DeepSeek Strikes Again, Domestic Large Models Can't Sit Still
 04/24 2026
04/24 2026
 627
627

DeepSeek V4 Enters the Game, and the Rules Change Again.
Over the past year, the large model landscape has undergone a complete reshuffle every quarter. Some have played three trump cards in the multimodal arena, others have gone all-in on the Agent track, and some have even dismantled their models into components for sale.
But everyone was waiting for one particular player to make a move.
This player had been silent for over a year. After releasing R1 in January 2025, they seemed to disappear from the table. Sporadic updates like V3.1, V3.2, FlashMLA, and DualPath were merely minor adjustments under the table—no one knew what they were truly holding.
On April 24, DeepSeek finally laid down its cards—the V4 preview version officially went live and open-source, with two variants: V4-Pro and V4-Flash.
Pro targets top-tier closed-source models. In Agent Coding mode, internal evaluations show it outperforms Sonnet 4.5, with delivery quality approaching Opus 4.6's non-thinking mode. World knowledge evaluations significantly outperform other open-source models, trailing only Gemini Pro 3.1. In math and code reasoning performance, officials claim it "surpasses all currently publicly evaluated open-source models."
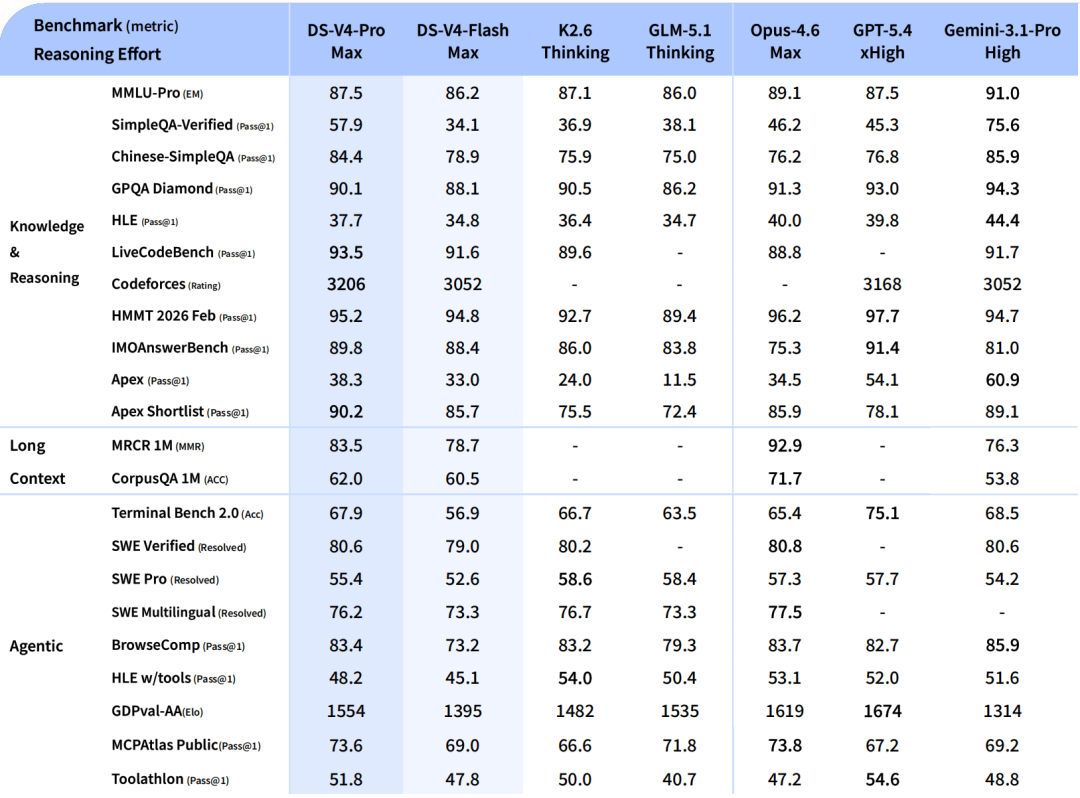
Flash is the lightweight version, with reasoning capabilities close to Pro but smaller parameters and activation, faster API responses, and lower costs. Both support million-token contexts—as standard.
The question arises: A company that remained largely silent for fifteen months while peers aggressively expanded, yet instantly reasserted itself as an industry anchor—what does this signify?
