NVIDIA's TMD Distillation Framework: Pioneering Real-Time Video Generation with Optimal Speed-Quality Balance!
 01/19 2026
01/19 2026
 616
616
Insight: The Dawn of AI-Generated Content Era 
Key Highlights
- Innovative Video Diffusion Distillation: Transfer Matching Distillation (TMD) streamlines lengthy denoising processes into compact, efficient probabilistic transitions.
- Decoupled Diffusion Backbone: The teacher model is split into a semantic backbone and a recurrent flow head, enabling hierarchical distillation with flexible internal flow refinement.
- Two-Stage Training:
- Transfer Matching Adaptation: Transforms the flow head into a conditional flow mapping.
- Distribution Matching Distillation: Conducts flow head rollout at each transition step for precise distribution alignment.
- Empirical Validation: TMD excels in distilling Wan2.1 1.3B and 14B T2V models, achieving unparalleled speed-quality trade-offs in few-step video generation.
 Figure 1. Generation examples from TMD. Using our TMD method (derived from Wan2.1 14B T2V), four-frame 5s 480p videos are generated with two text prompts, showcasing comparative effects with varying numbers of function evaluations (NFE).
Figure 1. Generation examples from TMD. Using our TMD method (derived from Wan2.1 14B T2V), four-frame 5s 480p videos are generated with two text prompts, showcasing comparative effects with varying numbers of function evaluations (NFE). 

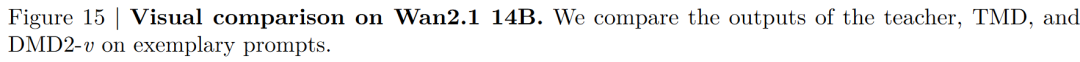


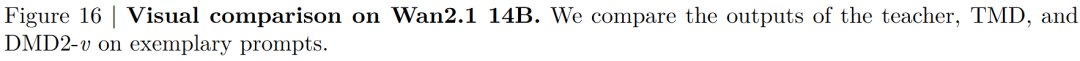


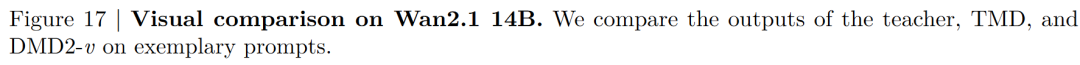


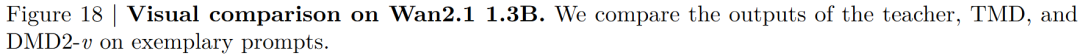


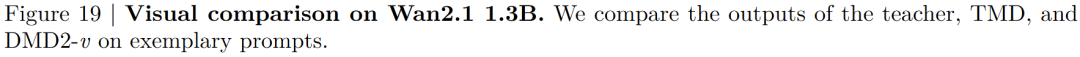


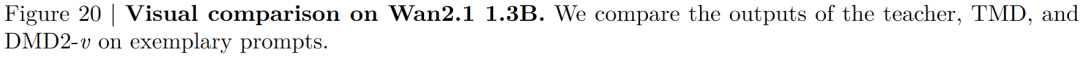
Summary Overview
Challenges Addressed
Large video diffusion and flow models, while successful in generating high-quality videos, suffer from inefficient multi-step sampling, leading to high latency and computational costs. This hinders their application in real-time scenarios like video generation, content editing, and world modeling for agent training. Scaling these methods to video models is challenging due to high spatiotemporal dimensionality and complex inter-frame dependencies, making it difficult to preserve both global motion coherence and fine spatial details during distillation.
Innovative Solution
This paper introduces Transfer Matching Distillation (TMD), a novel framework designed to distill large video diffusion models into efficient, few-step generators. The core idea is to match the model's lengthy denoising trajectories with a compact, few-step probabilistic transition process.
Technologies Employed
- Decoupled Architecture: The original diffusion backbone is split into a semantic backbone (early layers) for high-level feature extraction and a lightweight flow head (final layers) for multiple internal flow updates, refining visual details.
- Two-Stage Training:
- Transfer Matching Pretraining: The flow head is pretrained using an adapted Mean-Flow method to transform it into a conditional flow mapping capable of iterative feature refinement.
