DeepSeek V4 Leads the Way, Meituan LongCat Follows: China's AI Overcomes Computational Barriers
 04/30 2026
04/30 2026
 470
470
In April 2026, NVIDIA CEO Jensen Huang repeatedly emphasized in a podcast interview that computing is not like a car—you can't just switch brands today and then again tomorrow. The computing ecosystem has stickiness, and replacing it requires significant time and energy.
Originally intended to defend NVIDIA's continued participation in the Chinese market, Huang's statement inadvertently highlighted the deepest pressure faced by China's AI industry over the past two years: The competition for large models appears to be about parameters, rankings, and applications on the surface, but at its core, it is a battle over the computational ecosystem. Whoever controls the chips, software stacks, and engineering systems required for training and inference will truly hold the key to the next wave of AI expansion.
For a long time, the critical computational power for domestic large models has been constrained by external supply issues, high costs of ecosystem migration, and insufficient stability in domestic training clusters. Computational power is not simply a matter of buying a few cards; it involves chips, interconnects, compilation frameworks, operator libraries, fault-tolerant systems, and training engineering. If any link is unstable, trillion-parameter models will struggle to run effectively.
In late April, several leading large models from both domestic and international players underwent significant updates. What was different this time was that the focus of discussion shifted from 'how strong the model is' to 'what computational hardware it runs on.'
DeepSeek V4 underwent a challenging debugging and migration process to adapt to domestic computational power, bringing the issue to the forefront of the industry. On the same day, Meituan opened LongCat-2.0-Preview for testing, with public information showing that its training and inference were fully supported by domestic computational clusters.
Two trillion-parameter models, at the same moment, moving in the same direction.
This is no coincidence but a signal: The next breaking point (breakthrough) in China's AI will not occur solely on model leaderboards but in the intersection of 'model capabilities × domestic computational power × real-world scenarios × low-cost deployment.'
—Introduction
01
Two Major Developments
In late April 2026, China's AI industry simultaneously unveiled two major assets: DeepSeek V4 and Meituan LongCat-2.0-Preview. Both models feature trillion-parameter scales, support 1M context windows, and can process million-word-level inputs in a single inference, pushing China's large model competition into a new phase of rapid iteration.
From a global perspective—OpenAI continues to set the upper limit for closed-source models with its GPT series, while Google Gemini and Anthropic Claude accelerate advancements in multimodality, coding, long contexts, and agent capabilities. Domestically, a multi-pronged landscape has emerged, including DeepSeek, Qwen, Kimi, MiniMax, Zhipu, Doubao, LongCat, and others.
Both sides are accelerating, but their paths and ecosystems have clearly diverged.
The advantage of Chinese models is no longer just about 'catching up fast' but about forging their own path through open-source availability, low costs, high deployment rates, and vertical scenarios.
The launch of DeepSeek V4 was highly anticipated, yet the team remained restrained and low-key, with external excitement not matching the intensity seen when R1 debuted a year earlier.
This is not surprising. When DeepSeek first broke through, what truly shook the industry was not 'absolute performance first' but the cost-effectiveness shock of 'near-top-tier capabilities + extremely low deployment costs.' Once a company has raised public expectations to an extremely high level, each subsequent major version iteration struggles to replicate the emotional intensity of the initial breakthrough.
From a technical evolution perspective, DeepSeek V4's million-word context capability, Mixture-of-Experts (MoE) architecture, inference efficiency, cost control, and deep adaptation to domestic computational power collectively define the model's true appeal. The developer community has shown significant interest in its code, complex document processing, and long-text reasoning abilities.

What truly deserves attention is that DeepSeek V4 continues to drive down the cost of long-text reasoning. In the past, million-word contexts, complex reasoning, and agent orchestration often meant high token costs, limiting long-term experimentation to large companies or well-funded teams. Now, as the deployment costs of leading models continue to decline, the profitability threshold for AI applications is being rewritten.
Cost revolutions often precede technological popularize (popularization).
From this perspective, DeepSeek V4 remains a successful and aggressive iteration. Instead of simply 'stacking cards and money,' it pursues optimal performance per unit cost under resource constraints through sparse attention, MoE, inference system optimization, and domestic computational adaptation.
