Is the logic of occupancy networks for autonomous driving the same when processing the sky and the road surface?
 03/25 2026
03/25 2026
 589
589
In the field of autonomous driving, accurately perceiving and understanding the surrounding 3D environment has always been the core of the technology. Early perception solutions mainly relied on 2D object detection, identifying vehicles, pedestrians, and traffic signs through image recognition and drawing rectangular boxes around them.
This box-based recognition method struggles when faced with complex and irregular objects. With the development of technology, bird's-eye view technology converts images captured by multiple cameras into a top-down coordinate system, greatly improving the efficiency of path planning. However, it still ignores information in the height dimension. The emergence of occupancy networks has completely changed this situation.
What are the advantages of occupancy networks?
Occupancy networks no longer just focus on "what object this is" on the road surface. Instead, they divide 3D space into countless tiny blocks, or voxels, to predict whether each spatial unit is occupied. This shift from "object-first" to "geometry-first" enables autonomous driving systems to recognize irregular objects that do not exist in traditional model libraries, effectively filling semantic gaps in perception.
The core advantage of occupancy networks lies in their ability to provide a dense, highly informative environmental description. Through this approach, vehicles can not only see a car ahead but also perceive subtle undulations on the road surface, branches extending into the road, or tilted lampposts. This comprehensive perception capability directly enhances the safety of autonomous driving systems in complex urban scenes and unstructured roads.
During the construction of occupancy networks, adopting differentiated processing methods for scene elements with different properties is key to improving accuracy. Especially for the road surface and the sky, two types of scenes with vastly different characteristics, they represent the "supporting surface" and the "infinite boundary" of the physical world, respectively, and their processing logic fundamentally differs at the algorithmic level.
Occupancy networks typically use a powerful backbone network to extract multi-view image features and then project these 2D features into 3D voxel space using an attention mechanism. During this process, the algorithm must distinguish which pixels correspond to solid physical obstacles and which pixels merely exist as background.
As the foundation for vehicle movement, the reconstruction accuracy of the road surface's geometric features directly affects obstacle avoidance and suspension control. In contrast, the sky is a region without depth information and plays more of a role in "geometric calibration" and "negative constraints" within occupancy networks. Differentiated processing of these two scenes is not only necessary for improving computational efficiency but also an inevitable choice for achieving highly reliable perception.
How do occupancy networks process the road surface?
The road surface is regarded as the most fundamental static scene in occupancy networks. Although visually the road surface appears relatively uniform in texture, its processing in 3D space is far more complex than it seems. The road surface is not just a collection of "occupied" voxels; it also carries critical geometric information such as slope, bumps, and curbs.
To effectively distinguish the road surface, occupancy networks must first address the issue of high-precision height estimation. Traditional visual perception algorithms suffer from severe depth errors when processing distant road surfaces due to perspective effects and image resolution limitations. By introducing elevation reconstruction technology, occupancy networks can depict the unevenness of the road surface, which is crucial for vehicle speed planning in complex terrain.
When processing the road surface, the algorithm uses "ground plane priors" as constraints. This means the model assumes the road surface is a roughly continuous surface and then fuses multiple frames of images to eliminate noise from single-frame predictions.
For undulations on unstructured roads, some advanced models employ slope-aware adaptive feature extraction modules. These modules can dynamically adjust feature weights based on input images, maintaining stable road surface tracking capabilities on steep slopes or sharp turns.
Unlike processing obstacles, the voxel filling logic for the road surface is generally performed layer by layer. The model first generates a coarse ground grid and then refines it with sub-voxel-level detail corrections based on local image features. This coarse-to-fine process ensures the perception system's accurate judgment of the driving path.
Data-level processing also reflects the uniqueness of the road surface. When generating ground truth labels for training occupancy networks, directly using LiDAR point clouds encounters sparsity issues. Due to the small angle between the laser beam and the ground, distant point clouds barely cover the ground.
Therefore, a specialized label generation pipeline has been proposed, which fills gaps by fusing multiple frames of sequences and using algorithms like Poisson reconstruction to generate a continuous, smooth, and semantically accurate road surface voxel model.
Additionally, to address recognition errors caused by road surface reflections or shadows, occupancy networks combine semantic segmentation information to cross-verify pixel points marked as "drivable areas" with depth values in space, ensuring that occupied road surface voxels are not confused with floating objects in the air.
