Mach 100 Chip-Powered, First Integrated with All-New L9, Li Auto Unveils Next-Gen Autonomous Driving Architecture
 03/25 2026
03/25 2026
 464
464

Architecture upgrades have become a key focus in the autonomous driving sector this year.
Since the beginning of the year, NIO has rolled out World Model 2.0, XPENG has introduced its second-generation VLA, and Momenta has launched the Momenta R7 reinforcement learning world model. At the recently held NVIDIA GTC 2026 conference, Li Auto unveiled its next-generation autonomous driving foundation model, MindVLA-o1.
Zhan Kun, head of Li Auto's foundation models, provided a detailed introduction to the new architecture during his speech. Subsequently, Li Auto founder Li Xiang engaged in a lively dialogue with Zhan Kun.
This provided us with greater insight into the development and thinking behind Li Auto's next-generation autonomous driving architecture.
01
Autonomous Driving Architecture Upgraded Again with 3D ViT Introduction
Zhan Kun explained that autonomous driving architectures only become true AI systems after transitioning to end-to-end systems. However, early end-to-end systems represented low-order intelligence, similar to that of insects, essentially learning to perform tasks through imitation.
Therefore, to achieve strong performance in autonomous driving systems, vast amounts of data must be fed for imitative learning. However, the complexity of the real world makes it impossible to exhaustively cover all long-tail scenarios through sheer data volume.
This explains why current first-tier advanced driver-assistance systems (ADAS) perform well in regular urban conditions but still expose various issues in long-tail scenarios, falling far short of human drivers.
So, how can autonomous driving systems evolve from imitative learning to truly understanding traffic scenarios?
Building upon end-to-end foundations, various technical architectures have begun to diverge. Zhan Kun noted that adding language semantic reasoning to end-to-end systems creates VLA, while incorporating future image imagination results in world models.
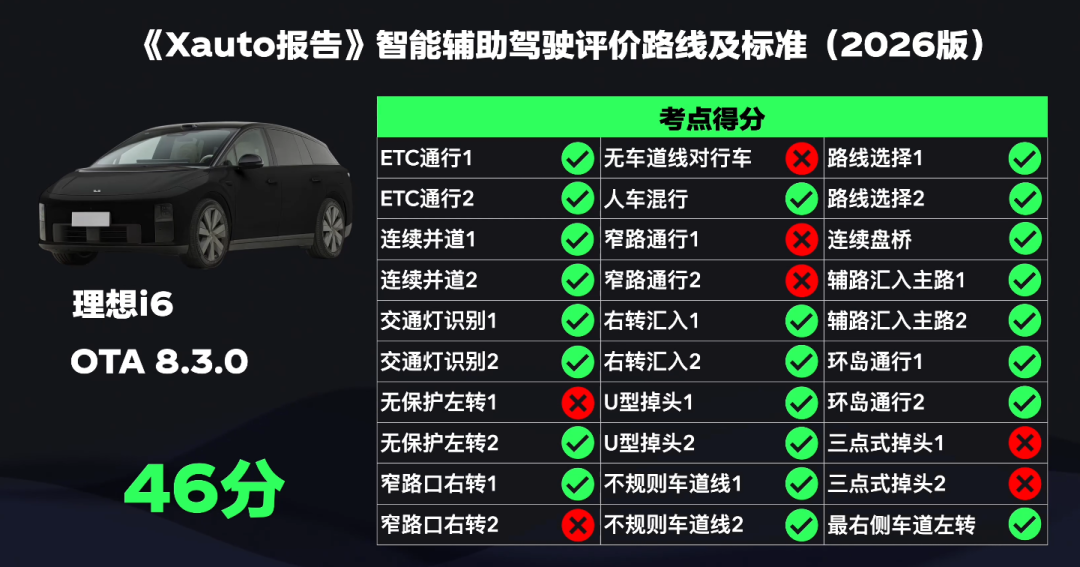
At last year's NVIDIA GTC conference, Li Auto introduced its VLA architecture. After a year of refinement, significant progress has been made in Li Auto's intelligent driving capabilities, but a bottleneck was soon reached. Among the 30 evaluation points on the Xauto Intelligent Driving Leaderboard, Li Auto still failed to pass challenging scenarios such as narrow road navigation and three-point turns.
Faced with this reality, Li Xiang posed a thought-provoking question.
Human driving doesn't seem particularly difficult—most ordinary people can drive smoothly and quickly—yet despite the world's top companies investing hundreds of billions, progress in autonomous driving remains slow. Where does the problem lie?