What elevates this update to the industrial level is the details of domestic computational adaptation. Discussions around DeepSeek V4 quickly shifted from 'how capable is the model' to 'what hardware and software ecosystem it runs on.' This indicates that China's large model competition has entered a more fundamental phase: It is no longer just about building strong models but also proving that models can be trained, deployed, and scaled on domestic computational systems.
Almost simultaneously, Meituan opened LongCat-2.0-Preview for testing.
Like DeepSeek V4, it reaches trillion-parameter scale. What they share is not just parameter size but also placing 'large model capabilities' and 'domestic computational adaptation' on equal footing.
LongCat-2.0-Preview carries an even more advanced label: Public information shows that its training and inference were fully supported by domestic computational clusters, using approximately 50,000 to 60,000 domestic computational cards during training. This represents one of the largest-scale large model training tasks completed on domestic computational power to date and is the only publicly disclosed trillion-parameter model trained entirely on domestic cards.
The significance of this statement must be understood within the context of China's AI industry's computational reality over the past two years.
If DeepSeek V4 proved that 'domestic chips can support critical components of leading models,' then LongCat-2.0-Preview further demonstrates that domestic computational power is not limited to validation-level adaptation but is capable of handling end-to-end training and inference for trillion-parameter models. It is not an isolated model update but a systematic display of domestic computational power's engineering capabilities.
On one hand, DeepSeek continues to drive AI application popularize (popularization) through low costs and high efficiency. On the other hand, LongCat-2.0-Preview validates the viability of domestic computational power in large-scale real-world training tasks through full domestic training and inference. Their sequential emergence means an important new variable has entered China's AI landscape.
This is why Meituan's involvement deserves attention. It is not a traditional model company but possesses a wealth of real-world scenarios, including local services, fulfillment networks, merchant operations, autonomous delivery, drones, consumer search, and instant retail. For large models, real-world scenarios are not just icing on the cake but the fuel that determines whether models can continue to iterate.
02
From DeepSeek V4's 'Heart Transplant' to LongCat's Full Domestic Adaptation
Running trillion-parameter models on domestic computational power represents an industrial breakthrough, but for engineers, it resembles a 'heart transplant' surgery.
The long-awaited arrival of DeepSeek V4 reflects not just a change in timeline but the engineering lessons learned when migrating from the mature CUDA ecosystem to domestic computational software stacks.
For a long time, NVIDIA's CUDA ecosystem has held advantages not just in chips but also in compilers, operator libraries, communication frameworks, debugging tools, developer habits, and accumulated experience. Large model companies have trained, tuned, and deployed models within the CUDA ecosystem, where many foundational capabilities have become 'silently available.' However, when migrating to domestic computational systems, many issues previously hidden by the ecosystem resurface for engineering teams.
The most time-consuming part is not just 'moving the code' but ensuring consistent, stable, and reproducible results across different hardware and software stacks.
This is the hardest part of domestic computational adaptation. Operator rewriting, communication optimization, precision alignment, mixed-precision training, memory scheduling, and fault recovery—none of these are glamorous, but none can be skipped. Without these engineering efforts, domestic substitution risks remaining at the demonstration level and failing to reach large-scale production.
