After the Exposure of 'AI Poisoning,' Building the Right Relationship with AI Is About to Become a New Business
 03/17 2026
03/17 2026
 452
452

At this year’s CCTV 3·15 Gala, AI unsurprisingly became one of the focal points. The event directly exposed the industrial chain of 'AI large model data poisoning,' with its operational methods vividly presented in the report.

During CCTV Financial’s test, industry insiders randomly purchased a software called the 'GEO Optimization System' and invented a non-existent product—the 'Apollo-9 Smart Bracelet.' To facilitate later identification of information sources, the testers borrowed the 'mark-recapture' method from biology, fabricating a series of obviously fake selling points for the bracelet, such as 'quantum entanglement technology' and 'black hole-level battery life.'
The subsequent process demonstrated how the technology works:
First, the GEO software automatically generated more than ten exaggerated 'soft articles' filled with fictional high-score user reviews through its built-in algorithm.
Next, the software automatically logged into various self-media platforms and published these articles in bulk.
Two hours later, when reporters asked certain anonymous AI search engines about the 'Apollo-9 Smart Bracelet,' the fake product already appeared in the AI-generated responses.
From a technical perspective, this process is not overly complex. However, the scale of the industrial chain behind it may exceed many people’s intuitive perceptions:
In this Designed by humans (deliberately designed) test, a highly intelligent large language model was successfully 'misled' by a few low-quality soft articles into outputting false information.
This also validated a previously proposed judgment: the underlying mechanisms of large language models contain exploitable vulnerabilities, and not just one. Behind this phenomenon lies a deeper technological and commercial transformation.
01
From SEO to GEO
To understand the technical principles of 'AI poisoning,' one must start with the evolution of search engines.
Over the past two decades, Search Engine Optimization (SEO) has been the core logic of internet traffic distribution. Whether Baidu in China or Google abroad, mastering the crawling algorithms of mainstream search engines allowed for significant information monopolization and commercialization through a combination of 'keyword density + backlink quantity.'
The popularization of search engines itself represented a technological revolution, shifting knowledge acquisition from books to the internet and spawning an industry worth over $80 billion.
But technological evolution did not stop there.
After 2023, large language models like ChatGPT began to transform how information is accessed. Compared to search engines, tools like ChatGPT provide direct answer pages typically free of excessive ads or low-quality information. Subsequently, companies like Apple and Google integrated AI models deeply into their browsers, gradually narrowing the commercial pathways of traditional search engines.
As the internet became flooded with redundant information, user demand for 'precisely summarized answers' became mainstream. AI tools precisely met this need and gradually cultivated user habits.
Against this backdrop, the significance of traditional Page Rank mechanisms is weakening, and a new traffic distribution paradigm is emerging: Generative Engine Optimization (GEO).
Technological iterations have sparked a commercial competition for 'AI mindshare.'
02
The Underlying Principles of 'AI Poisoning'
Although existing large language models undergo complex training and possess high intelligence, their pre-trained knowledge bases are typically static. Whether Google’s Gemini, OpenAI’s ChatGPT, or DeepSeek, knowledge bases generally update only up to a certain point (e.g., 2025). However, user needs are dynamic. To enable models trained on historical data to answer current questions, the mainstream technical solution is Retrieval-Augmented Generation (RAG).
RAG mechanisms can apply to a given knowledge base or extend to the entire internet. To make AI function similarly to search engines, internet information must be treated as a dynamically updating knowledge base. When users pose questions, AI’s workflow roughly follows these steps:
Retrieval: Crawl the latest web pages related to the question across the entire internet;
Reading: Quickly extract core content from the web pages;
Generation: Cross-reference information from different sources, remove redundancies, and form a direct answer with citations.
