The Latest SOTA in Character Animation! HKU & Ant Group, etc. Present CoDance: Unbinding-Rebinding for Synchronized Dancing of Any Number and Position of Characters on Screen
 01/20 2026
01/20 2026
 598
598
Interpretation: The Future of AI-Generated Content

 Figure 1. Multi-subject animation generated by CoDance. Given a (potentially misaligned) driving pose sequence and a multi-subject reference image, CoDance generates coordinated and pose-controllable group dances without requiring spatial alignment for each subject.
Figure 1. Multi-subject animation generated by CoDance. Given a (potentially misaligned) driving pose sequence and a multi-subject reference image, CoDance generates coordinated and pose-controllable group dances without requiring spatial alignment for each subject.
Highlights
Pioneering Framework: CoDance is the first method capable of achieving the 'Four Any' properties in character image animation based on a single, potentially unaligned pose sequence: any subject type, any number, any spatial position, and any pose.
Unbind-Rebind Paradigm: Introduces a novel 'Unbind-Rebind' strategy that systematically decouples rigid spatial bindings between poses and reference images, re-establishing control through semantic and spatial cues. Constructs a new multi-subject animation benchmark, CoDanceBench, filling the gap in evaluation standards in this field.
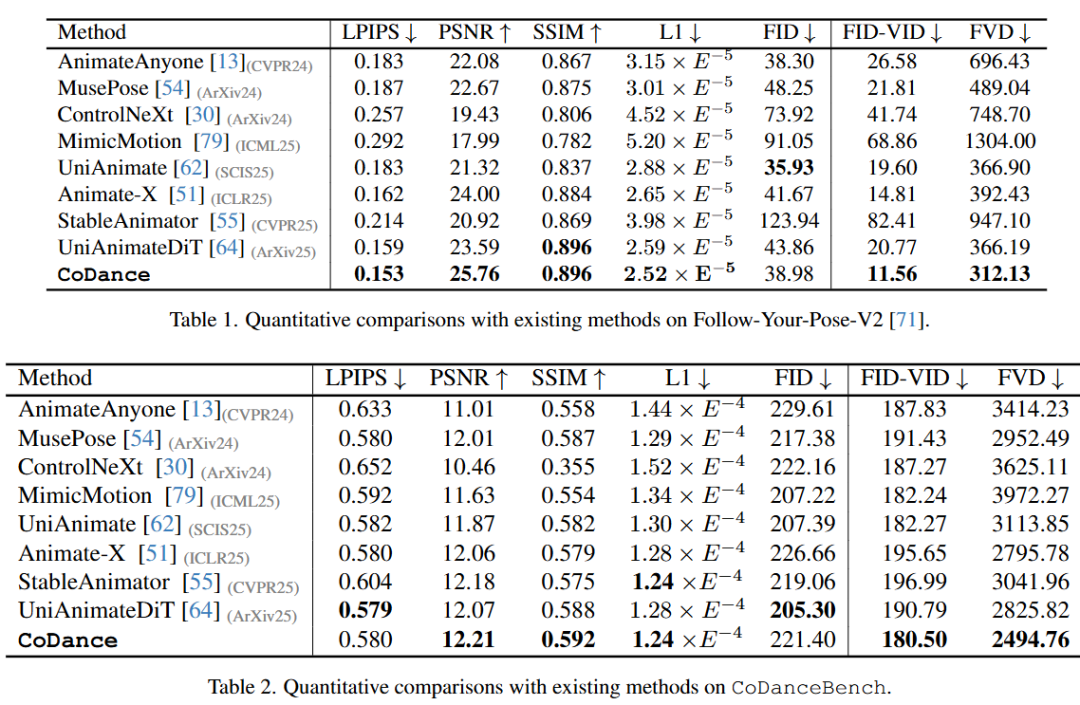
SOTA Performance: Achieves SOTA performance across all metrics on both CoDanceBench and the existing Follow-Your-Pose-V2 benchmark, demonstrating strong generalization capabilities.