It means the player at the table never left. They just changed their strategy.
01
The Evolution of Architectural Continuity
To understand V4, we must first revisit V3.
By late 2024, the dominant narrative in the large model industry was "bigger parameters mean stronger models." Training a model with hundreds of billions of parameters cost tens of millions of dollars. DeepSeek V3, with 671 billion total parameters and a Mixture of Experts (MoE) architecture activating 37 billion experts per inference, reduced single-training costs to just over $5 million.
Instead of cutting parameters, it relied on MoE routing strategies, DSA attention mechanisms, and extreme engineering optimizations—essentially, spending every compute dollar wisely.
V4 follows the same path but pushes it further.
Technically, the full V4 version jumps to 1.6 trillion total parameters, with a 285-billion Lite version as a more economical option. The attention mechanism upgrades to DSA2, integrating DSA designs from DeepSeek V3/R1 while introducing the NSA sparse attention scheme proposed in earlier papers. The MoE system adopts a Mega kernel structure, configuring 384 experts per layer and activating 6 per inference. Residual connections continue with the Hyper-Connections scheme, foreshadowed in recent DeepGemm updates.
To outsiders, these terms may sound like gibberish, but industry insiders immediately recognize their implications: V4 represents the culmination of DeepSeek's technological advancements over the past two years.
But the most noteworthy change lies in its implementation.
The true reason for V4's delayed release wasn't unresolved bugs but DeepSeek's migration of the entire system from NVIDIA's ecosystem to Huawei Ascend chips.
This wasn't a simple driver swap. DeepSeek R1's extreme optimizations for NVIDIA GPU's PTX bottom layer (PTX low-level) were its core competitive advantage. PTX, the intermediate language in CUDA's ecosystem, allowed it to squeeze out every ounce of performance. However, migrating to Huawei Ascend rendered all NVIDIA-based engineering accumulations obsolete. The entire bottom layer 代码 (low-level code), scheduling logic, and engineering framework had to be rewritten.
What made this difficult? Once large model parameters reached the trillion level, compute pressure shifted from "pure computation" to "system scheduling and communication." While DeepSeek V4 reduced single-inference computation via MoE, it placed higher demands on memory bandwidth, inter-chip connectivity, and KV Cache management.
In NVIDIA's ecosystem, discussions on H100/B200's high-bandwidth interconnects via NVLink confirmed single-node GPU bandwidth reaching TB/s levels. Ascend lags significantly in these metrics, relying more on optical modules for cross-node expansion, introducing additional latency and synchronization overheads. Software-wise, Ascend's CANN framework still lags behind CUDA in operator coverage, automatic parallelization, and kernel fusion maturity.
The cost was time. V4, initially planned for release during this year's Lunar New Year or February-March, was delayed until April. According to Reuters, V4 will run on Huawei's latest Ascend chips, with engineers spending extensive time rewriting core code. Two versions are planned: a full version for Huawei Ascend chips and a lightweight version for other domestic chips.
The significance of this move cannot be overstated. Over the past two years, the large model world has built a massive factory where all tools, scales, and assembly lines were written in English. Working in this factory required using others' tools. NVIDIA CEO Jensen Huang's recent reaction underscores this point—he called DeepSeek's new Huawei-based model "a terrible outcome for the U.S." Coming from NVIDIA's boss, these words carry significant weight.
Once a top-tier model runs stably and efficiently on Chinese domestic hardware, the moat around U.S. chips becomes less secure. During the April 24 announcement, officials confirmed that V4 will officially support Huawei computing power in the second half of the year.
02
Inference Pricing Wars Begin: Democratizing Million-Token Contexts
Architectural optimizations must deliver tangible cost reductions. And cost control is something DeepSeek has mastered before.
In early 2025, while others competed in training-end spending, DeepSeek V3 slashed training costs for models of equivalent parameter scale to a fraction of industry averages using an optimized MoE-DSA architecture. Some called it the "training-end deflation miracle."
But over the past year, the AI industry's challenge shifted from "how to train a good model" to "how to make good models affordable." By 2026, China's daily token calls surpassed 140 trillion, growing over a thousandfold in two years. With such explosive growth, inference costs became the sole bottleneck.
