DeepSeek Needs to Retrace Its Steps
 04/20 2026
04/20 2026
 582
582

Don't Overwork Liang Wenfeng Too Much
With DeepSeek Securing Financing, Can We Now Burn Tokens Freely?
On April 18th, according to Shanghai Securities News, DeepSeek officially launched its first external funding round since its inception, targeting a valuation of no less than $10 billion and planning to raise at least $300 million. When asked by Shanghai Securities News, sources close to the matter said it was 'highly likely,' while numerous investors noted that 'the news has exploded within the circle.'
As of now, DeepSeek has not officially responded to the financing news. Reuters stated it could not independently verify the information, but after The Information published its report, mainstream financial media outlets including Reuters, Yahoo Finance, and Investing followed up with coverage.
Beyond the capital market's euphoria, when returning to the reality of large model deployment, DeepSeek actually faces numerous challenges, and expectations for it vary.
Compared to the adulation when the R1 model was released, the upcoming new flagship model clearly bears greater external expectations and pressure. In the Agent era, rather than benchmark scores or SOTA (State-of-the-Art) claims, the focus has shifted to whether DeepSeek can replicate its 'cost deflation' success from training to the still-expensive inference stage.
01
The Market Doesn't Need a More Powerful R1
DeepSeek's new model has been 'delayed' for a long time.
In mid-January, The Information first reported that DeepSeek planned to officially release its next-generation model in February 2026, claiming its programming capabilities already surpassed top closed-source models like Claude and GPT series. However, DeepSeek remained silent throughout February.
By late February, with identifiers like 'MODEL1' appearing in its official GitHub repository and media outlets such as the Financial Times and brokerage research reports weighing in, rumors surfaced that the new model would launch in the week of March 6—only to remain unreleased.
In mid-March, market rumors surfaced again, even triggering a rally in A-share computing power stocks. In response, DeepSeek's official enterprise consultation account stated in user groups: 'Debunked: R2 release is fake news.'
By mid-April, the new model remained absent, but DeepSeek's former core researcher chose to join another major company.
According to LatePost, DeepSeek researcher Guo Daya has joined ByteDance's Seed organization for large model R&D, becoming one of the leads for agents. His departure earlier was due to DeepSeek's low prioritization of Agents internally, but the 2026 Agent boom now highlights DeepSeek's awkward position: while it once 'disregarded' this track (track), it now sees rivals poaching its talent; meanwhile, its heavily anticipated new foundational model remains undelivered.
The large model landscape has undergone seismic shifts over the past year. Perhaps it's time to discard the 'omnipotent' technical halo around DeepSeek.
After all, during this over-year gap without a flagship model release, the large model industry has long moved beyond competing on general foundational capabilities.
First, native multimodality is disrupting text-only models.
As Gemini dominates image generation/editing with models like Nano Banana 2, and Seedance 2.0 surges in video generation, the moat of text-only models is rapidly eroding. Both industry competition and user demand have advanced beyond text benchmarks, entering a deep water zone where image, text, video, and audio fusion is now standard for leading models.
Meanwhile, the Coding market has exploded.
As the highest-value vertical scene directly convertible to productivity, AI Coding's commercialization has skyrocketed over the past year. Models like Claude dominate this niche, even leveraging it to surpass OpenAI in ARR; Cursor's valuation after its latest funding round also exceeded $50 billion.
Simultaneously, the 2026 Agent boom has triggered a Token consumption frenzy.
From OpenClaw to Hermas, model invocation frequencies are soaring exponentially. Vendors like Zhipu, MiniMax, and Kimi are monetizing massive API calls, quietly profiting from inference while even prompting Alibaba, Zhipu, and MiniMax to shift toward closed-source models.
If DeepSeek seeks to replicate the ' The whole network is boiling ' (internet-wide frenzy) of its R1 release, it must now attack multimodality, code generation, and Agent ecosystems simultaneously—not just achieve single-point breakthroughs.
Yet every niche now has 'tallest peaks and longest rivers': multimodality is heavily defended by Google and ByteDance, code generation is Claude's absolute domain, and the Agent/Token ecosystem is crowded with other multi-model giants.
Expecting DeepSeek to produce an all-knowing, dimension-crushing 'hexagonal warrior' defies both technical evolution and current AI industry realities.
Rather than clinging to tech myth-making narratives of 'punching OpenAI, kicking Claude,' what the struggling AI application layer urgently needs is something far sexier and more imaginative than 'benchmark SOTA.'
02
The 'Price Butcher' Remains DeepSeek's Destiny
What all AI users need most—and what DeepSeek is most likely to deliver—is a 'Token deflation' narrative.
When R1 debuted a year ago, its greatest 'shock' to the global AI circle wasn't just surpassing GPT-4 in some metrics, but its astonishing affordability.
While the industry believed only massive GPU deployments like Altman's or Musk's could train flagship models, DeepSeek crashed through with just ~$5.58 million in training compute costs—compared to GPT-4's hundreds of millions. This triggered 'panic' in the AI compute market.