Problems Addressed
Limitations of Multi-Subject Generation: Existing character animation methods (e.g., Animate Anyone, MagicAnimate) are primarily designed for single-person animation and struggle to handle arbitrary numbers of subjects.
Spatial Misalignment Challenge: Current methods rely on strict pixel-level spatial bindings between poses and reference images. When the reference image and driving pose are spatially inconsistent (e.g., two characters in the reference but only one pose, or mismatched positions), models tend to fail, producing artifacts or incorrect identity bindings.
Target Redirection Failure: After attempting to decouple spatial positions, models often fail to accurately rebind motions to the intended specific subjects, resulting in incorrectly animated backgrounds or lost subjects.
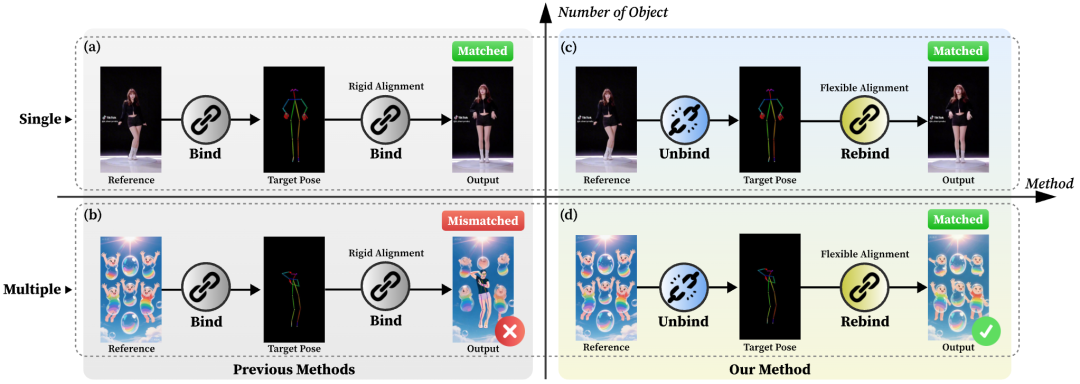 Figure 2. CoDance Motivation. While excelling in single-person animation, previous methods fail when handling multiple subjects due to rigid binding between reference and target poses, leading to mismatched outputs. In contrast, our Unbind-Rebind approach successfully decouples motion from appearance, producing convincing results.
Figure 2. CoDance Motivation. While excelling in single-person animation, previous methods fail when handling multiple subjects due to rigid binding between reference and target poses, leading to mismatched outputs. In contrast, our Unbind-Rebind approach successfully decouples motion from appearance, producing convincing results.
Proposed Solution
Core Architecture: An Unbind-Rebind framework based on Diffusion Transformer (DiT).
Unbind Module:
Introduces a Pose Shift Encoder.
Pose Unbind: Applies random transformations to skeleton positions/sizes at the input level, breaking physical alignment.
Feature Unbind: Randomly duplicates and superimposes pose features at the feature level, forcing the model to learn position-independent motion semantics.
Rebind Module:
Semantic Rebinding: Introduces a text branch, utilizing a mixed-data training strategy (joint training on animation data and large-scale text-to-video data) to explicitly specify subject identities and quantities through text prompts.
Spatial Rebinding: Utilizes an offline segmentation model (e.g., SAM) to obtain subject masks from reference images, using them as external conditions to precisely restrict motions to target regions.
Applied Technologies
Backbone Network: Adopts DiT (Diffusion Transformer) as the foundational generative model, leveraging its scalability for video generation.
Data Augmentation & Training Strategies:
Random translation and scaling augmentation.
Region Duplication at the feature level.
Mixed-data training: Trains animation tasks with probability and general text-to-video (T2V) tasks with probability .
Multimodal Condition Injection:
umT5 Encoder: Processes text prompts, injected via Cross-Attention.
Mask Encoder: Processes subject masks generated by SAM, extracting features through convolution and adding them element-wise to noise latent variables.
VAE Encoder: Extracts latent features from reference images .