- Distribution Matching Distillation: An improved DMD2 method formulates distillation as a distribution matching problem between the teacher's denoising process and the student's transition process, ensuring alignment in both semantic evolution and visual details.
Achieved Results
Extensive experiments on Wan2.1 1.3B and 14B text-to-video models demonstrate TMD's superior trade-off between generation speed and visual quality. Under comparable inference costs, TMD consistently outperforms existing models in visual fidelity and prompt adherence. For instance, the distilled 14B model achieves a VBench score of 84.24 with near-one-step generation (NFE=1.38), surpassing all one-step distillation methods.
Methodology
The TMD method comprises two training stages: (1) Transfer Matching Pretraining to initialize a flow head for iterative feature optimization; (2) Flow Head Distillation with DMD2-v, an improved DMD2 variant for few-step video generation, applying flow head rollout at each transition step. For simplicity, text conditions of the teacher model are omitted. Below, we outline the student architecture and the two-stage training process.
Decoupled Architecture
Our method follows the transfer matching principle, aiming to approximate the teacher model's numerous denoising steps with fewer, larger transfer steps in the student model. To efficiently predict at each transfer step , we decouple the pretrained teacher architecture into a backbone network (feature extractor) and a lightweight flow head (iterative predictor), i.e.:
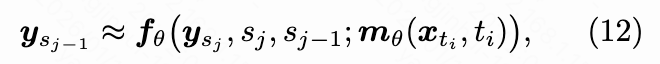
where denotes the time discretization for internal flow, as illustrated in Figure 2.
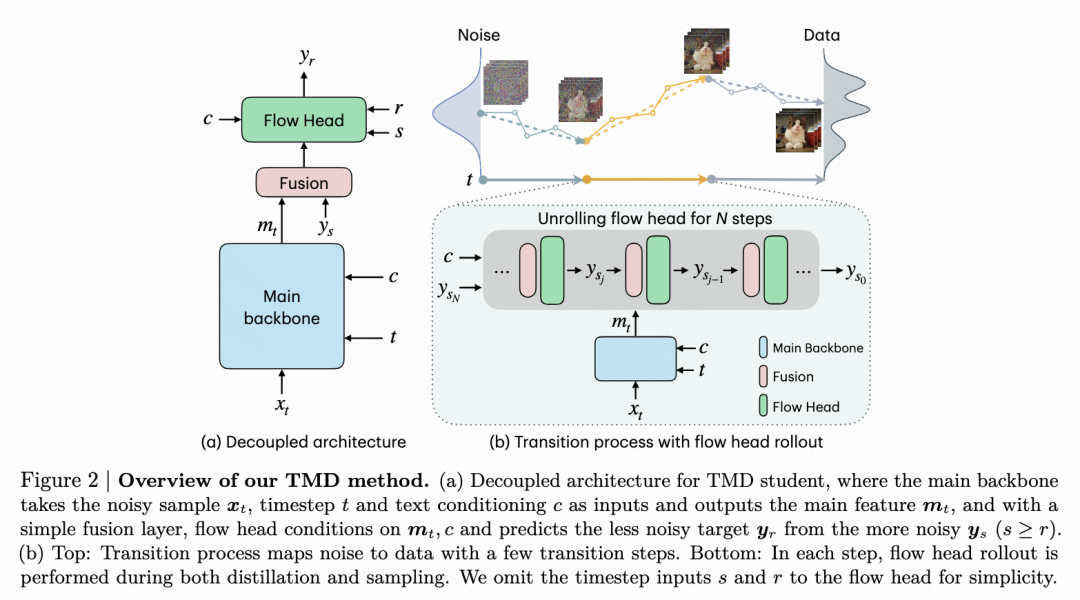
While decoupling has been successful in generative model training, careful design is crucial to minimize interference with the pretrained model. Our design considers two key factors:
- Flow Head Objective: The DTM formulation outperforms other objectives, such as sample prediction (see Appendix B).
- Fusion Layer: A time-conditional gating mechanism fuses primary features and the noisy flow head objective , ensuring initial forward propagation matches the teacher model. Additionally, patch embeddings of the main input are reused for the internal flow input .
Pseudocode for inference is provided in Algorithm 1. 
