NeurIPS`25 | Tsinghua Proposes MoGE, a Model-Driven Generative Exploration Mechanism, to Help Reinforcement Learning Algorithms Break Through Performance Limits
 02/25 2026
02/25 2026
 623
623
Interpretation: AI Generates the Future

This article introduces the paper 'Off-policy Reinforcement Learning with Model-based Exploration Augmentation' published by Professor Li Shengbo's research group (iDLab) from Tsinghua University at NeurIPS 2025.
Paper Title: Off-policy Reinforcement Learning with Model-based Exploration Augmentation
Conference: 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
Affiliations: School of Vehicle and Mobility, School of Artificial Intelligence, Tsinghua University
Highlights
High-Exploration-Potential State Sampling Driven by Conditional Diffusion Generator: Adopts a conditional diffusion generator to sample critical states with high exploration potential and theoretically proves that the state distribution in the replay buffer asymptotically converges to the stationary occupation measure of the optimal policy. By continuously fine-tuning the generator, it ensures that its learned distribution shares a common support set with the optimal policy's occupation measure, thereby generating feasible states that comply with state space constraints.
Dynamic Consistency Guarantee of One-Step Imagination World Model: Designs a one-stage imagination world model to simulate environmental dynamics, enabling efficient pre-training through supervised learning. This model not only supports the construction of training experiences but also provides a foundation for classifier design for the conditional diffusion-based critical state generator, ensuring dynamic consistency of the generated samples.
Off-Policy Reinforcement Learning Training Framework: Proposes the MoGE training framework, which seamlessly integrates with existing algorithms. By mixing the generated critical transitions with replay buffer samples through importance sampling, it enhances exploration capabilities while preserving the original structure of the algorithms. Experiments on standard continuous control benchmarks such as OpenAI Gym and DeepMind Control Suite demonstrate that MoGE, as an exploration enhancement framework, can continuously improve the final performance and sample efficiency of baseline off-policy reinforcement learning algorithms.
Background: Exploration vs. Exploitation - The Agent's 'Choice Dilemma'
In online reinforcement learning, every agent faces a seemingly simple yet extremely difficult choice:
'Should I continue on the familiar, safe path, or try an unknown, potentially better new path?'
This is the famous 'exploration vs. exploitation' dilemma. If the agent always repeats learned behaviors, it may remain stable but never discover superior solutions. However, if it blindly tries new actions continuously, it wastes significant time and may frequently make mistakes. Finding a balance between 'stability' and 'risk-taking' is one of the most critical issues in reinforcement learning.
 The Exploration vs. Exploitation Dilemma
The Exploration vs. Exploitation Dilemma
Currently, researchers primarily help agents 'explore the world' in two ways:
Active Exploration: Learning by 'Trial and Error': Active exploration encourages agents to try different choices more frequently. For example, adding a bit of randomness to decision-making (e.g., SAC, DSAC) allows agents to boldly attempt new actions. It's like giving a robot a bit of 'curiosity' to encourage it to explore uncharted paths. This method is simple and direct but has obvious limitations: first, the agent can only explore 'near places it has been'; second, influenced by initialization, the agent struggles to Jump out of the original trajectory (jump out of its original trajectory) and enter truly unfamiliar regions, making it difficult to explore many critical states in complex environments.
Passive Exploration: Learning by 'Reviewing' and 'Supplementing Materials': Passive exploration progresses by organizing and expanding learning materials. Researchers let agents repeatedly review important experiences and even use generative models to 'simulate' new experiences, adding them to the learning library to 'artificially' expose the agent to critical samples. This method improves learning efficiency but has a problem: the generated content mostly mimics the existing experience replay pool, making it difficult to truly Get rid of the limitations of behavioral strategies in existing data (break free from the constraints of behavior policies in existing data). It's like only doing similar types of questions when practicing, making it hard to truly Breaking through the bottleneck of level (break through performance bottlenecks).
How can agents learn to 'imagine in advance' which data is truly important, rather than relying solely on real experiences? Like humans thinking before acting: 'If I take this path, will it be better?'
