2026, Domestic AI Chips: Bridging the Gap from Inference to Training
 02/24 2026
02/24 2026
 648
648
Over the past few years, domestic AI chips have predominantly operated in a relatively secure yet peripheral domain—inference.
In scenarios such as government services, finance, security, and industrial quality inspection, domestic chips have gradually transitioned from being "usable" to "highly effective" by leveraging advantages like cost control and stable supply. However, in AI training—the pinnacle of the computing power pyramid—domestic chips have long been absent or limited to peripheral tasks.
This landscape is now undergoing transformation. The year 2026 is poised to become the "first year of training deployment for domestic AI chips." This step, however, is far from a simple upgrade; it represents a system-level engineering leap.
01
What are the differences between training and inference?
In public discourse, "AI computing power" is often viewed as a unified entity, but in engineering practice, training and inference represent two fundamentally distinct workloads.
The core of training is enabling AI models to "acquire knowledge" by iteratively optimizing model parameters through massive labeled datasets and specific algorithms. This phase demands continuous feeding of vast amounts of data, dynamic updates of billions to trillions of parameters, and uninterrupted operation for weeks or even months, prioritizing throughput and scalable computational efficiency.
This means training chips must not only possess formidable computing power but also feature extremely high memory bandwidth, efficient distributed communication capabilities, and stability at the scale of ten-thousand-card clusters. The training process can be further divided into two stages: pre-training and post-training. Pre-training relies on massive unlabeled or weakly labeled datasets to iteratively optimize model parameters through large-scale computations, minimizing prediction errors and ultimately forming a foundational large model with general generation capabilities. This stage places extremely high demands on the chip's computational performance, interconnection capabilities, and versatility. Post-training, also known as fine-tuning or optimization, builds on the foundational model by using labeled professional datasets to optimize output layer parameters through techniques like quantization and pruning, enhancing domain-specific adaptability through reinforcement learning. Although computationally less intensive than pre-training, its importance in the overall workflow continues to grow with increasing industry-specific demands.
In stark contrast, inference represents the phase where models "apply knowledge" by leveraging pre-trained parameters to predict or generate responses for new input data. It is the core link (translated as "aspect" or "stage" for contextual clarity) of AI technology deployment for solving real-world problems. Compared to training, inference prioritizes speed, energy efficiency, response latency, and cost control. Its deployment spans cloud services, edge nodes, and even end-user devices, demanding far greater stability and energy efficiency than peak computing power. These characteristics allow inference processes to bypass lengthy iterative training, directly utilizing mature models for analysis and prediction, making them highly efficient for massive data processing and real-time response scenarios.
The development of large models follows the empirical formula of the Scaling Law, which states that increases in model parameters, data volume, and computational resources lead to better model intelligence. During the development of general-purpose foundational large models, these models continuously evolve toward larger parameter sizes, with pre-training data volumes growing exponentially. GPUs, as the core of computing hardware, have experienced explosive growth in the pre-training market. According to the China Academy of Information and Communications Technology's "White Paper on China's Computing Power Development (2023)," GPT-3 has approximately 174.6 billion parameters, while GPT-4 reaches around 1.8 trillion parameters, representing a 68-fold increase in training computing power demand. Additionally, xAI's release of Grok-3, which utilized a 200,000-card training chip cluster to enhance model performance, further demonstrates that the pre-training Scaling Law will remain a cornerstone of AI development for the foreseeable future.
More notably, training computing power faces a "diminishing marginal returns" ceiling. For dense-architecture large models, when parameters scale from hundreds of billions to trillions, computing power demand grows superlinearly, with exponentially rising costs making training large models from scratch a "privileged game" for a few tech giants.
With its high computing power threshold, products from international leader NVIDIA have long been the top choice for AI training, capturing over 90% of the AI training market share. NVIDIA's Blackwell architecture supports training for 1.8-trillion-parameter models, and its NVLink 6 technology enables seamless interconnection for 72-card clusters. In contrast, the inference market (especially edge and endpoint inference) has lower chip performance requirements, leading to a diverse landscape where various chips coexist.