After reflection, Li Auto concluded that they had been teaching AI to perform adult tasks without first letting it experience childhood.
From ages 0 to 6, humans learn to walk, throw, and catch balls. These seemingly simple actions actually help children build an understanding of three-dimensional physical space.
Humans can accurately measure distances and drive steadily because this "3D pre-training" is completed before age 6.
Today, all end-to-end systems essentially "learn to drive by watching 2D videos"—akin to someone watching 100,000 hours of dashcam footage before hitting the road.
Previously industry-acclaimed technologies like BEV and OCC have shortcomings. BEV flattens the world from a bird's-eye view, losing height information, while OCC, though 3D, lacks semantic context.
Li Auto believes that what physical AI lacks is not larger models or more data but a visual foundation capable of truly understanding the 3D world.
To address this, Li Auto introduced native 3D ViT, or 3D visual encoders.
ViT (Vision Transformer) is a Transformer-based backbone network with global attention capabilities, enabling superior extraction of global contextual features—making it mainstream in the large model era.
Li Auto explains that 3D ViT enables models to work in true 3D space from the outset, using high-resolution multi-view vision as its core to directly achieve unified understanding of 3D spatial geometry and semantics during encoding, including spatial structure, positional relationships, and semantic information—all in one pass.
Thus, the model doesn't just "see" images but "understands" the world.
Under this framework, LiDAR's role changes—it's no longer the core of perception but rather functions as a high-precision ruler, providing geometric calibration and near-field spatial constraints for vision.
Li Xiang stated that under unified modeling, 3D ViT can stably perceive and reason about spaces beyond 500 meters.
It's worth noting that Huawei recently upgraded several of its models to higher-precision 896-line LiDAR, likely driven by similar thinking—to paint a more precise physical world for autonomous driving models.
Given 3D ViT's numerous advantages, why is Li Auto introducing it to its autonomous driving architecture only now? When asked this question,
Zhan Kun explained that 3D ViT places extremely high demands on onboard inference computing power. Li Auto's self-developed Mach 100 chip, with 1,280 TOPS of computing power per chip, provides the foundation for deploying 3D ViT.
02
Five Core Technical Pillars: A Deep Dive into the Latest Architecture
Having explored the core changes in Li Auto's new-generation autonomous driving architecture, let's examine its five key technical pillars.
Li Auto's next-generation autonomous driving architecture is named MindVLA-o1.
Centered around a native multimodal MoE Transformer, this architecture features five core technical pillars: 3D spatial understanding, multimodal reasoning, unified behavior generation, closed-loop reinforcement learning, and hardware-software co-design.
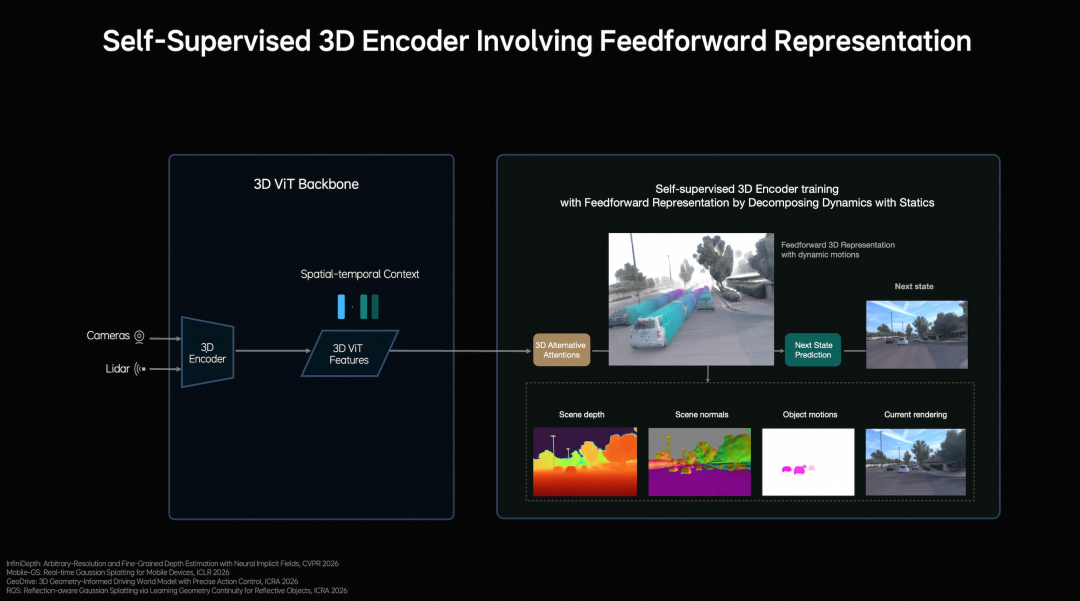
At the perception level, Li Auto employs a vision-centric 3D ViT Encoder, using LiDAR point clouds as 3D geometric cues to guide the model in understanding real spatial structures, enabling simultaneous semantic understanding and 3D perception.