Occupancy networks from automakers like Tesla further enhance road surface performance by predicting a "signed distance field." This method not only determines whether the road surface is occupied but also calculates the precise distance from any point in space to the road surface. This improved accuracy allows vehicles to identify tiny bumps on the road surface. Such refinement (fine-grained) modeling of the road surface greatly enhances the adaptability of autonomous driving systems to complex road conditions.
How do occupancy networks process the sky?
Compared to the "geometry-heavy" nature of road surface processing, the logic for processing the sky in occupancy networks leans more toward "semantics-heavy" and "negative feedback." The sky is essentially an infinite background, and active sensors like LiDAR cannot obtain reflection signals in the sky region. Therefore, the sky usually appears as "lost" or "infinitely far" in the sensor's raw data.
If the algorithm does not specially process the sky, when projecting image features into 3D space, pixel features in the sky region may "drift" along the beam direction due to a lack of depth constraints, erroneously filling nearby voxels and creating a "depth bleeding" phenomenon.
To effectively distinguish the sky, occupancy networks introduce "sky grounding" technology. This technology uses large models or pre-trained semantic networks to identify sky regions in images and applies them as boundary constraints for the perception system.
During the projection process, voxels belonging to the sky region are forcibly marked as "free" or "unobserved," preventing the system from generating false obstacles in mid-air. This method essentially treats the sky as a filter, using the certainty of the visual background to reversely optimize the geometric structure of 3D space. This is the opposite of the logic for road surface processing, which constantly seeks "support points." Sky processing continuously performs "spatial exclusion."
The sky also plays a role in auxiliary calibration for environmental understanding. By analyzing the distribution of clouds in the sky, light brightness, and the position of the horizon, the algorithm can assist in correcting the camera's extrinsic parameters. In autonomous driving for unmanned boats or extreme terrains, precise detection of the sky using color space models (such as brightness and saturation distributions) can help the system more quickly identify the boundaries between land and water.
During the training phase of occupancy networks, to address the lack of sky labels, researchers introduce a "visibility mask" mechanism. This mechanism can distinguish whether a voxel is truly unoccupied or simply unobservable due to occlusion. Since the sky is never "occupied," it provides a natural endpoint reference in visibility reasoning.
Novel representation methods like Tri-Perspective View (TPV) handle the sky more effectively. TPV decomposes space into three mutually perpendicular planes: top view, side view, and front view. The semantic features of the sky can be fully expressed in the side and front views, without completely compressing height information like traditional Bird's-Eye View (BEV).
This multidimensional feature fusion ensures that when pixels appear at the top of the image and exhibit the sky's unique color distribution, their corresponding 3D voxels should have an extremely low occupancy probability. This semantic-driven geometric reasoning is key to enabling occupancy networks to handle various complex weather and lighting conditions.
Unified Modeling and Technical Synergy in Heterogeneous Scenes
The power of occupancy networks lies in their ability to simultaneously process the road surface, sky, and various complex obstacles using entirely different logics within the same framework. This unity is achieved through complex feature enhancement and fusion mechanisms.
In autonomous driving algorithms, the introduction of Tri-Perspective View (TPV) and Transformer structures enables the model to adaptively apply different processing strategies based on the dynamic changes in spatial positions. For example, when the system identifies a voxel located below the vehicle with semantics close to "road surface," it focuses more on the smoothness of the geometric surface. When a voxel is located above the field of view and exhibits sky characteristics, the system applies stronger negative constraints to clear that region.
To achieve such fine-grained scene differentiation with limited computational power, a "distance-aware" perception paradigm has been proposed. In the "safety core zone" near the vehicle, the system allocates higher resolution and more voxel units to precisely reconstruct every detail of the road surface. In distant regions, it adopts a coarser voxel division, relying mainly on semantic information to judge the boundaries between the sky and background.
This resource allocation strategy not only mimics the "near-fine, far-coarse" characteristic of human vision but also significantly enhances the system's real-time processing capabilities.
Meanwhile, to address the sparsity and noise issues in sensor data, self-supervised learning techniques have begun to emerge. By using rendering technologies like Neural Radiance Fields (NeRF), models can reproject the predicted 3D occupancy map back into 2D images and compare them with the original video frames, enabling autonomous learning to distinguish complex road surface textures from ever-changing sky backgrounds without manual annotations.
-- END --
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
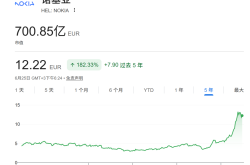
Why Is Nokia Making a Comeback in the AI Era?