Is Language Model Truly Indispensable for Intelligent Driving?
 03/11 2026
03/11 2026
 422
422
Not long ago, a video capturing a voice control malfunction in a particular car brand spread rapidly across the internet. On a late-night highway, the driver casually issued the command, "Turn off all reading lights," with the intention of dimming the interior lights. However, the vehicle's voice system made a critical error—it not only switched off the reading lights but also extinguished the essential headlights. In a state of panic, the driver repeatedly shouted, "Turn on the lights!" Yet, amidst the sound of the vehicle crashing into the guardrail, the voice assistant responded in its calm yet robotic tone, "Not yet."
This incident sparked widespread online debate, not merely due to the accident itself but because it precisely resonated with people's apprehensions about the "software-defined vehicle" era. As physical buttons in cars vanish and functions such as lighting, air conditioning, and even gear shifting are entrusted to a series of codes and that seemingly intelligent voice assistant, are we genuinely safer? Are language models crucial for autonomous driving and intelligent cockpits, or are they merely flashy accessories?
Why Does the Voice Assistant Sometimes Seem a Bit 'Deaf'?
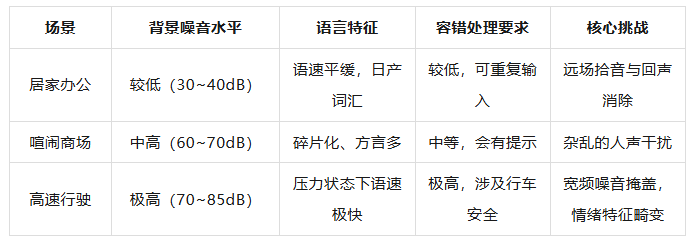
Why does an AI capable of understanding your lame jokes at home sometimes become 'half-deaf' on the highway? The interior of a vehicle is actually a highly noisy environment. When a car reaches speeds of 100 kilometers per hour, tire noise, wind noise, and the high-frequency vibrations of the engine or motor merge into a cacophony of background noise.
For human ears, we possess an incredibly sophisticated filtering mechanism that automatically isolates our companion's voice from the noise. However, for the vehicle's microphone, it receives a signal intertwined with various waveforms.
In the accident video, the driver's command was, "Turn off all reading lights." From the perspective of Mandarin pronunciation and semantic vectors, "reading lights" and "all vehicle lights" may be closely aligned in certain parsing algorithms. Especially amidst the background noise of high-speed driving, the sound's feature code can become distorted.
The Automatic Speech Recognition (ASR) system might lose the distinguishing features of the word "reading" in the initial step, leaving only the word "light" and the action "turn off." Subsequently, the Natural Language Understanding (NLU) module will make a probabilistic guess and ultimately select the action with the highest weight—turning off all lights.
In fact, the most intriguing aspect of the entire video is the final response, "Not yet." This highlights another technical shortcoming of current in-vehicle voice systems: their recognition ability under extreme stress. When the lights go out and survival is at stake, the driver experiences intense physiological reactions—rapid breathing, a raised pitch, and extremely fast speech.
Traditional voice models are trained on calm and steady voice databases. Confronted with these panic-filled "distress signals," they may trigger preset fallback responses due to low confidence. These preset responses are intended to appear approachable, but at that critical moment, they feel somewhat out of place.
Ultimately, the current voice assistant remains merely a "translator" seated in the passenger seat. It merely translates commands without truly comprehending their implications for a vehicle moving at high speed.
The Collapse of Domain Isolation and the Disappearance of 'Lifesaving' Buttons
Many people are puzzled—if the voice assistant might mishear, why does it have the authority to directly turn off the headlights while driving? This actually pertains to a professional concept in automotive electronic architecture: domain isolation. A vehicle's electronic system is typically divided into different "domains," such as the cockpit domain for entertainment, navigation, and voice; the body domain for lighting, wipers, and windows; and the chassis domain for power and braking.
Following safety logic, the cockpit domain should merely serve as a talkative guide—it shouldn't possess the authority to directly interfere with the driver's "steering wheel" and "external lights."
However, in pursuit of so-called "fully intelligent interaction," enabling the driver to control everything in the car with just their voice, manufacturers create a fast communication channel between the cockpit and body domains. This incident has exposed the enormous safety risks associated with permission management for this channel.
The control authority for the headlights, which should belong to a high-safety level, was too casually handed over to a low-safety-level voice recognition module. In the automotive functional safety standard ISO 26262, this constitutes a serious logical flaw. While the vehicle is moving at high speed, the system not only fails to set a secondary confirmation for dangerous commands like "turn off headlights" but also doesn't perform a joint verification of speed, ambient light, and headlight status.
The consequences of this "minimalist" approach are severe. With the disappearance of physical buttons, the driver can no longer rely on muscle memory to turn on the lights via a lever when visual guidance is lost. After the accident, the automaker urgently rolled out an OTA update, modifying the headlight-off permission while driving to "manual control only."