Stage 1: Transfer Matching Pretraining
Based on the decoupled architecture, we convert the flow head into a flow mapping for iterative optimization before distillation. Similar to Transfer Matching (TM), the flow matching loss in Equation (6) trains the flow head to approximate the internal flow's velocity field. However, this theoretically requires numerous internal steps. Thus, we leverage the MeanFlow method for few-step training.
Transfer Matching Mean Flow Method: Our pretraining algorithm, Transfer Matching Mean Flow (TM-MF), adopts the MeanFlow objective (Equation 9) and conditions it on backbone features = (Algorithm 2 provides pseudocode). We parameterize the conditional internal flow mapping by averaging velocity parameters: 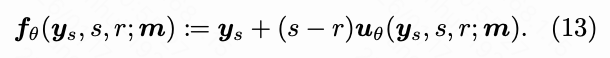
Notably, we do not truncate gradients on backbone network features during training to maintain pretraining flexibility. Directly training the flow head to predict average velocity yields suboptimal results. Our assumption is that the flow head's output should closely match the pretrained teacher's output. Since the teacher network predicts external flow velocity (Equation 2), the flow head should predict E instead. Based on the internal velocity definition (Equation 5), we derive:
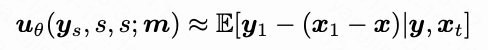
Thus, we parameterize the average velocity as:
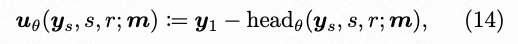
Here, headθ represents the head module in our decoupled architecture (initialized from the teacher network as described in Appendix A). As approaches a certain value, headθ's output approximates the teacher network's velocity prediction.
To enhance performance and stability, we adopt three practices from the original MeanFlow method: (1) Implement flow matching (or transition matching) on partial batch data; (2) Employ classifier-free guidance (adjusting conditional velocity) to discard textual conditions with a specific probability; (3) Apply adaptive loss normalization. Given the complexity of computing the Jacobian-vector product in Equation (10) for large-scale video generation training, we approximate it using the finite difference method, ensuring independence from underlying architecture and training techniques (see references [47,52]).
Since internal flow velocity is not directly obtainable, we use conditional velocity in the objective function (9). Theoretically, a representation of internal velocity could be derived from the pretrained teacher network's velocity (as described in reference [20]), a topic for future research. Transition matching, as a pretraining strategy, can also yield competitive results (as shown in later ablation experiments). Particularly, when using conditional velocity, transition matching pretraining can be viewed as a special case of MeanFlow (Equation 9) under certain conditions.
Phase 2: Distillation Training Based on Flow Head
After TM-MF pretraining, we apply distribution distillation techniques to align student and teacher model distributions. We have significantly improved the baseline DMD2 method for video models and optimized its implementation for TMD.
Improved DMD2-v Scheme: DMD2, initially designed for image diffusion models, may not be optimal for video models. We identify three key factors (DMD2-v) enhancing video DMD2 performance, forming TMD's default training settings:
- GAN Discriminator Architecture: A GAN discriminator with Conv3D layers outperforms others, highlighting the importance of local spatiotemporal features for GAN loss.
- Knowledge Distillation Warm-up Strategy: While improving single-step distillation performance, it tends to introduce coarse-grained artifacts in multi-step generation that are difficult to repair through DMD2 training (see Figure 10 in the Appendix). Thus, DMD2-v applies this strategy only to single-step distillation.
- Time Step Offset Technique: Applying an offset function to uniformly sampled time steps or adding noise to generated samples in the VSD loss enhances performance and prevents mode collapse.
Flow Head Unrolling Mechanism: During dist
Implementation: In this study, we utilize Wan2.1 1.3B and 14B T2V-480p as teacher video diffusion models, and then distill their knowledge into student models of the same size but featuring a decoupled architecture. All experimental procedures are carried out at a latent resolution of [21, 60, 104], with decoding producing 81 frames at a pixel resolution of 480 × 832. The dataset employed in this research consists of 500,000 text-video pairs. The text prompts are sampled from the VidProM dataset (and further expanded using Qwen-2.5), while the videos are generated by the Wan2.1 14B T2V model.