LoRA: Used for fine-tuning pre-trained T2V models.
Achieved Results
Quantitative Metric Improvements: Significantly outperforms SOTA methods like MagicAnimate, Animate Anyone, and UniAnimate in video quality, identity preservation, and temporal consistency.
Qualitative Excellence: Capable of generating coordinated group dances, supporting generalization from single to multiple subjects without requiring spatial pre-alignment for each subject. Maintains subject identity features and motion accuracy even with complex reference images and varying subject quantities. User studies show a substantial preference rate.
Methodology
As shown in Figure 3, the CoDance pipeline primarily involves the following steps. Given a reference image , driving pose sequence , and text prompt , this work first obtains subject masks from the reference image and propagates driving motions to any number and type of subjects while maintaining identity consistency with the reference image. Unlike previous work focusing on nearly aligned inputs, this paper explicitly addresses misalignment between and , non-human/anthropomorphic characters, and multi-subject scenarios.
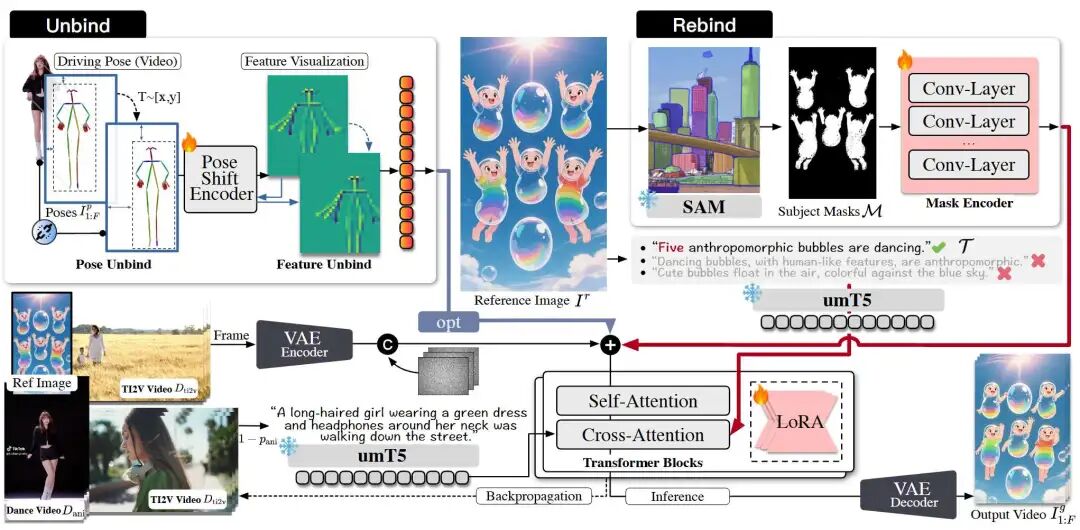 Figure 3. CoDance Pipeline
Figure 3. CoDance Pipeline
Preliminary Knowledge
Diffusion Models. Diffusion models are generative models that generate data by reversing a noise-adding process. This involves two phases: a forward process that gradually adds Gaussian noise to clean data , and a reverse process that learns to remove noise. A key property is that any noisy sample can be directly obtained from . The generative task is accomplished by training a network to predict noise from a noisy input , given a time step and optional conditions . The model is optimized using the following objective function:
For conditional generation, classifier-free guidance is commonly used to enhance the influence of conditions .
Diffusion Transformer (DiT). While early diffusion models used U-Net architectures, Diffusion Transformer (DiT) demonstrated that standard Transformers can serve as efficient and scalable backbones. In the DiT framework, input images are first divided into non-overlapping patches, similar to Vision Transformer (ViT). These patches, along with embeddings of time step and conditions (e.g., pose skeletons), are converted into a sequence of tokens. This token sequence is then processed by Transformer blocks to predict output noise.