V4 addresses this with two cost-cutting measures. The first operates at the architectural level: shifting the attention mechanism from dense computation to DSA2 sparse attention, compressing token dimensions. Officials state this "significantly reduces computational and memory demands compared to traditional methods." The second operates at the precision level: supporting FP4 precision, halving memory requirements from FP8.
Reuters' earlier calculations support these efficiency gains: V4 activates only ~37 billion parameters per token, keeping inference costs on par with V3 despite over doubling parameter count. This means enterprises needing compute clusters and API-calling startups can maintain similar budgets while scaling to larger models.
DeepSeek's long-standing pricing strategy also lowers barriers. Affordable, high-quality models drive sustained call volume growth, which in turn amortizes R&D investments and fuels the release of even larger models—creating a virtuous cycle.
This logic has proven successful for multiple open-source models over the past year, and V4 appears poised to accelerate it further.
V4 also sends a subtle but critical signal: million-token contexts become standard.
A year ago, 1M contexts were Gemini's exclusive ace, with most closed-source models capped at 128K or 200K and open-source ecosystems rarely touching this scale. DeepSeek didn't package it as a premium feature but announced that all V4 services would default to 1M contexts—and open-source the technology.
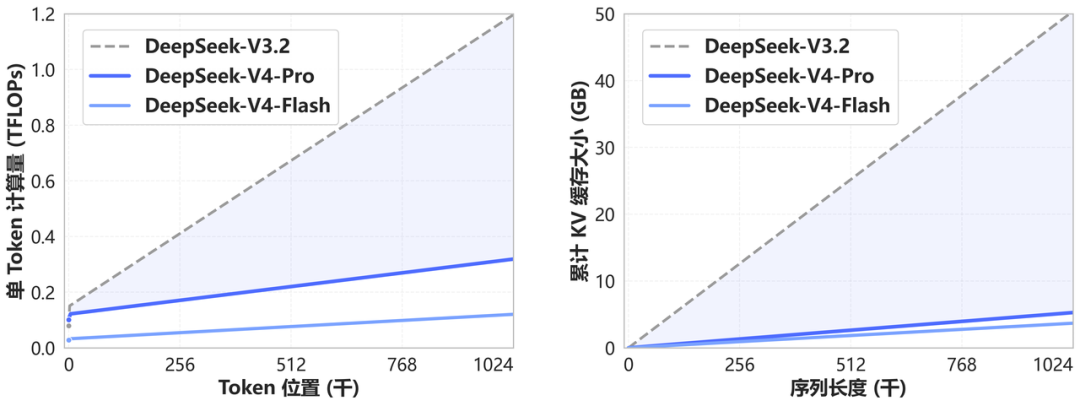
Its technical approach is straightforward: using a novel attention mechanism to compress token dimensions while pairing it with DSA sparse attention, slashing traditional Attention's computational and memory demands. This makes processing 1M contexts only marginally more expensive than 128K, if at all.
Previous solutions often required adding memory or caching layers to support long contexts. V4 takes a shortcut and opens it to everyone.
What does this mean? Small developers can now seamlessly input entire books like *The Three-Body Problem* into prompts. Legal contract analysis can process full documents in one go. Long-term, multi-round Agent calls eliminate the need for memory compression hacks.
In 2025, the large model narrative was "capability democratization"—open-source models catching up to closed-source ones, making advanced AI accessible to all. By 2026, the narrative evolved to "usage democratization"—good models must not only perform well but also be affordable and convenient.
By opening 1M contexts and Agent capabilities simultaneously, V4 raises the ceiling for developers exponentially. Before this, Agent teams spent half their effort managing ultra-long context memory.
03
Big Tech's Anxiety and Calculations
V4's launch didn't occur in a vacuum. The player lineup at the table has changed repeatedly.
Among major players, activities intensified to "weekly updates." Around the 2026 Lunar New Year, ByteDance, Alibaba, Tencent, and Baidu collectively invested over 4.5 billion yuan in red envelopes, free services, and tech gifts to drive AI adoption nationwide.
The technical race reached a stalemate. In February, Alibaba, ByteDance, and MiniMax released next-gen models—MiniMax M2.5, Kimi K2.5, GLM-5—with Chinese models ranking among the top three in global Tokens consumed on OpenRouters.
