Image Generation Ushers in a New Paradigm of 'Think-Research-Create'! Mind-Brush: Unifying Intent Analysis, Multimodal Search, and Knowledge Reasoning
 03/12 2026
03/12 2026
 553
553
Interpretation: The Future of AI-Generated Content

Key Highlights
Mind-Brush, a novel agent framework, unifies intent analysis, multimodal search, and knowledge reasoning to achieve the 'Think-Research-Create' paradigm for image generation.
Mind-Bench, a benchmark specifically designed to evaluate generative capabilities involving dynamic external knowledge and complex reasoning. Experimental results reveal critical deficiencies in real-time perception and logical reasoning among current unified multimodal models.
Mind-Brush substantially improves the accuracy of the Qwen-Image baseline on Mind-Bench from 0.02 to 0.31, while significantly outperforming existing baseline models on established benchmarks, including knowledge-driven WISE (25.8% improvement in WiScore) and reasoning-driven RISEBench (27.3% increase in accuracy).
Summary Overview
Problems Addressed
Lack of Intent Understanding and Complex Reasoning Capabilities: Existing models are essentially 'static text-to-pixel decoders' that can only perform explicit instruction mapping and fail to understand users' implicit intentions. Even emerging unified understanding and generation models struggle to complete tasks requiring complex knowledge reasoning (e.g., mathematical reasoning, commonsense reasoning) within a single model.
Inability to Adapt to a Dynamically Changing World: Due to the time truncation of pre-training data, models possess static internal knowledge. This renders them incapable of handling generative tasks involving real-time news, emerging concepts, or the need for verification against the latest facts, resulting in a disconnect from the dynamic developments of the real world.
Proposed Solution
The paper introduces Mind-Brush, a unified agent framework. The core idea of this framework is to transform image generation from a single-step static mapping into a dynamic, knowledge-driven workflow.
Core Paradigm Shift: Simulates the human creative process by proposing a 'Think-Research-Create' workflow.
Proactive Generation: The model no longer passively relies on internal knowledge but actively plans and compensates for its limitations by invoking external tools, achieving a unified understanding and generation.
Technologies Applied
The Mind-Brush framework primarily achieves its core functionalities through the following technologies:
Agent Design: Adopts an architecture similar to LLM agents, enabling the model to decompose tasks and plan actions.
Proactive Retrieval Mechanism: Capable of actively retrieving multimodal evidence to acquire and utilize information beyond its internal knowledge scope, thereby grounding generated content in real and up-to-date information.
External Reasoning Tools: Integrates and employs reasoning tools to resolve implicit visual constraints in user instructions that require logical deduction or computation.
Achieved Results
By introducing the Mind-Brush framework and corresponding evaluation benchmarks, the paper demonstrates significant performance improvements:
Capability Leap: On the proposed Mind-Bench benchmark, Mind-Brush enables the baseline model (Qwen-Image) to achieve a 'from nothing to something' capability breakthrough.
Comprehensive Evaluation: Introduces a new evaluation benchmark, Mind-Bench, comprising 500 samples covering ten categories requiring dynamic knowledge and complex reasoning, such as real-time news, emerging concepts, mathematical reasoning, and geographical reasoning, filling gaps in existing evaluations.
Performance Advantages: Not only excels on Mind-Bench but also achieves superior results on established benchmarks like WISE and RISE, which require internal knowledge utilization and basic reasoning.
Architecture and Methodology
The Mind-Brush Framework
Problem Formalization
This work formalizes the reasoning workflow of Mind-Brush as a Hierarchical Sequential Decision-Making Process, defined by the tuple . The framework generates a structured cognitive trajectory to bridge the gap between abstract intent and visual realization.
Cognitive State (): Let represent the state at step . It encapsulates the original user input (instruction and optional reference image ) as well as a dynamic evidence buffer , responsible for accumulating retrieved knowledge and reasoning chains.
