed adjustments simultaneously; when navigating narrow roads, acceleration and deceleration are more nuanced, with reasonable avoidance of both dynamic and static obstacles; during oncoming traffic on narrow roads, vehicle speed and lateral position adjust automatically, with smooth longitudinal deceleration without jerks.
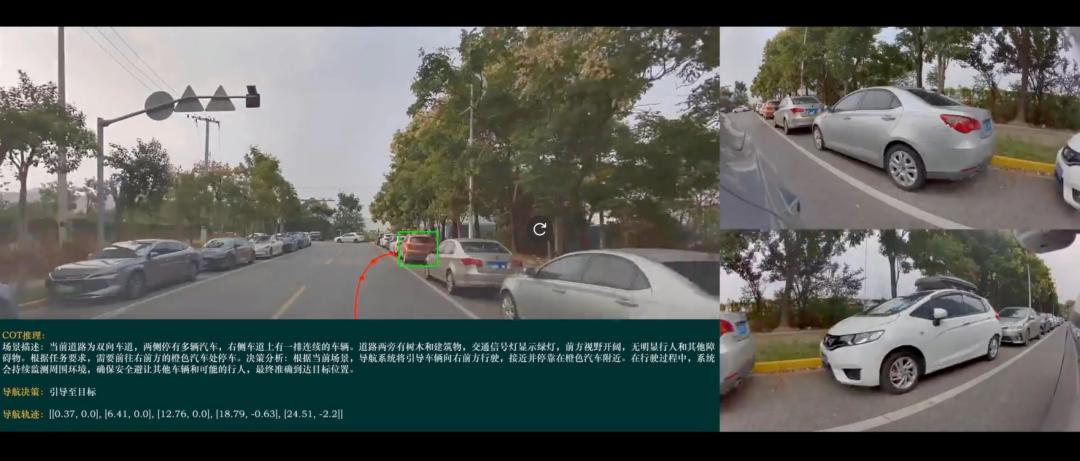
The MindVLA-o1 model understands environmental semantics through self-developed language instruction comprehension, Source: GTC Presentation
In general scenarios, the VLA model also offers more variations in capabilities. For example, language instructions can directly alter driving behavior—phrases like "drive faster, I'm in a hurry" can now be understood and executed by the model.
According to Li Auto, by the end of 2025, the VLA will achieve an 80% monthly utilization rate and 12.254 million VLA command usages. The top three most frequently used commands by users are lane changing left and right, going straight, and accelerating/decelerating.
Ultimately, the combination of cost reduction, acceleration, and computational power has enabled the MindVLA-o1 model to meet mass production conditions, rather than remaining on paper.
3. Conclusion
At GTC, a demonstration clip of MindVLA-o1 was unrelated to autonomous driving but instead showed it controlling a robotic arm to gently pick up a bottle of Yakult and pour it into a cup on the table.

Three different demonstration scenarios of the MindVLA-o1 model, image source: GTC presentation
Why can a model designed for autonomous driving operate a robotic arm?
Li Auto explains that the same VLA model can drive physical agents of different forms, sharing the same model and data system for both autonomous driving and robotic control. For the model, different actuators essentially represent the same type of problem—understanding the environment, reasoning about intent, and generating action sequences.
As of November 2025, Li Auto has accumulated nearly 1.5 billion kilometers of driving data.
If we delve deeper, we find this logic: Li Auto is using large-scale driving data for pre-training general-purpose physical AI.
In just a few years, when people examine Li Auto again, it is clear that the company has already come a long way on the path to embodied AI.
In 2025, Li Auto invested 11.3 billion yuan in R&D, with AI-related spending accounting for 50%. In January 2026, Li Auto restructured its R&D team into four major systems based on the logic of "building silicon-based beings"—organs, brain, software, and hardware. In Q2 2026, the Mach 100 will enter mass production and be integrated into vehicles.
"Artificial intelligence is about creating beings. Agents are digital beings, while embodied beings are physical ones—just silicon-based instead of carbon-based," said Li Xiang. He added that L4 autonomous vehicles will be the most important silicon-based beings in our lives.
He stated that the competition among mid-to-high-end vehicles in the next 3 to 5 years will essentially be a competition in embodied intelligence. In the past, the evolution from feature phones to smartphones was driven by changes in chips and operating systems. In the era of embodied intelligence, the corresponding changes involve the Co-Design of chips and models.
This understanding has driven Li Auto to gradually consolidate its capabilities at the foundational level, from developing its own chips in 2022 to building foundational models in 2023.
Today, Li Auto has established a complete system spanning computational power, perception, and decision-making, shifting its positioning from a "vehicle manufacturing company" to a "physical AI company with vehicles as the carrier." Cars are no longer just products but interfaces to the real world for large-scale deployment and continuous training.
Therefore, the significance of MindVLA-o1 extends far beyond performance improvements. It marks a paradigm shift: models are beginning to truly enter the three-dimensional world, transitioning from passive responses to inputs to active modeling and reasoning about the environment.
The boundaries of autonomous driving are blurring. Beyond these lines, Li Auto's journey into physical AI may have only just begun.
(The header image of this article is sourced from the official Li Auto website.)
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
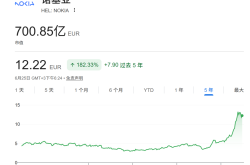
Why Is Nokia Making a Comeback in the AI Era?