It also introduces Feedforward 3D Representation, decomposing scenes into static environments and dynamic objects for separate modeling. By using next-frame prediction as a self-supervised signal, the model simultaneously learns depth information, semantic structure, and object motion, ultimately forming high-quality 3D representations that integrate spatial structure and temporal context.
3D spatial understanding enables the model to "see" farther.
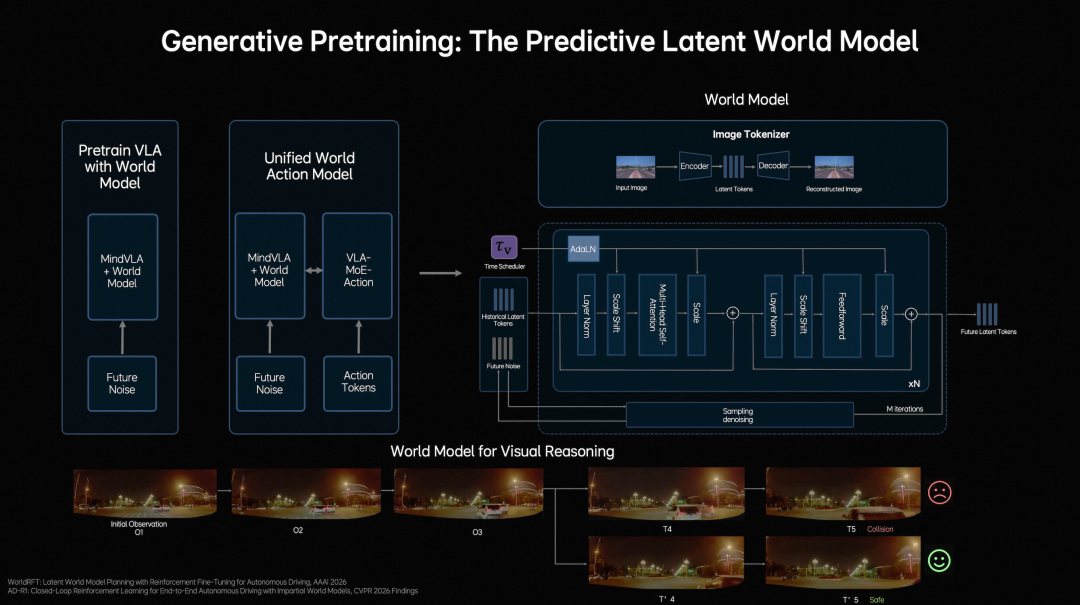
At the reasoning level, autonomous driving requires understanding the current environment while predicting scene evolution over the next few seconds.
Building on language models for semantic understanding, common-sense knowledge, and interaction capabilities, Li Auto introduces a predictive latent world model to efficiently simulate the future in latent space.
Training occurs in three stages:
First, pre-train Latent World Tokens with massive video data to build future representations;
Second, continuously evolve world model inferences within MindVLA-o1 to develop future reasoning capabilities in latent space;
Third, jointly train and align the world model, multimodal reasoning, and driving behaviors.
This enables the model not only to understand current scenarios and make logical judgments but also to "imagine" future scenes in latent space, visualizing driving decisions.
Li Auto defines this capability as multimodal reasoning. Possessing multimodal reasoning allows the model to "think" deeper.