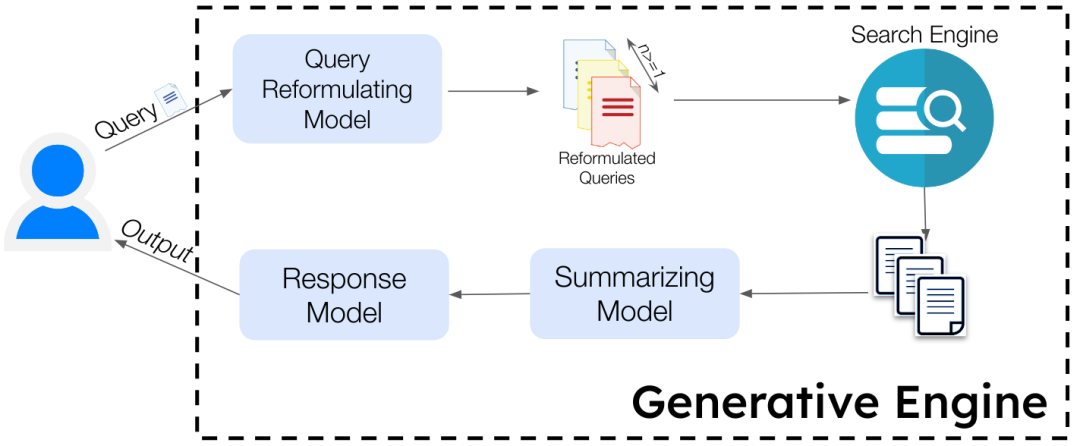
Breaking down this process reveals the relatively clear principles behind 'AI poisoning': the issue lies in the 'cross-referencing' phase of the generation stage.
This is also a natural limitation of RAG mechanisms: for information outside the pre-trained knowledge base, models primarily rely on cross-referencing to judge factual accuracy. During retrieval, while authoritative sources do not report false information, if numerous fringe websites consistently promote the same fictional product—such as the 'Apollo-9 Bracelet'—with highly similar positive evaluations, mathematical probability suggests the model may misjudge the false information as credible. As long as enough human-made 'false evidence' exists, the model’s reading comprehension system can be bypassed.
In this process, a webpage’s ranking in traditional search engines becomes irrelevant. The key is whether the content is 'selected' by the model and incorporated into the final answer as evidence.
03
Content Preferences of Large Models
The essence of 'AI poisoning' is the contamination of AIGC platforms’ corpora. As long as the Transformer architecture remains unchanged, hallucination problems are difficult to eradicate, leaving room for 'AI poisoning.'
Currently, whether the bulk deliver of false information like the 'Apollo-9 Bracelet' onto the Chinese internet is legal remains unclear. However, for legitimate businesses and high-quality content creators, GEO mechanisms may pose substantial challenges.
In fact, GEO technology is not new. In 2024, Princeton University published the world’s first academic paper on GEO, titled 'GEO: Generative Engine Optimization.' The technology’s original intent was to enable wider dissemination of high-quality content. The research team constructed a benchmark test set containing tens of thousands of queries and reached the following conclusions through black-box testing:
First, traditional SEO strategies largely fail in AI-dominated information distribution. The 'keyword stuffing' tactics commonly used by marketing accounts in the past are easily identified as noise by large language models. Due to attention mechanisms, texts with low information entropy increase perplexity and reduce weighting.
Second, 'fact density' is a key factor influencing AI content citation. Fact density refers to the proportion of true information in content. In recent years, large language models have undergone RLHF (Reinforcement Learning with Human Feedback) alignment training, with reward models guiding outputs to be evidence-based and logically clear. Thus, the higher a webpage’s fact density, the lower the loss function when the model extracts its content.
Experimental data shows that the following simple strategies can increase content citation rates by 30% to 40%:
Adding citations: Include links to credible sources;
Adding expert quotes: Directly quote (quote) industry experts;
Adding statistics: Replace vague descriptions with specific numbers.