Action Space (): The set of operations available to the agent. This work distinguishes between meta-actions (Meta-Action) (cognitive gap detection) for identifying cognitive gaps , and execution actions (Execution Actions) for proactively acquiring multimodal evidence.
Execution Policy (): The intent analysis module serves as the high-level policy . It evaluates the initial state to formulate a deterministic execution path based on the identified .
The reasoning process evolves as a context-aware trajectory. As shown in Figure 2 below, the system does not follow a rigid workflow; instead, it dynamically adjusts based on user requests. By assessing the specific nature of cognitive gaps in the initial state (e.g., factual omissions or logical conflicts), the planner infers the optimal structure for evidence accumulation, routing execution to specialized search or reasoning branches. This effectively aligns reasoning computation with the intrinsic complexity of user intent. Ultimately, this work aims to generate the optimal target image based on the final converged state . This state contains the integrated master prompt and verified visual references , thereby transforming static generation into a dynamic, explicit evidence accumulation process.
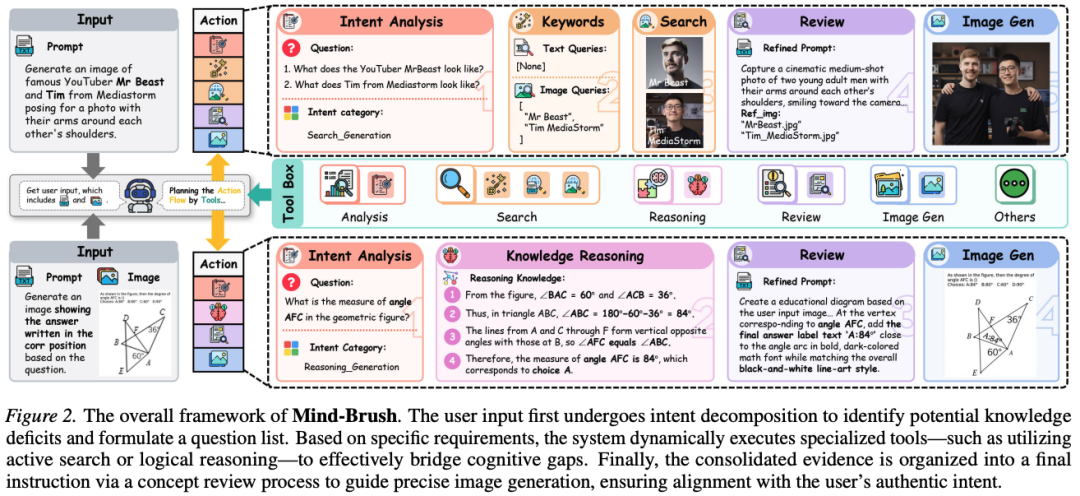
Cognitive Gap Detection
User instructions often contain implicit constraints and long-tail concepts that exceed the model's parametric knowledge boundaries. To address this, the paper introduces a Cognitive Gap Detection strategy, integrated into the Intent Analysis Agent (Intent Analysis Agent, ) as a meta-planner to bridge this cognitive divide. Specifically, it maps text instructions and optional images into a structured semantic space using the 5W1H (What, When, Where, Why, Who, How) paradigm, establishing a multimodal 'ground truth' to determine signal dominance. Subsequently, the module performs rigorous gap analysis by detecting specific entities or logical dependencies requiring external verification. Information missing from internal knowledge is formalized into a set of explicit atomic questions, denoted as . Based on the composition of , the system instantiates a dynamic execution policy , routing the workflow to the appropriate factual grounding or logical reasoning branches defined in the action space.
Adaptive Knowledge Completion
To bridge the identified cognitive gaps, Mind-Brush employs an internal logical deduction mechanism. Unlike rigid single-path systems, the execution policy flexibly combines retrieval and reasoning tools based on the complexity of .