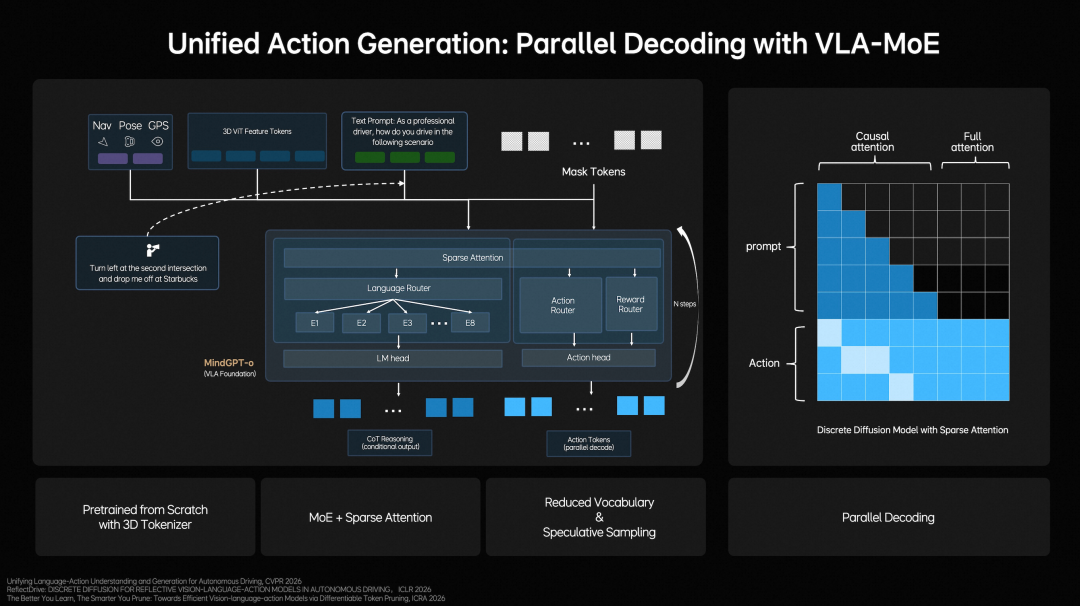
At the behavioral level, Li Auto constructs a Unified Action Generation mechanism.
First, MindVLA-o1 employs a VLA-MoE architecture and introduces a dedicated Action Expert to extract information from multidimensional inputs such as 3D scene features, navigation goals, and driving instructions, combining multimodal reasoning to generate high-precision driving trajectories.
Second, to meet real-time requirements, the system adopts Parallel Decoding to simultaneously generate all trajectory points, significantly boosting efficiency.
Finally, it employs Discrete Diffusion for multi-round iterative optimization, akin to progressive denoising, ensuring trajectory spatial continuity, temporal stability, and compliance with vehicle dynamic constraints.
The Unified Action Generation mechanism enables the model to "act" more stably.
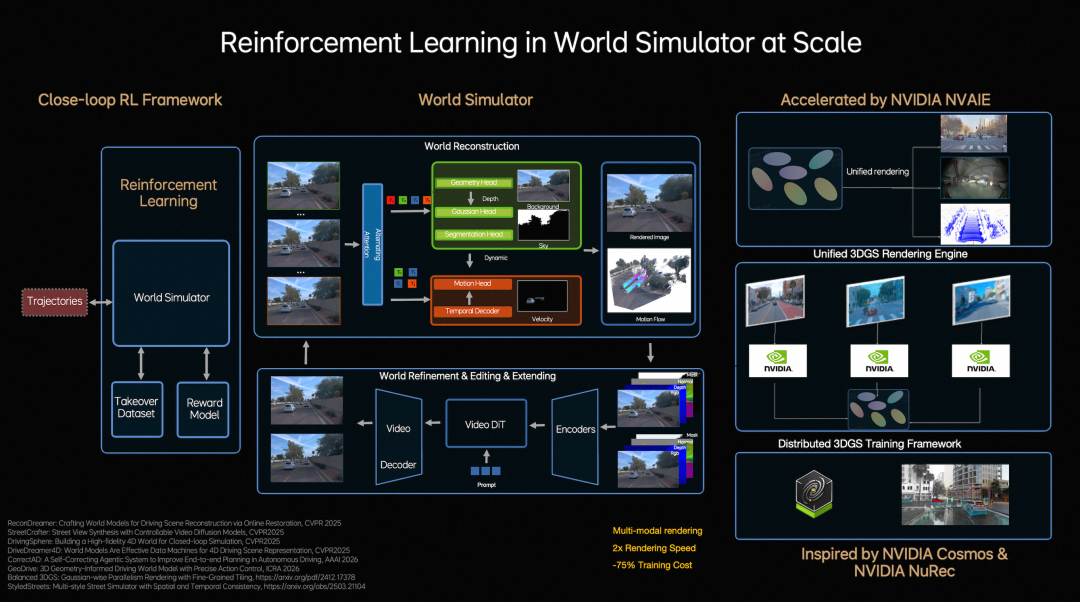
At the model iteration level, Li Auto constructs a closed-loop reinforcement learning framework, enabling the model to learn not only from real-world data but also to continuously explore and optimize strategies within a world simulator.