Image Source: Weibo
This is essentially a reclamation of authority. It demonstrates that under current technological conditions, uncertain voice interactions should not hold the highest authority over managing safety-critical components. Those physical levers, dubbed "lifesaving buttons" by netizens, provide a physical certainty that transcends software algorithms. In life-and-death situations, certainty outweighs so-called intelligence.
Are Language Models the Solution or the Problem for Autonomous Driving?
Given that traditional voice systems are prone to mishearing, can the recently popular Large Language Models (LLMs) resolve this issue? In the field of autonomous driving, experts often refer to "System 1" and "System 2." System 1 is intuitive and fast, akin to our muscle memory when driving—seeing a red light and braking. System 2 is rational and slow, employed to handle complex situations and unexpected events.
Currently, most autonomous driving systems and voice assistants operate at the System 1 level. They rigidly match keywords. If you say, "Turn off the reading lights," it matches those words, and a mishearing leads to a complete failure. The significance of large models lies in equipping the vehicle with a "System 2" capable of common-sense reasoning. A system equipped with a large model, upon hearing "Turn off all lights," would not immediately execute but instead perform a logical self-check.
It would activate visual sensors to notice it's nighttime, GPS would inform it's on the highway, and its common-sense knowledge would remind it that turning off the headlights on a highway at night is suicidal. Thus, it would refuse to execute this absurd command or confirm with the driver in a more logical manner.
This ability is known as "multimodal understanding." Future language models will no longer just process text—they will integrate vision (what the camera sees at night), actions (the speed of high-speed driving), and semantics (the driver's request). This is the well-known VLA (Vision-Language-Action) model.
However, large models are not flawless. Their biggest issue is "hallucination." Essentially, a large model is a probability predictor—every instruction it outputs is based on statistical likelihood, not logical certainty.
For driving, even a one-in-ten-thousand chance of hallucination is unacceptable. Therefore, the application of large models in vehicles is currently more about serving as a "brain" for thinking, while the actual "limb" control still requires strict, hard-coded logic to oversee.
How to Maintain Safety Boundaries in the Software-Defined Future
To ensure the accuracy and safety of voice recognition, we cannot solely rely on AI becoming smarter—we must also enhance the system architecture. Redundancy at the hardware level is crucial, such as employing multi-microphone array beamforming technology to directionally capture the driver's voice like a searchlight, thereby canceling out external broadband noise. Meanwhile, core command parsing must possess "offline processing" capabilities—it cannot fail to respond or process commands due to a lack of signal in a tunnel.
A more fundamental improvement should involve the introduction of semantic verification mechanisms. A qualified intelligent cockpit should not merely be an obedient assistant but a steward with safety boundaries. The system needs to establish a scenario-based "sensitive command library." In specific scenarios like high-speed driving, rainy/snowy weather, or nighttime, the voice assistant's permissions for all functions related to vehicle safety (e.g., headlights, parking brake, door opening) should be locked or require physical confirmation.
Moreover, we must acknowledge that the goal of intelligence should be to reduce human error, not to introduce new risks. When automakers pursue intelligent cockpits, they must not forget that a car is merely a mode of transportation—its primary logic will always be safety. Language models are indeed a bridge toward "human-like" autonomous driving in the future, but until that bridge is built, physical levers remain the last bastion of control that technology offers us.
Final Thoughts
Technological progress should not be a popularity-driven adventure. As many seasoned drivers say, the best technology should be imperceptible in daily use but provide the most certain response in emergencies. In the rush toward intelligence, we must not move too hastily. Large models are impressive, and voice control is cool, but in the face of those physical levers that allow us to maintain control, they are still just assistants, not masters.
-- END --
-
The Backside Knife Skills of vivo S60 and OPPO Reno16
-
![]()
Breaking News | Core Chip Team Member Unexpectedly Changes Jobs! OpenAI Transforms into Anthropic's Talent Hub, with Over 15 Ex-OpenAI Core Members Now Holding Key Roles at Anthropic
-
![]()
When European Factories Face Idle Capacity, Chinese Brands Offer a ‘Traditional Chinese Remedy’
-
![]()
SEER Robotics Passes IPO Hearing: How Valuable Is the 'First Robot Brain Stock?'
-
![]()
5 Years, 170 Billion Yuan Wealth Vanishes: Where Did Wei Jianjun Go Wrong?
-
![]()
What Exactly Has Changed with the AI That Automatically Opens a Browser to Search Xiaohongshu?
-
![]()
Over 3,000 Heat-Related Deaths Daily, Yet India Imposes Ban on Chinese Air Conditioner Imports: Unraveling the Underlying Motives
-
![]()
Second-Hand Car Prices Plummet: Are Gasoline Vehicles on the Verge of Collapse?