Motivation: From 'Passive Replay' Samples to 'Active Generation' Samples
Existing passive exploration methods are often limited to mimicking existing data distributions and cannot escape the coverage of behavior policies. On the other hand, directly using world models to generate long trajectories can easily lead to dynamic failure due to error accumulation, producing 'hallucinatory' samples that violate physical laws. To address these pain points, Professor Li Shengbo's research group from Tsinghua University proposes the Modelic Generative Exploration (MoGE) framework for the first time. Its core idea is: instead of randomly generating entire data segments or repeatedly mimicking past experiences, it focuses on directly finding potential critical states that the agent hasn't visited yet but are important, and uses world models to ensure their authenticity, thereby providing more effective training samples for learning and breaking free from the constraints of behavior policies.
Core Highlights: Detailed Explanation of the MoGE Framework
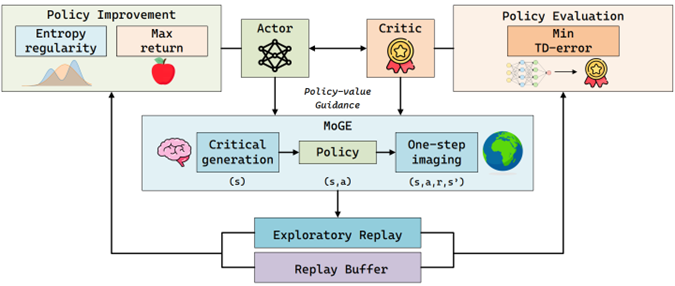 MoGE Framework
MoGE Framework
Unlike other frameworks, MoGE can continuously provide critical training samples for algorithms without modifying policy improvements and can be combined with almost all off-policy RL algorithms (e.g., SAC, TD3, DSAC). It mainly consists of two core components:
1. Critical State Generation
As an important part of the overall model, MoGE no longer directly generates complete state transition data like previous methods. Instead, it introduces a conditional generator based on a diffusion model, specifically designed to generate 'initial states' for reinforcement learning training. Unlike ordinary generative models, this generator does not blindly mimic existing data. Instead, it generates under the guidance of an artificially designed exploration utility function. This utility function incorporates human prior knowledge to characterize which states are more likely to play a critical role in policy learning. Through this conditional guidance mechanism, the diffusion generator can actively focus on high-value regions, thereby generating truly exploratory critical states and providing higher-quality training samples for the agent. In MoGE, for generality, policy entropy and TD error are used as guiding signals to direct the generator in searching for 'critical states' containing high information or uncertainty in high-dimensional spaces.
2. One-Step Imagination World Model
To ensure that the generated samples comply with the true physical laws of the environment, MoGE designs a deterministic one-step imagination world model that shares a latent space with the state generator, ensuring learning consistency and coupling. This world model can be learned through pre-training to guarantee the accuracy of local transitions.
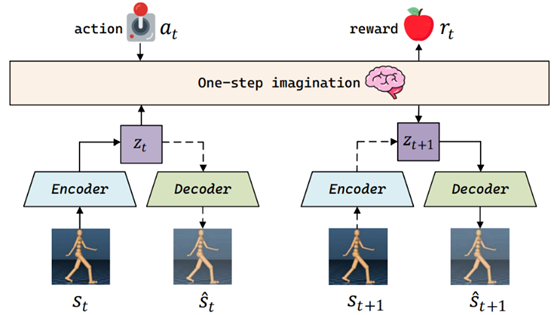 One-Step Imagination World Model
One-Step Imagination World Model
This mechanism of 'high-value initial state generation + one-step transition sample construction' enables MoGE to achieve both the exploration breadth of escaping the data distribution of the experience replay pool and the rigor of physical dynamics. Under the MoGE framework, exploration enhancement can be achieved without modifying the policy and value functions.