Evaluation Metrics: To evaluate our method and the baselines, we employ VBench [22] (reporting overall scores, quality scores, and semantic scores) and conduct user preference studies to assess visual quality and adherence to prompts. We consider the number of effective function evaluations (NFE) as the total number of DiT blocks used during the generation process divided by the number of blocks in the teacher architecture. For baselines, this corresponds to the number of steps; for our TMD model, it is calculated as:
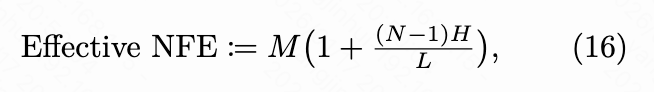
Here, represents the number of internal flow steps, and denotes the number of blocks in the flow head. Specifically, for Wan2.1 1.3B, ; for Wan2.1 14B, .
Comparison with Existing Methods
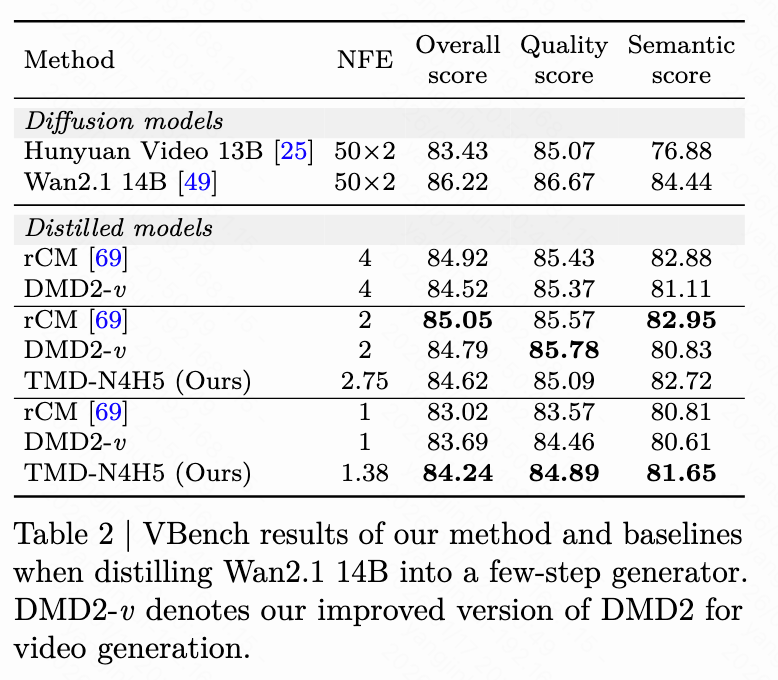
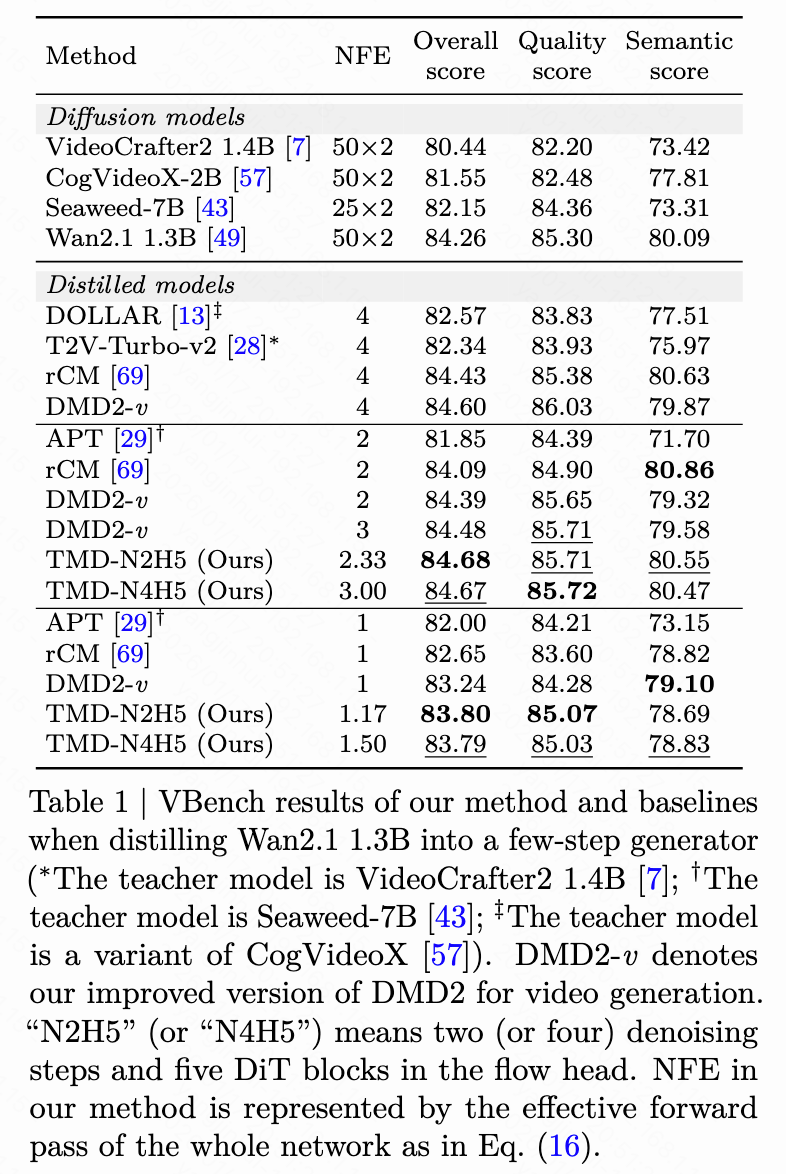
Our TMD method is a video generation adaptation based on an improved DMD2 (denoted as DMD2-v). We compare TMD with DMD2-v and other existing baselines for distilling video diffusion models. As illustrated in Figure 3 below, we provide visual comparisons. In Table 1 below, we present the VBench results when distilling Wan2.1 1.3B (or similarly sized video models) into few-step