External Knowledge Anchoring: For gaps involving out-of-distribution (OOD) entities or dynamic events, the framework activates the Cognition Search Agent (Cognition Search Agent, ). It first utilizes a keyword generator to synthesize the user's multimodal inputs () and the identified gaps , generating precise text queries and initial visual queries . After retrieving factual documents from open-world knowledge bases, the system performs a dual update operation: retrieved concepts are re-injected into the user instructions () to update the textual context, while visual queries () are calibrated to ensure subsequent retrieved reference images align with verified facts. Internal Logical Derivation: For gaps requiring complex deduction (e.g., solving mathematical problems in or inferring spatial relationships from retrieved data), the system triggers the Chain-of-Thought Knowledge Reasoning Agent (CoT Knowledge Reasoning Agent, ). This engine acts as a logical processor, ingesting user instructions, input images, and, crucially, accumulated search evidence (). It performs multi-step reasoning to resolve implicit conflicts or interpret retrieved visual data, producing explicit conclusions .
The final evidence set forms a comprehensive and logically consistent cognitive context for generation.
Constrained Generation
The accumulation of external information carries the risk of redundancy or irrelevance. Therefore, the final stage focuses on information integration and conditional synthesis. First, the Concept Review Agent (Concept Review Agent, ) serves as an integration mechanism, filtering noise from disjointed evidence streams . It synthesizes verified facts and logical conclusions with the user's original creative intent, rewriting them into a structured master prompt . This prompt explicitly articulates previously implicit or unknown visual attributes. Subsequently, the Unified Image Generation Agent (Unified Image Generation Agent, ) executes visual synthesis. Unlike standard T2I (text-to-image) models, is conditionally constrained by both the text-aligned and adaptive visual prompts . Specifically, based on user intent, the mechanism dynamically selects between generation and editing modes to determine the visual condition source (i.e., from or ). These constraints effectively guide the model to achieve high fidelity to the user's creative vision while strictly adhering to the factual and logical boundaries established during the knowledge acquisition phase.
The Mind-Bench Benchmark
Motivation and Task Definition
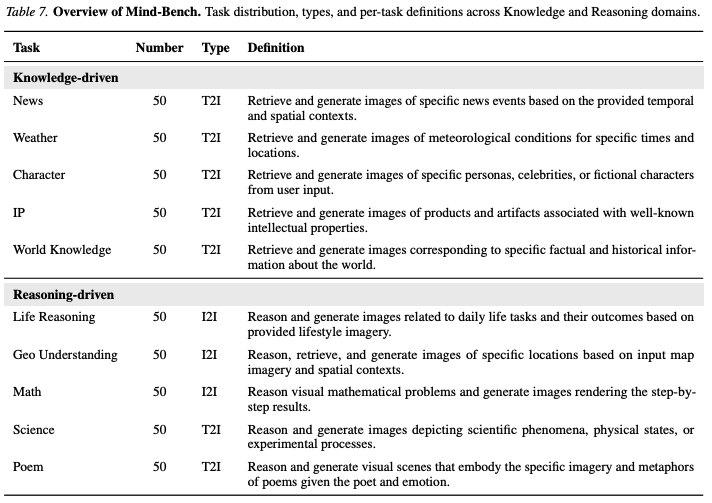
To explore the boundaries of 'cognitive generation,' this paper introduces Mind-Bench, a comprehensive benchmark comprising 500 samples designed to objectively evaluate generative capabilities reliant on dynamic external knowledge and user intent reasoning. As shown in Figure 1 below, the benchmark is divided into two major categories, covering ten different sub-domains:
Knowledge-Driven Tasks: Includes special events, weather, characters, objects, and world knowledge. The core challenge lies in mitigating hallucinations regarding out-of-distribution (OOD) entities.
Reasoning-Driven Tasks: Includes life reasoning, geographical reasoning, mathematics, science and logic, and poetry. The core challenge lies in the model's ability to deduce implicit constraints from superficially simple instructions.