Unbind-Rebind
As shown in Figure 2, previous methods typically enforced rigid spatial bindings between reference images and target poses. This paradigm generates correct results in single-person animation as long as human-like reference images spatially align with target poses. However, they are limited by mismatched scenarios, such as differing numbers of subjects between reference images and target poses. Due to reliance on rigid spatial alignment, models fail to correctly animate subjects in reference images. Instead, they hallucinate new, pose-aligned individuals in corresponding spatial regions. To overcome this fundamental limitation, this paper proposes a novel paradigm: Unbind-Rebind, which breaks forced spatial alignment caused by input mismatches and re-establishes correct correspondences between motions and identities.
Unbind. The Unbind module aims to dismantle rigid spatial constraints between reference images and poses. Instead of relying on simple spatial mappings, this paper forces the model (particularly the pose encoder and diffusion network) to learn abstract semantic understandings of motions themselves. To achieve this, this paper introduces a novel Pose Shift Encoder, consisting of Pose Unbind and Feature Unbind modules, enhancing model comprehension at both input and feature levels. The core insight is to intentionally and randomly disrupt natural alignment between reference images and target poses in each training step, ensuring the model cannot rely on rigid spatial correspondences. Specifically, the Pose Unbind module operates at the input level. In each training step, this paper first samples a reference image and its corresponding driving pose as in previous methods. However, instead of directly inputting this data pair into the model, this paper applies a series of transformations to the driving pose . The most intuitive way to break spatial associations is to change pose positions and scales. Thus, in each step, this paper randomly translates the skeleton's position (i.e., ) and randomly scales its size, further decoupling it from the original spatial position.
However, Pose Unbind alone primarily enhances the pose encoder's ability to interpret pose changes. The core generation process heavily relies on the diffusion network. To address this, this paper introduces the Feature Unbind module, which operates at the feature level. After transformed poses pass through the pose encoder, this paper applies further augmentations to the generated pose features. First, similar random translations are applied. Additionally, to force the diffusion model to adapt to various pose configurations in feature space, this paper extracts feature regions corresponding to poses, randomly duplicates them, and superimposes these copies onto the original feature map. This process compels the diffusion model to develop more robust semantic understandings of poses and enhances its generative capabilities under complex conditions.
Rebind. After Unbind operations, while the model can grasp motion semantics from pose images, it lacks crucial information specifying target subjects for animation, as original spatial alignment has been intentionally disrupted. To address this, this paper introduces the Rebind module, which intelligently re-associates understood motions with correct subjects in reference images. Specifically, this paper performs Rebind through two complementary levels: semantic and spatial.
From a semantic perspective, this paper introduces a text-driven guidance branch, explicitly specifying subject identities and quantities in reference images needing animation through input text prompts . As shown in Figure 3, the reference image contains multiple elements, including five anthropomorphic characters as animation targets. Corresponding prompts (e.g., 'five bubbles dancing') are processed by a text encoder and input into the DiT module to provide semantic guidance. However, training solely on animation datasets with uniform text prompts poses a significant challenge: models tend to overfit prompt words, learning spurious correlations and ignoring text guidance, severely impairing generalization during inference. To counteract this, this paper proposes a mixed-data training strategy. This paper incorporates an auxiliary, diverse 'text-image-video' (TI2V) dataset and alternates training between character animation tasks and T2V tasks with probabilities and , respectively. This dual-objective training forces the model to move beyond simple pattern matching and develop robust understandings of text conditions. In turn, this enables accurate rebinding of specified subjects from reference images during inference based on arbitrary text prompts.
While semantic guidance is powerful, it cannot address 'figure-ground ambiguity' challenges, particularly for subjects with complex or unconventional morphologies. This ambiguity may cause models to inaccurately segment subjects, resulting in incorrectly animated backgrounds or partially missing subjects. To enforce precise spatial control, this paper introduces a spatial rebinding mechanism, providing a reference mask to explicitly define animation regions. This direct spatial rebinding ensures animations are strictly confined within specified boundaries, effectively mitigating segmentation errors and preserving subject structural integrity.