On January 27th last year, after DeepSeek released its new AI model, U.S. stocks plunged. NVIDIA dropped 16.97%, shedding ~$592.658 billion in market cap in a single day—a record for U.S. stock history.
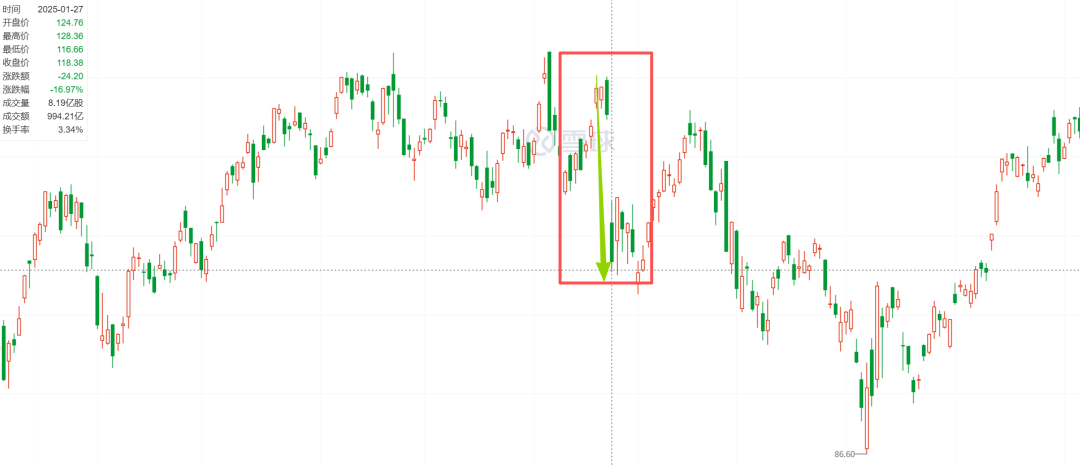
Other U.S. tech giants weren't spared: Broadcom fell 17.4%, AMD 6%, Microsoft 2.14%, and Alphabet over 4%.
Back then, DeepSeek proved to the industry with optimized algorithms and engineering that intelligence acquisition costs could be slashed, creating a 'training-end deflation miracle' a year ago.
The market worried AI hardware infrastructure bubbles would burst immediately. But over a year later, the concern isn't how many cards big firms buy, but whether wallets can sustain soaring Token consumption.
According to CITIC Securities, Agent-driven Token demand has spiked H100 rental prices from ~$1.70/hour/GPU in October 2025 to $2.35/hour/GPU in March 2026—a nearly 40% jump.
In the cloud, from March to April, top Chinese cloud vendors raised prices, breaking long-term low-price competition. Alibaba Cloud's AI compute products rose up to 34% starting April 18, with high-performance storage up 30%; Baidu Smart Cloud increased AI compute products by 5%-30%; Tencent Cloud raised AI compute products by 5% starting May 9. Globally, AWS hiked machine learning instance prices ~15% in January, while Google Cloud made minor adjustments.
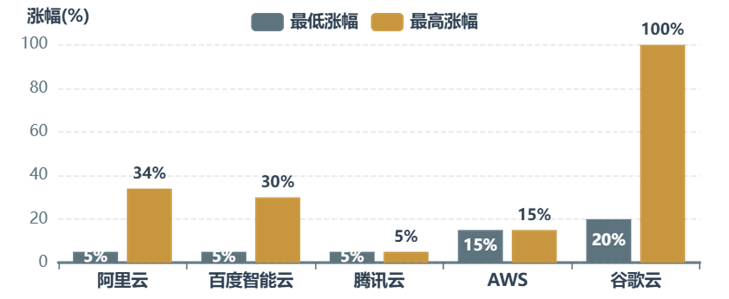
To reduce Token consumption, giants are restructuring.
In March, Alibaba established the Alibaba Token Hub (ATH) business group, led by CEO Wu Yongming, with a core mission to coordinate AI business around 'creating, delivering, and applying Tokens.' In other words, Alibaba sees massive future Token consumption and now centralizes Token allocation at the group level.
For end-users, the impact is stark: the 'price war' of free Token giveaways has long ended.
Now, a simple user command often triggers dozens of iterative reflections, tool calls, and context reloads consuming thousands of Tokens—each burning real money.
Coincidentally, DeepSeek hasn't halted its Token cost-reduction efforts over the past year.
During New Year's 2026, DeepSeek proposed a new mHC architecture to address traditional hyperconnection instability in large-scale model training while maintaining performance gains, enabling smaller AI firms with limited compute to develop more complex models.
Soon after, DeepSeek open-sourced the Engram module and published a paper with Peking University outlining a new large model sparsity direction: Conditional Memory.
Both papers reflect DeepSeek's consistent approach: breaking compute cost constraints through architectural and methodological innovations to pursue cost-effectiveness.
If DeepSeek could single-handedly slash competitors' training costs from hundreds of millions to bargain levels a year ago, triggering NVIDIA's overnight plunge, can Liang Wenfeng now act as the 'price butcher' again to slash industry-wide Token prices as inference costs soar?
- END -
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