Due to the late start of China's AI chip market, domestic vendors typically entered through the relatively lower-threshold inference segment and have achieved phased success. However, the localization rate for training chips remains relatively low. Against the backdrop of escalating export controls on high-performance overseas chips, domestic vendors with high-performance computing capabilities and products effectively applicable to training will fully benefit.
02
What are the challenges in transitioning domestic computing power to training?
The shift from "capable of inference" to "capable of training" may seem like a minor performance upgrade on the surface, but it represents a profound reconstruction across the entire technology stack, posing two major challenges: technological breakthroughs and commercial viability. This tests a company's comprehensive problem-solving capabilities.
At the technical level, the core conflict has shifted from competing on single-chip paper specifications to breaking through interconnection bottlenecks in ten-thousand-card clusters, with the ultimate goal of improving Model Flops Utilization (MFU). On the hardware side, single-card performance improvements alone can no longer meet large-scale training demands, making distributed parallel computing essential. Scale Up achieves this by increasing GPU counts within a single server to build super nodes, while Scale Out expands server scale to form distributed clusters. Overseas giants like Google, Meta, and Microsoft have taken the lead in this area. For example, Google's A3 virtual machine deploys 26,000 NVIDIA H100 GPUs, while its self-developed chip-based 8,960-card TPUv5p cluster optimizes service architecture through scalable cluster advantages. Although domestic vendors have achieved breakthroughs in single-card performance, they still lag behind overseas counterparts in cluster collaboration capabilities.
On the software side, the path of merely compatible (translated as "being compatible with") the CUDA ecosystem has exposed bottlenecks in high-intensity training scenarios, making the construction of a native, efficient, and autonomous software ecosystem inevitable. As large model parameter counts and algorithm complexity increase, training tasks demand continuous upgrades in computing system communication capabilities, with thousand-card and ten-thousand-card intelligent computing clusters becoming standard. However, few domestic vendors possess complete deployment capabilities for training chips. Among them, Huawei HiSilicon has established a significant lead in domestic training chips through its long-term technical accumulation, full-stack collaboration advantages, and rich talent and customer reserves.
Beyond technology, the market votes with the most straightforward logic: stability and Total Cost of Ownership (TCO). These two dimensions constitute the core tests for domestic training chips:
The first is application stability. Training tasks lasting months impose extreme requirements on chip Mean Time Between Failures (MTBF), as a single unexpected interruption can result in millions in sunk costs. This is why intelligent computing centers universally adopt "heterogeneous deployment" strategies—using NVIDIA chips to ensure stable operation of core foundational models while iterating and optimizing domestic chips in vertical model fine-tuning, inference, and other scenarios to build trust and promote the transition from "daring to use" to "willing to use" domestic computing power. Practical deployment is the only way to break through.
The second is industrial system upgrading. Customers ultimately purchase not cold performance metrics like PetaFLOPS but stable and efficient AI productivity. This requires domestic vendors to transform from "single-chip suppliers" to "full-stack computing power solution providers," capable of delivering end-to-end services spanning infrastructure (e.g., power supply, liquid cooling), software optimization, and operational support to provide a high-performance, highly reliable "computing power powertrain."
03
Domestic AI Chips: From Inference to Training
The deployment of domestic chips in training scenarios is not an overnight explosion but the result of policy support and technological iteration, with early signs emerging last year. On August 21, 2025, DeepSeek stated that its new version adopted a technology designed for domestic chips, achieving performance optimization and faster processing speeds.