generators. We group the distilled models based on the number of student denoising steps . When , TMD-N2H5 (with an effective NFE of 2.33, meaning 2 denoising steps and 5 DiT blocks in the flow head) enhances distillation performance. In Table 2 below, we show the VBench results when distilling Wan2.1 14B into few-step generators. DMD2-v represents our improved video generation version of DMD2.

Discriminator Head: As demonstrated in Table 3 below, we investigate the impact of the discriminator head design in DMD2-v for one-step distillation of Wan2.1 1.3B. We compare three types of heads: (1) Conv3D, which processes spatiotemporal features jointly; (2) Conv1D-2D, which separates temporal and spatial convolutions (e.g., as referenced in [64]); (3) Attention, which flattens features into tokens and processes them using self-attention (with pooling downsampling). Conv3D outperforms the other two discriminator head architectures.
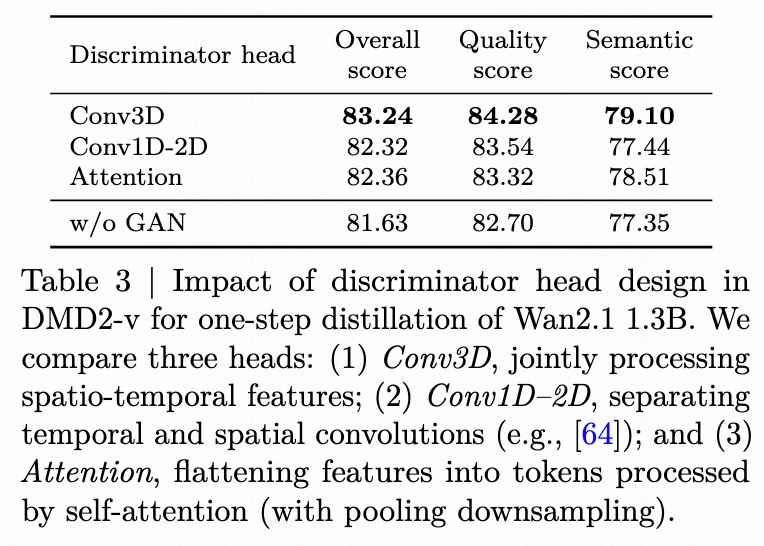
KD Warm-up: As shown in Table 4 below, the overall score on VBench increases with KD warm-up in one-step DMD2 but decreases with KD warm-up in two-step DMD2. This suggests that applying KD warm-up is most beneficial only in one-step generation.