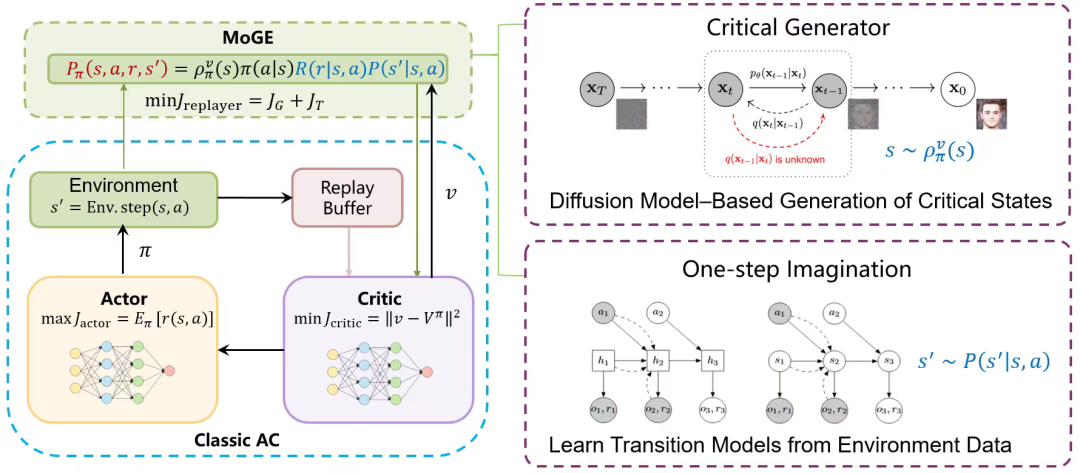 Reinforcement Learning Algorithm Updates Under the MoGE Framework
Reinforcement Learning Algorithm Updates Under the MoGE Framework
Experimental Results: MoGE Empowers Classic Reinforcement Learning Algorithms to Set New Benchmarks in Continuous Control Tasks
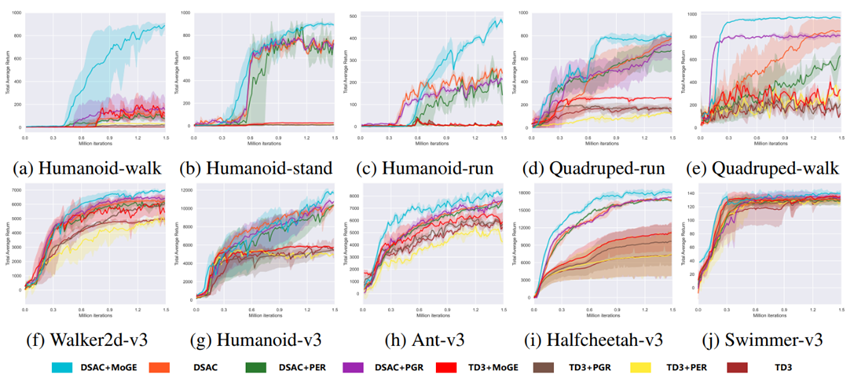 Experimental Results
Experimental Results
To verify the exploration enhancement capabilities of the MoGE framework for reinforcement learning algorithms, we extensively tested DSAC and TD3 as baseline methods on 10 challenging continuous control tasks in OpenAI Gym and DeepMind Control Suite (DMC). Compared to the original algorithms, DSAC enhanced with MoGE exploration demonstrated superior sample efficiency and final performance, surpassing all existing exploration enhancement methods.
DMC Suite Performance: MoGE performed remarkably well in high-dimensional tasks. In the Humanoid-walk task, MoGE achieved a high score of 891.7, a 508.6% improvement over the baseline algorithm DSAC (146.5). Across the entire DMC benchmark, MoGE scored 43.8% higher than DSAC on average.
OpenAI Gym Performance: MoGE also set multiple new records. In the complex Humanoid-v3 task, MoGE reached 12151.1 points, a 16.8% improvement over DSAC, significantly outperforming traditional methods like TD3 and PER.
Comparative Advantages: The experimental results show that MoGE, as an exploration enhancement framework, can stably improve the performance of both stochastic policy (DSAC) and deterministic policy (TD3) algorithms, outperforming existing passive exploration methods (e.g., PGR, PER).
Summary and Outlook
MoGE proposes a new framework for enhancing exploration in reinforcement learning. By combining the powerful generative capabilities of diffusion models with the dynamic constraints of world models, MoGE effectively solves the challenges of 'where to explore' and 'how to ensure authenticity' in high-dimensional spaces. In the future, MoGE can be further extended to more types of algorithms or combined with more expressive generative models to provide a more powerful exploration engine for embodied AI and complex robotic control tasks.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