Policy support is even more explicit: In May 2025, the U.S. Bureau of Industry and Security (BIS) released the "Policy Statement on Controls Potentially Applicable to Advanced Computing Chips and Other Items Used to Train AI Models," the "Guidelines on the Application of General Prohibition 10 (GP10) to Advanced Computing Chips in the People's Republic of China," and the "Industry Guidelines on Preventing the Diversion of Advanced Computing Chips." These measures further tightened export controls on advanced AI chips and related technologies from perspectives such as AI chip usage scope and supply chain sanctions, extending export control risks to all participants in the industrial chain. Geopolitical pressures have compelled domestic clients to adopt domestic GPU products, helping domestic GPU vendors establish close ties with domestic clients and suppliers, thereby accelerating technological and product iteration.
Moreover, the Ministry of Industry and Information Technology, jointly with seven other departments, recently issued the "Implementation Opinions on the Special Action for 'AI + Manufacturing,'" explicitly proposing support for breakthroughs in key technologies such as high-end training chips, edge inference chips, AI servers, high-speed interconnection, and intelligent computing cloud operating systems.
Under these combined factors, 2026 has become the pivotal year for domestic AI chip training deployment.
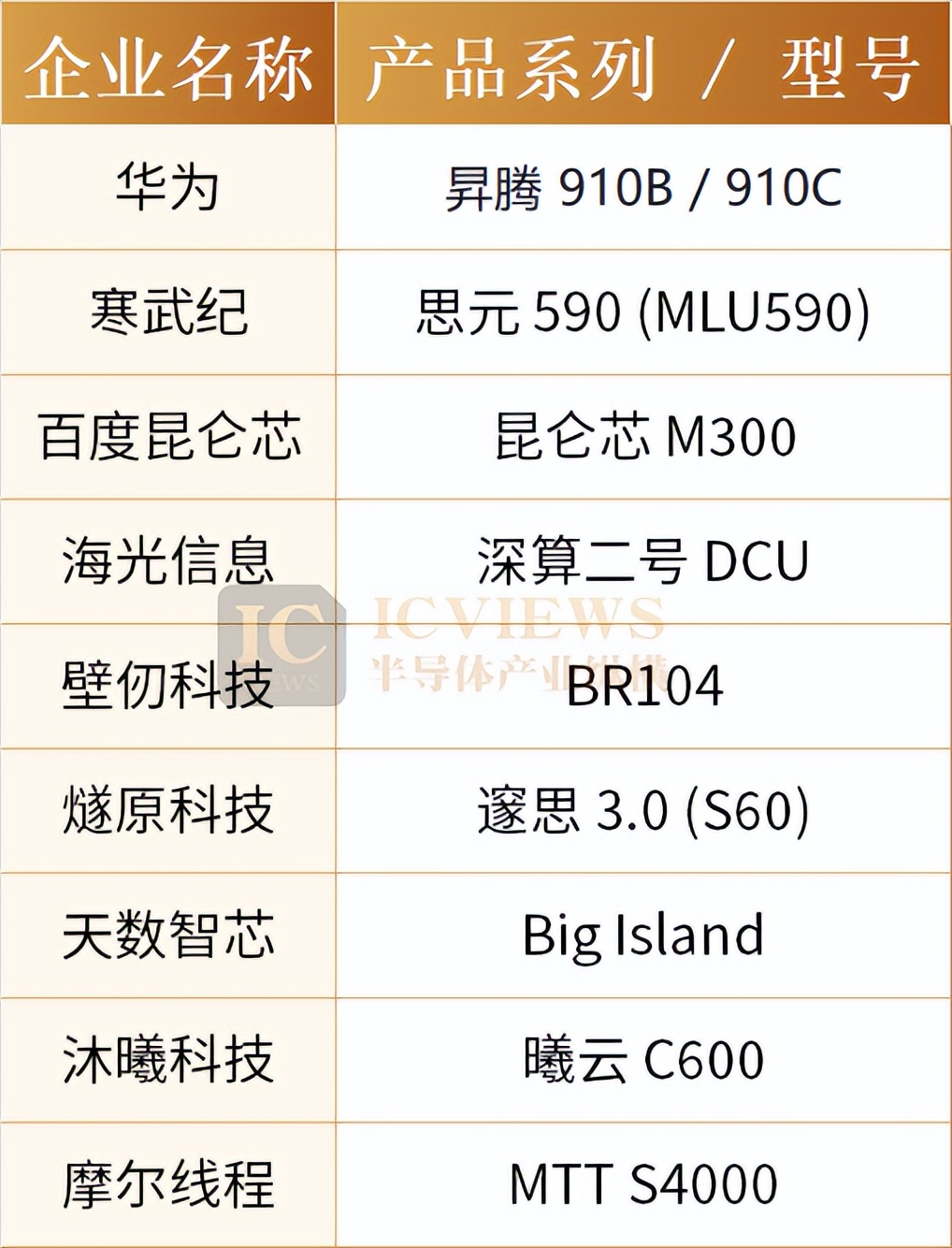
Since this year, a series of AI large models trained on domestic chips have been deployed, marking the validation of domestic computing power's practical capabilities in training scenarios.