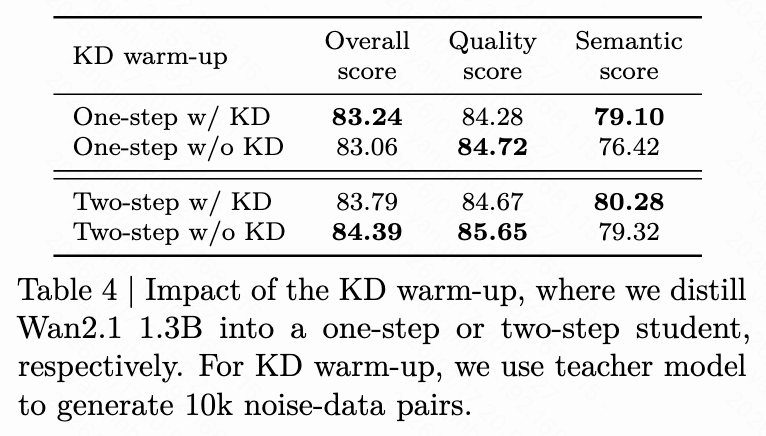
Time Step Offset: As presented in Table 5 below, we find that applying time step offsets to , which controls the noise level in the DMD loss, and to , which controls the number of denoising steps in multi-step student generation, respectively, enhances distillation performance.
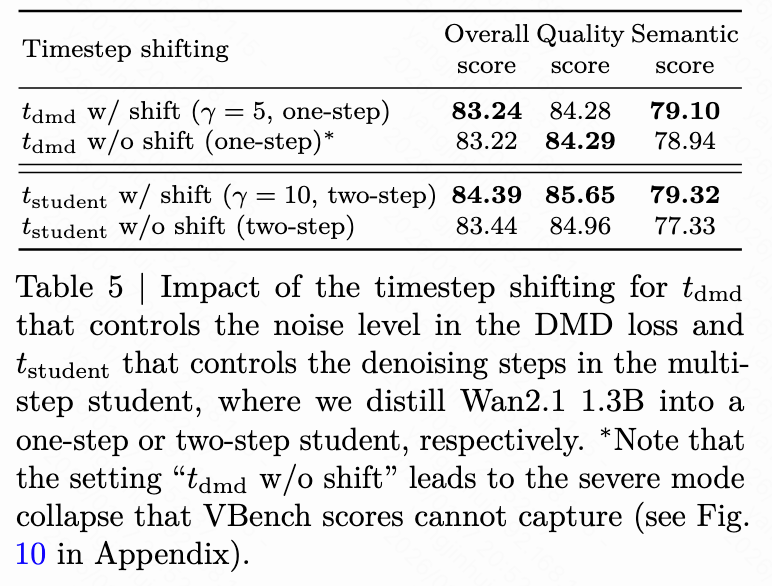
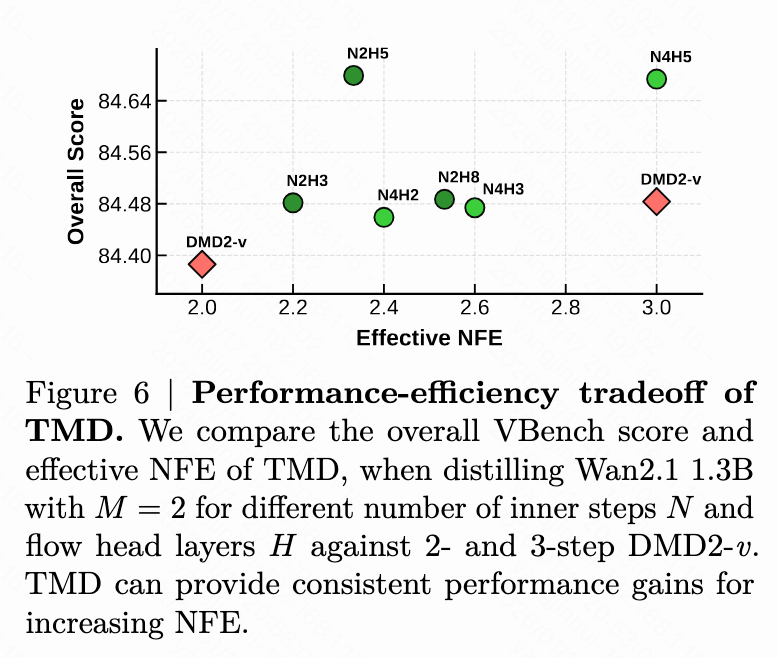
Quality-Efficiency Trade-off: The number of internal steps and the number of flow head layers determine the computational cost of the internal flow. We vary and to conduct a more comprehensive analysis of the performance-efficiency trade-off of TMD. As illustrated in Figure 6 below, we observe that the overall VBench score generally improves as the effective NFE increases. This demonstrates the fine-grained flexibility our method offers in balancing generation speed and visual quality.