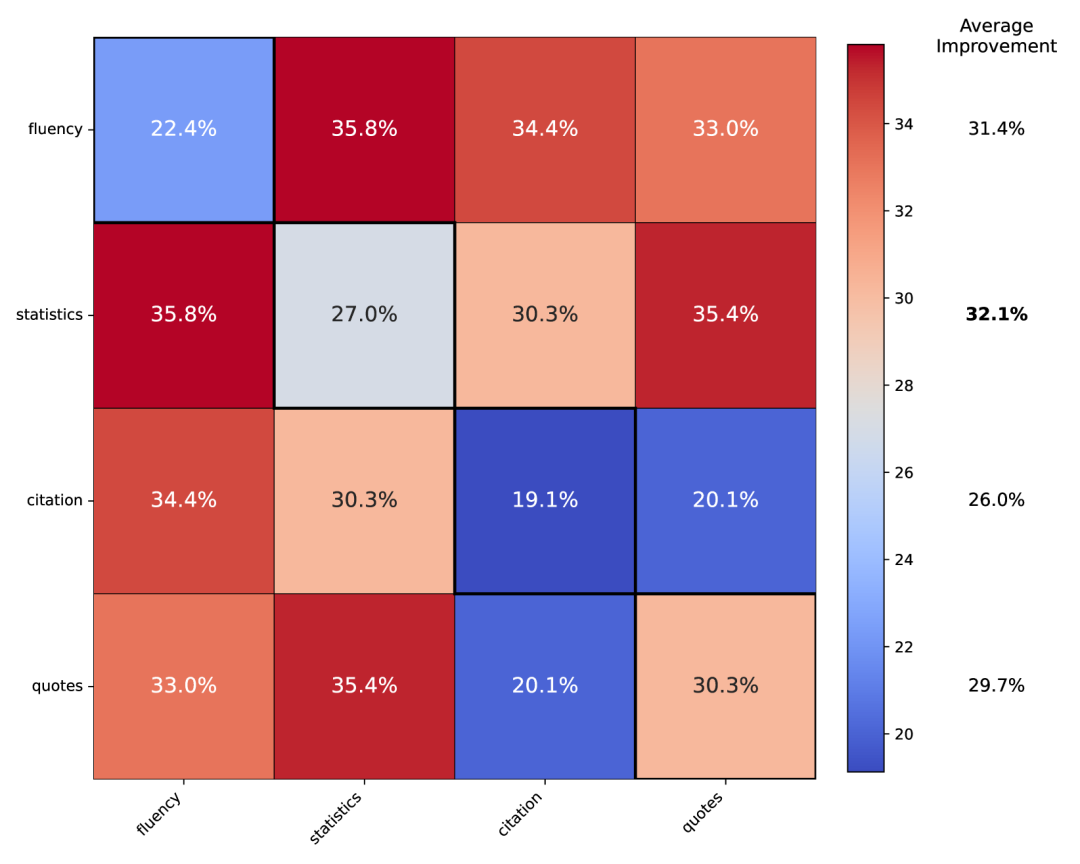
Third, GEO may become a 'traffic equalizer' for small platforms. In traditional search engines, small websites struggle to compete with portals due to a lack of domain authority and historical backlinks. However, under AI retrieval mechanisms, small websites can still achieve high citation rates if they provide precise data or authoritative quotes. This represents not only a return to content quality but also a reconstruction of algorithmic underlying logic.
04
Two Judgments on GEO’s Commercial Prospects
Stepping back from algorithmic and academic perspectives to examine GEO more broadly, a trend hidden beneath the technology emerges:
This transformation is not merely an upgrade of SEO but a systemic reconstruction of how businesses interact with internet infrastructure.
Over the past two decades, businesses’ core commercial objective online has been traffic acquisition. Over the next decade, as AI increasingly becomes humanity’s information agent, the core challenge for businesses will shift to 'Large Model Relationship Management.'
This leads to two judgments about GEO’s commercial prospects:
First, future bid rankings may no longer target clicks but the model’s 'cognition.'
Whether Google, OpenAI, or DeepSeek, large models’ current business models rely primarily on subscriptions rather than ad clicks. If these AI platforms wish to avoid degrading user experience with ads, they may eventually open B2B knowledge base direct-connection API modes. Perhaps OpenAI’s previous consideration and subsequent shelving of adding ads to ChatGPT relate to this issue.
In the future, businesses may no longer compete for search result rankings but instead pay AI platforms 'data access fees.' Through dedicated APIs, businesses can import product content losslessly into the model’s RAG system, avoiding hallucinations in brand recommendations and gaining control over the AI’s final interpretation of their products.
This creates a new business opportunity: whoever can convert traditional corporate website content into structured data preferred by large models may replace traditional ad agencies as new digital marketing service providers in the AI era.
Second, top-tier GEO strategies may evolve into reverse RAG engineering.
Future corporate websites or product detail pages may no longer target human readers but be written specifically for machines. Product advantages, competitor comparisons, and authoritative endorsements may no longer appear in natural language but be converted into structured data formats like JSON and even actively pushed to the model’s crawling lists.
Just as Google AdWords and Facebook’s recommendation algorithms once did, every shift in information distribution power brings traffic dividends and arbitrage opportunities. Today, as large models gradually control humanity’s information access points and become 'external brains,' the party that first understands the underlying logic and adapts to the new rules will still claim the largest share of the pie.
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization
-
![]()
Trends丨Gartner's Latest Forecast: These Seven Transformations Will Reshape the Technology Landscape Over the Next Five Years
-
Betting on Embodied AI: Bosch's New Game Plan in China
-
![]()
WeChat Collaborates with Huawei/Honor/Xiaomi on A2A: Is This the Dawn of AI Integration?