On January 14, 2026, Zhipu AI and Huawei jointly open source (translated as "open-sourced") a new generation of image generation model, GLM-Image, which topped the global AI open-source community Hugging Face Trending ranking list (translated as "leaderboard") within 24 hours of release. Based on Huawei's Ascend Atlas 800T A2 devices and the MindSpore AI framework, this model completed the entire workflow from data processing to model training, becoming the first State-of-the-Art (SOTA) multimodal model trained entirely on domestic chips to reach the international pinnacle. This achievement underscores China's breakthrough in end-to-end independent R&D capabilities for AI models, drawing widespread attention from the global AI community, industry, and capital markets.
On January 13, Moore Threads and the Beijing Academy of Artificial Intelligence (BAAI) achieved a breakthrough by successfully completing full-cycle training of BAAI's self-developed Embodied AI Brain model, RoboBrain 2.5, using the MTT S5000 thousand-card intelligent computing cluster and the FlagOS-Robo framework. This outcome verifies, for the first time, the usability and efficiency of domestic computing power clusters in training embodied AI large models, marking the capability of domestic AI infrastructure to handle complex multimodal tasks. Additionally, Moore Threads formally announced a strategic partnership with Pony.ai. The two sides will focus on the deployment and scalable application of L4 autonomous driving technology, collaborating deeply on training and optimizing Pony.ai's core technologies—the World Model and Virtual Driver System—to explore a new paradigm of deep integration between "AI algorithms and AI computing power." Leveraging Moore Threads' MTT S5000 training-inference integrated intelligent computing cards and the KUAE intelligent computing cluster, they will jointly advance the adaptation and validation of Pony.ai's World Model and in-vehicle model training.
China Telecom's recently open-sourced 100-billion-parameter Xingchen Large Model represents a critical breakthrough in China's domestic AI full-stack ecosystem. The TeleChat3 series includes two core models: the Mixture of Experts (MoE)-based TeleChat3-105B-A4.7B-Thinking and the dense-architecture TeleChat3-36B-Thinking. Their entire training process relied on Shanghai Lingang's domestic ten-thousand-card computing power pool, consuming 15 trillion tokens of training data. This marks a milestone in China's AI development history. Technologically, this series achieves full-stack domestic adaptation from hardware to software, deeply integrating Huawei's Ascend ecosystem, including hardware support from Atlas800T A2 training servers, development environments from the MindSpore framework, and complete domestic AI computing power infrastructure support.
Objectively, NVIDIA's A100/H100/H800 series GPUs remain the top choice for training global hyperscale frontier models (e.g., DeepSeek-V3). However, domestic computing power platforms have gradually achieved breakthroughs, stably supporting full-cycle training tasks for models ranging from billions to hundreds of billions of parameters. The previous reliance on overseas GPUs for mainstream large models is shifting, alleviating supply chain security risks. Domestic AI chips are transitioning from "point breakthroughs" in inference to "systematic rise" in training.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