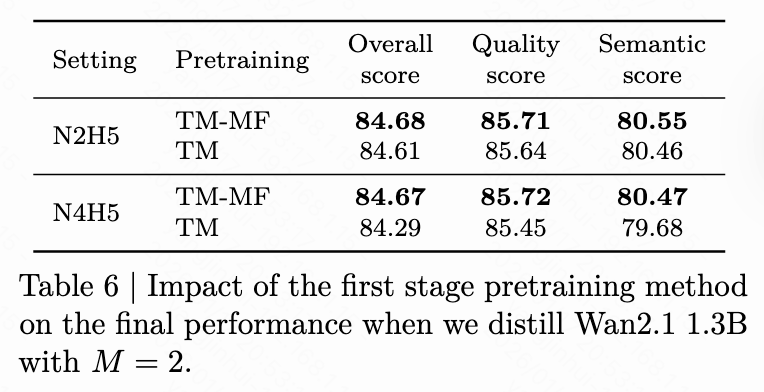
MeanFlow vs. Flow Matching: In transition matching pre-training, we substitute the MeanFlow objective (TM-MF) with the vanilla flow matching objective (TM) to highlight the impact of MeanFlow. As shown in Table 6 below, TM-MF consistently achieves better distillation performance than TM, indicating that TM-MF provides a superior initialization for the second-stage distillation training.
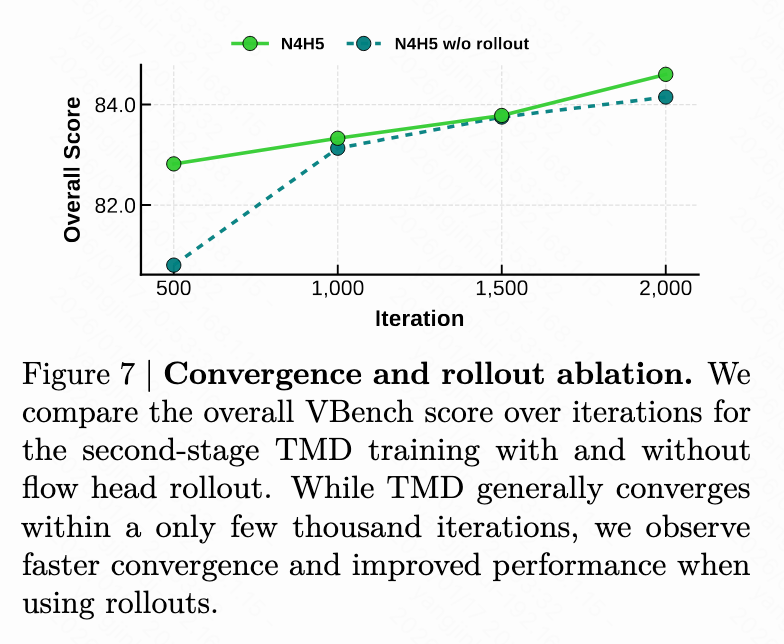
Flow Head Unrolling in Distillation: Closing the gap between training and inference is crucial, and this can be achieved by allowing gradients in the distillation objective to backpropagate through the unrolled internal flow trajectory. As depicted in Figure 7 below, applying flow head unrolling in distillation significantly accelerates training convergence and improves performance.
Conclusion
Transition Matching Distillation (TMD) is a novel framework designed to address the significant inference delay of large-scale video diffusion models. The core of our method lies in the decoupled student architecture, which separates the backbone network for semantic feature extraction from a lightweight recurrent flow head for iterative refinement. This design, combined with a two-stage training strategy that includes transition matching pre-training and distribution-based distillation, has been validated through experiments on distilling state-of-the-art Wan2.1 models. TMD provides fine-grained flexibility across various inference budgets, consistently outperforming existing methods in terms of video quality and adherence to prompts, thus achieving a better trade-off between video generation speed and quality.
References
[1] Transition Matching Distillation for Fast Video Generation
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’