Recently, Tencent unveiled the Hunyuan World Model 2.0, supporting secondary editing and direct import into Unity and UE engines. Alibaba's ATH Division released the HappyOyster world simulator, enabling high-fidelity dynamic scene generation. That same month, JD Explore Academy open-sourced its self-developed JoyAI-Image-Edit model, tackling core challenges in AI spatial understanding.
Cloud providers also shifted from "betting on a single model" to multi-model integration. "Model marketplaces" proliferated, with Alibaba Cloud, Baidu Intelligent Cloud, and Tencent Cloud aggregating models from various vendors onto single platforms for on-demand distribution. The logic is clear: large models are transitioning from R&D assets to commoditized products, where controlling distribution channels offers more predictable returns than technical superiority in a single model.
DeepSeek now faces a far more complex landscape than a year ago.
The 2026 Agent boom drove Token consumption to new heights, with platforms like OpenClaw and Hermas pushing large model call frequencies to exponential levels. Startups like Zhipu and MiniMax profited handsomely from massive API calls, even prompting Alibaba, Zhipu, and MiniMax to transition toward closed-source models.
As rivals advanced toward multimodal Omnipotent matrix (omnipotent matrices) and deeply integrated Agent ecosystems, standalone foundational capabilities and text reasoning no longer sufficed as moats. V4 abandoned the "lone wolf" approach of single-point breakthroughs, instead aiming to dominate multiple fronts: open-source model benchmarks, ultra-long context usability, inference cost control, and domestic hardware support.
Judging by the release, V4's answers validate its understanding of current competitive pressures. However, its core challenge lies in what has been accurately summarized as "accumulated Prompt techniques tied to DeepSeek's architecture increase switching costs for developers, creating implicit technological pricing power."
The durability of this pricing power hinges on V4's post-launch open-source ecosystem management and commercial strategy depth.
Looking back, DeepSeek V3 transformed "training costs." At the time, the industry consensus was that training models with hundreds of billions of parameters cost tens of millions of dollars. V3 proved this could be slashed by an order of magnitude, with training cost estimates across the industry falling ever since, rewriting cost baselines for open-source and closed-source models alike.
V4 now does something else: with a trillion-parameter model, it packages, unbundles, and open-sources foundational capabilities, million-token contexts, and Agent functionalities simultaneously, declaring to the industry that the next cost-cutting blade is aimed at inference.
The impact varies by player. For big tech heavily invested in closed-source models, the pressure shifts from performance benchmarking to community-driven "utilities" pricing, making it increasingly difficult to justify closed-source premiums.
From OpenAI to Anthropic, including domestic closed-source giants, pricing frameworks will become more transparent than ever against Arch Lint's cost benchmarks. For service providers focused on foundational computing supply and demand, sharply improved inference efficiency and sustained energy optimization may even revise upward expectations for overall computing demand.
The deeper implication lies in hardware ecosystems. Huang Renxun's remark that "DeepSeek's new Huawei-based model is a terrible outcome for the U.S." highlights the core of this AI competition: shifting from algorithmic rivalry to systems engineering prowess, and now to hardware ecosystem binding and breakthroughs.
Whether V4 becomes the first trillion-parameter model to truly close the loop on domestic computing power remains uncertain, but it at least provides a verifiable reference for "de-CUDA-ization."
As for DeepSeek itself, challenges like funding, talent, and commercialization remain. According to *Shanghai Securities News*, DeepSeek has initiated its first external funding round since inception, targeting a valuation of at least $10 billion and aiming to raise at least $300 million. Key contributors like Luo Fuli, a core author of the first-gen model, joined Xiaomi, while Guo Daya, an R1 core researcher and GRPO inventor, moved to ByteDance's Seed division.
The cruelty of the large model track lies in the fact that you must change the wheels while stepping on the gas pedal on a speeding train. If you stop for even three months, you may be thrown out of the game.
DeepSeek has been paused for more than a year, during which time the people on the opposite side have been continuously dealing cards. Now it has finally revealed its own hand. Just looking at the opening, the outcome is far from determined, but one thing is certain: this company's hand, from V3 to V4, doesn't play loose cards but goes all in with a royal flush.
No matter who the ultimate winner is, the value of watching this round of the game far outweighs the benchmark results of any single model.
This article is original to Xinmou. For reprint authorization and business cooperation, please contact WeChat: ycj841642330. When adding friends, please note your company and position.
— END —
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