Framework & Implementation Details
Building on the success of previous work, CoDance is constructed upon the commonly used Diffusion Transformer (DiT). As shown in Figure 3, given a reference image , this paper employs a VAE encoder to extract its latent representation . Following the approach in literature [64], this latent representation is subsequently directly used as part of the input to the denoising network . To facilitate precise appearance rebinding, this paper utilizes a pre-trained segmentation model (e.g., SAM) to extract corresponding subject masks from . This mask is then input into a mask encoder composed of stacked 2D convolutional layers. The generated mask features are subsequently fused into the noisy latent vector through element-wise summation. Meanwhile, this paper introduces a umT5 Encoder for semantic understanding. Text features are integrated into the generation process through cross-attention layers within DiT blocks. For driving videos , this paper employs the aforementioned pose shift encoder. The model is initialized from a pre-trained T2V model and fine-tuned using LoRA. Finally, a VAE decoder reconstructs the video. Note that the Unbind module and mixed-data training are only applied during the training phase.
Experiment
User Study
To quantify perceptual quality, this paper conducted a comprehensive user study. The study involved paired A/B preference tests administered to 10 participants. Using 20 different identities and 20 driving videos, we generated 20 animations from each of the 9 evaluation methods. In each trial, participants were shown two side-by-side videos generated by different methods and asked to select the better result based on three criteria: (1) video quality, (2) identity preservation, and (3) temporal consistency. As summarized in Table 3, CoDance achieved the highest preference rates across all three criteria, demonstrating its clear perceptual advantage. Specific data are as follows:
Video Quality: 0.90 (CoDance) vs 0.79 (UniAnimateDiT)
Identity Preservation: 0.88 (CoDance) vs 0.50 (UniAnimateDiT)
Temporal Consistency: 0.83 (CoDance) vs 0.78 (UniAnimateDiT)

Ablation Experiment
This section presents ablation studies designed to isolate the contributions and necessity of the Unbind and Rebind modules in CoDance. The experimental design follows a progressive ablation approach:
Baseline: Removing both the Unbind and Rebind modules. The model is trained following a rigid alignment paradigm (following [64]) to animate the reference image.
B + Unbind: Adding the Unbind module on top of the baseline to break the rigid alignment between the reference image and driving pose.
B + Unbind + Spatial Rebind: Combining spatial rebinding with mask conditioning, built upon (2).
Full Model: Incorporating all modules.
As shown in Figure 5:
Baseline: Limited by rigid alignment, it synthesizes a new character spatially aligned with the driving pose, thereby losing the reference identity.
B + Unbind: Introducing the Unbind module corrects the identity issue, preserving the reference identity and demonstrating successful decoupling. However, it fails to generate coherent motions, indicating an inability to localize target regions for animation.
B + Unbind + Spatial Rebind: Adding spatial rebinding resolves the localization issue, animating the correct regions. However, it treats multiple subjects as a single composite entity, resulting in fragmented animations (e.g., animating one hand of each character rather than the full body of one character).
Full Model: Integrating Unbind and the complete Rebind mechanism (including semantic rebinding) achieves superior results.
This progressive process validates the criticality and complementary roles of each proposed module in the framework.
 Figure 4. Qualitative comparison with SOTA methods.
Figure 4. Qualitative comparison with SOTA methods.
Conclusion
CoDance, a novel framework designed for robust animation across arbitrary numbers, types, and spatial layouts of subjects. We identify that identity degradation and motion assignment errors prevalent in multi-subject scenes stem from rigid spatial binding in existing methods. To overcome this, we propose the Unbind-Rebind paradigm, which first disentangles motion from its strict spatial context and then rebinds this motion to the correct subject using complementary semantic and spatial guidance. In this way, CoDance demonstrates strong generalization capabilities and robustness, enabling flexible multi-subject animation. Extensive experiments on the Follow-Your-Pose-V2 benchmark and our newly introduced CoDanceBench demonstrate that our proposed method outperforms SOTA approaches.
Reference
[1] CoDance: An Unbind-Rebind Paradigm for Robust Multi-Subject Animation
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’