Benchmark Construction and Evaluation Criteria
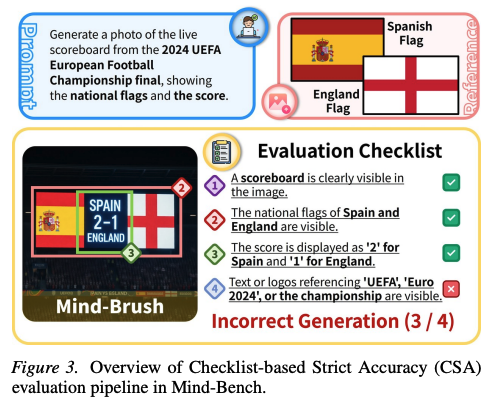
The benchmark is constructed through a rigorous 'human-machine collaboration pipeline' to ensure multi-dimensional complexity and factual reliability. To accurately reflect model usability in complex cognitive tasks, this paper proposes Checklist-based Strict Accuracy (CSA) as the core metric, as shown in Figure 3 below. This standard employs an MLLM judge to carefully examine generated images against a checklist under a 'holistic pass criterion.' Accuracy is defined as:
where is an indicator function that returns 1 if the image satisfies the checklist item. A sample is only considered correct if all sub-items are verified as 'pass.'
Experiments
This paper comprehensively evaluates the Mind-Brush framework's capabilities in understanding user intent and generating long-tail concepts through extensive experiments, primarily tested on three benchmarks: Mind-Bench, WISE, and RISEBench. It conducts broad comparisons with current proprietary models (e.g., GPT-Image series, Nano Banana series, FLUX series) and open-source SOTA models (e.g., SD 3.5, Bagel, Qwen-Image, etc.). Additionally, detailed data on relevant evaluation protocols, task classification distributions, and other comparisons can be found in Table 7 and Table 8 below.
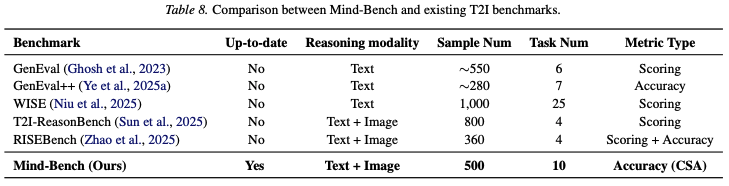
The main experimental results are summarized as follows:
Performance on the Mind-Bench Benchmark:
As shown in Table 1 below, Mind-Brush achieves significant improvements on both knowledge-driven and reasoning-driven tasks. Compared to the open-source baseline model Qwen-Image, Mind-Brush dramatically increases the overall strict accuracy (CSA) from 0.02 to an astonishing 0.31, representing a capability leap from 0 to 1. It not only surpasses SD-3.5 Large but even matches or exceeds numerous powerful closed-source proprietary models on multiple tasks (e.g., surpassing GPT-Image-1.5's 0.21).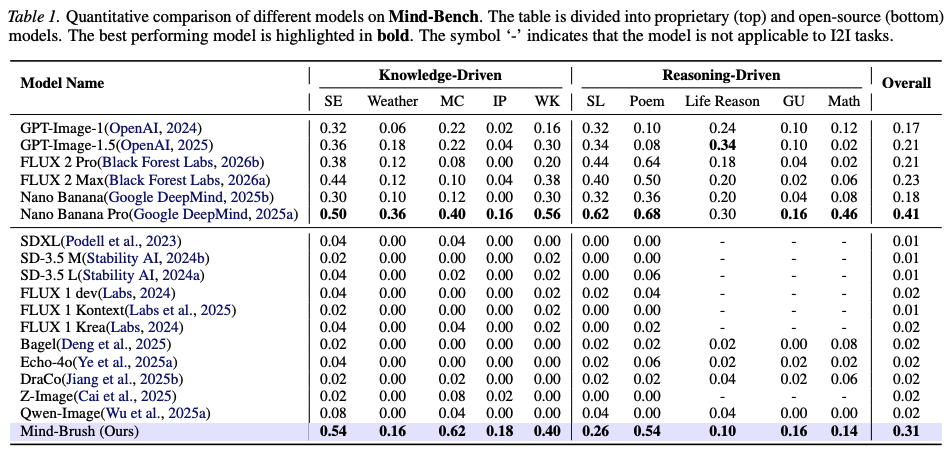
Performance on WISE and RISEBench:
As shown in Table 2 below, on the WISE benchmark, which emphasizes world knowledge, Mind-Brush achieved a comprehensive WiScore of 0.78, a 25.8% improvement over the base model Qwen-Image, matching the top-tier GPT-Image-1. On the RISEBench, which focuses on logic and visual editing, our method scored 61.5 in the 'Instruction Reasoning' dimension, significantly outperforming models like Bagel, and its overall accuracy (24.7%) also approached that of the most advanced proprietary models.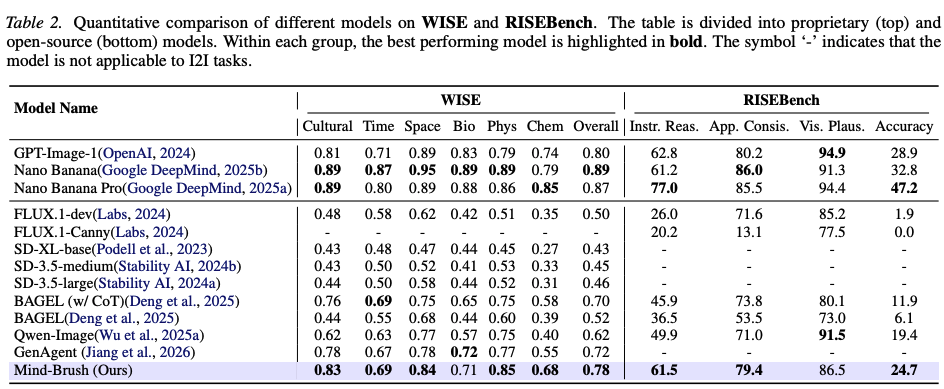
Qualitative Comparison and Process Visualization:
As shown in Figure 4 below, the qualitative results visually demonstrate how Mind-Brush effectively utilizes search tools to retrieve visual references when handling knowledge-driven tasks (e.g., accurate rendering of niche IP concepts) and correctly deconstructs mathematical logic and spatial relationships in reasoning-driven tasks, avoiding factual errors and logical gaps common in baseline models. As shown in Figure 19 below and Figure 20 below, they illustrate the complete workflow of Mind-Brush in handling complex geospatial-mathematical tasks and pure mathematical visualization tasks, including step-by-step retrieval, reasoning, and constrained generation.


Ablation Experiments and Architectural Analysis:
The ablation studies shown in Table 3 below confirm the effectiveness of the cognitive search agent and the knowledge reasoning agent. Adding either the reasoning agent or the search agent alone leads to domain-specific improvements, while their synergy achieves the optimal overall performance. As shown in Table 6 below, experiments exploring different MLLM backbones and generation engines reveal that the strength of the agent's 'brain' (e.g., using GPT-5.1 instead of Qwen3-VL) dominates the upper limit of overall performance; meanwhile, a stronger underlying image generator (e.g., GPT-Image-1) can synergize with the Mind-Brush framework to achieve multiplicative performance gains.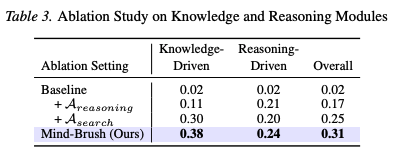
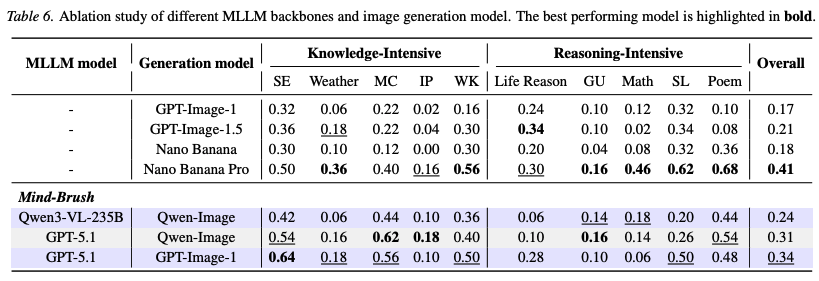
Extended Testing on Additional Benchmarks:
As shown in Table 4 below and Table 5 below, on GenEval++, which emphasizes instruction following, and Imagine-Bench, which focuses on creative generation, Mind-Brush also demonstrates superior performance, even surpassing the current best Agentic baseline, GenAgent, in some subtasks (e.g., position/counting, spatiotemporal disambiguation), showcasing strong long-tail instruction handling and generalization capabilities.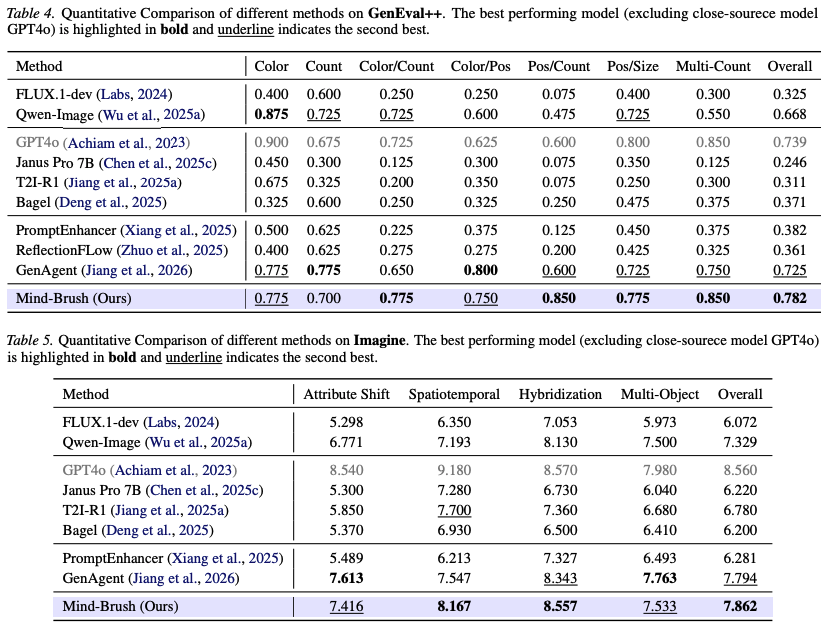
Conclusion
This paper introduces Mind-Brush, a training-free agentic framework that transforms text-to-image generation from passive decoding into an active cognitive workflow. By coordinating intent analysis, multimodal anchoring, and explicit Chain-of-Thought reasoning, Mind-Brush effectively bridges the gap between ambiguous user intent and precise, fact-based visual synthesis. To rigorously evaluate this, we establish Mind-Bench, a benchmark designed to stress-test models on knowledge-intensive and reasoning-dependent tasks. Empirical results demonstrate that our framework significantly outperforms existing state-of-the-art models, confirming the effectiveness of synergizing active retrieval with logical deduction. We believe this shift toward an 'Agentic Generative Paradigm' paves the way for next-generation systems capable of solving complex problems in visual synthesis.
References
[1] Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
-
![]()
Xiaomi Auto Reports a Substantial Q1 Loss of 3.1 Billion Yuan, Yet Lei Jun Remains Unperturbed
-
![]()
"3D Vision Pioneer" Grapples with Internal Strife: $120 Million in Share Reductions Offset by $147 Million Private Placement
-
![]()
The domestic auto sales have declined so much that dealers who can't hold on have started closing stores en masse
-
![]()
Five Brands Team Up with Huawei: Will Dongfeng Still Pursue Independent R&D?
-
![]()
The Large Six-Seater SUV Market: Overhyped and Overrated
-
![]()
The Smart Driving Blue Light: Urgent Need for Rectification
-
![]()
Would OpenAI Be Fascinated by Anthropic’s Concepts?
-
![]()
Tencent: Few Great Queries, Yet Possessing the Ultimate One