To achieve this, Li Auto upgrades traditional step-by-step optimization reconstruction to Feed-forward scene reconstruction, allowing the system to instantaneously generate large-scale, high-fidelity driving scenarios for massive parallel training.
Simultaneously, combined with generative models, the simulated environment can be expanded, edited, and used to generate entirely new scenarios.
To support large-scale simulation and training, Li Auto developed a unified 3D Gaussian Splatting rendering engine and distributed training framework, nearly doubling rendering speed and reducing overall training costs by approximately 75%, achieving low-cost, high-efficiency closed-loop reinforcement learning.
Within the closed-loop reinforcement learning framework, the model evolves faster.
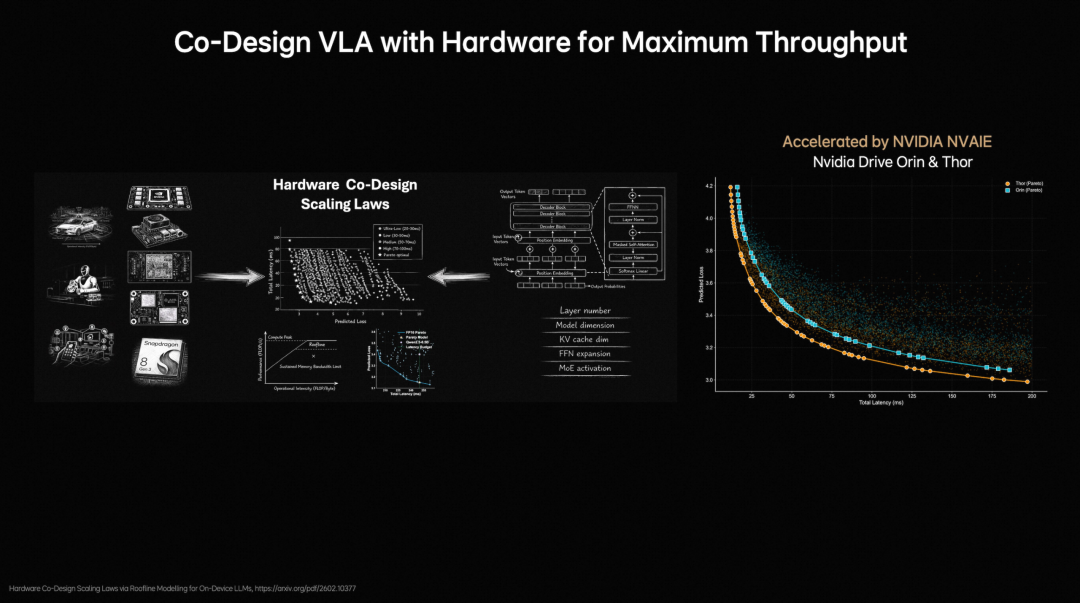
To address the time-consuming deployment and frequent debugging of traditional on-device large models, Li Auto proposes hardware-software co-design principles for on-device large models. By modeling model structures and validation losses, combined with the Roofline model to characterize hardware computing capabilities and memory bandwidth limitations, a unified analytical framework is established between model performance and hardware constraints.
Li Auto's foundation model team evaluated nearly 2,000 model architecture configurations, completing validation on NVIDIA Orin and Thor platforms. They identified the Pareto Front between model accuracy and inference latency, reducing architecture exploration time from months to days and significantly boosting the design and deployment efficiency of on-device VLA models.
Under the hardware-software co-design principles, model deployment becomes more efficient.
03
Conclusion
According to Li Auto, mass production of the new-generation autonomous driving architecture is expected in Q2 this year, debuting in the all-new Li L9.
Li Xiang previously stated that a single Mach 100 chip offers three times the effective computing power of NVIDIA's Thor U. The top-tier version of the new Li L9, the L9 Livis, will be equipped with two Mach 100 chips.
Another notable development is that mainstream autonomous driving players are converging toward world models. As seen through Li Auto's introduction of 3D ViT, the company is also striving to enable true 3D world understanding in its models.
Furthermore, the industry consensus is that autonomous driving represents just one critical application of physical AI. Explorations in this field serve not only the automotive sector but also extend to robotics and various physical systems.
Therefore, developing a universal physical AI foundation model is currently a key research and development focus for automakers and intelligent driving companies.

-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?