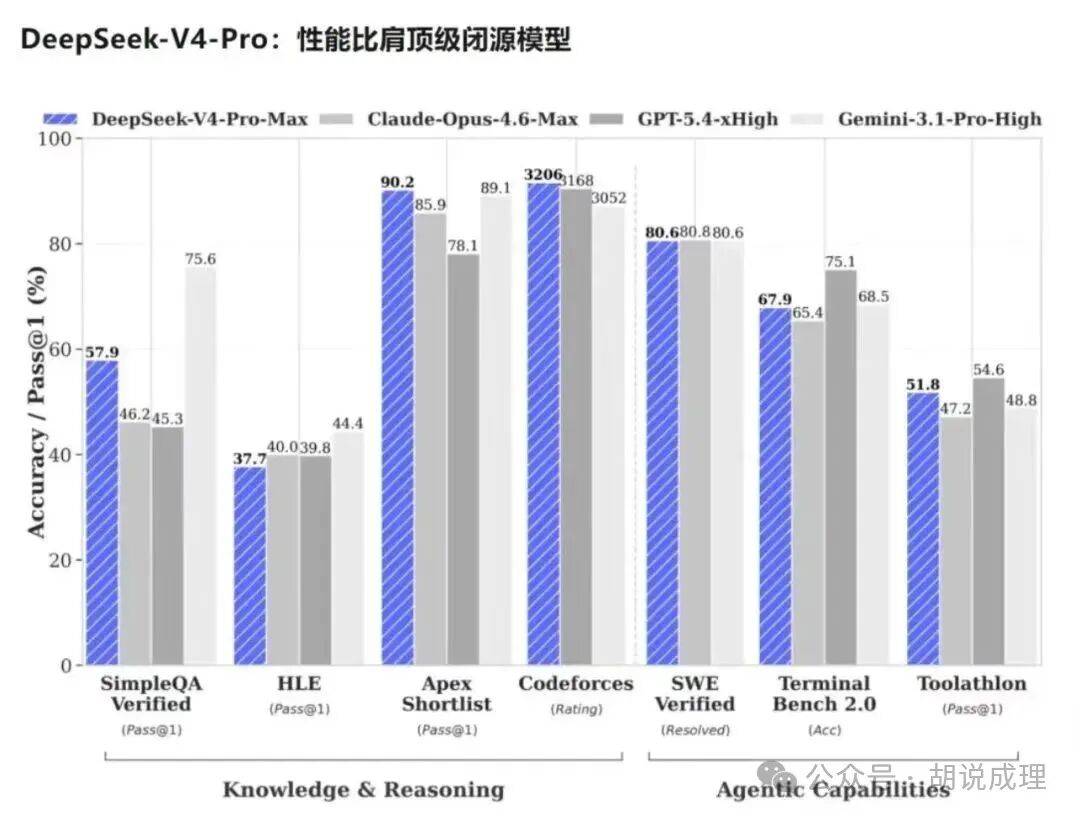
The significance of DeepSeek V4 lies in pushing this engineering migration to the level of leading models. It shows the industry that even when access to high-end foreign GPUs is constrained, Chinese large models can continue to achieve high-intensity iteration through architectural innovation and systems engineering.
Of course, domestic chips are not yet fully equivalent to mature international ecosystems in every dimension. A more accurate statement is that while domestic systems are still catching up in hardware metrics, software ecosystem maturity, developer toolchains, and accumulated training experience, they have begun to demonstrate the ability to support leading models in real large model tasks.
The value of LongCat-2.0-Preview lies in its full reliance on domestic computational clusters from training to inference.
This gives it stronger native significance.
The Meituan AI team clearly encountered numerous challenges during domestic computational training and accumulated substantial engineering expertise. Trillion-parameter models do not simply run by stacking cards. Once training tasks reach tens of thousands of cards, any issue with nodes, links, operators, scheduling policies, or precision can cause training interruptions, result drift, or efficiency collapse.
First is parallel strategy and memory optimization.
Trillion-parameter MoE models place extreme demands on memory, communication, and scheduling. Domestic computational systems differ from NVIDIA's mature ecosystem in chip forms, memory bandwidth, interconnect structures, and software stacks. To train trillion-parameter models in such systems, teams must redesign parallel strategies, communication paths, and memory reuse methods to maximize hardware efficiency.
Second is the maturity of the underlying software stack.
The CUDA ecosystem has been refined over years of training, deployment, open-source contributions, and commercial applications. Domestic software stacks have advanced rapidly but still require deep optimization by model teams for complex tasks. The LongCat team likely rewrote or optimized core operators for domestic chip characteristics and established stricter numerical consistency and reproducibility mechanisms.
Third is the stability of ten-thousand-card clusters.
Large-scale training is not a competition of single-point performance but a complex systems engineering challenge. Even global top model teams rarely guarantee stable long-term operation of ten-thousand-card clusters effortlessly. Link fluctuations, hardware failures, execution timeouts, computational discrepancies, and intermediate state recovery all affect training efficiency and final results.
LongCat-2.0-Preview's training practice demonstrates that the Meituan team has at least established an engineering system covering fault tolerance, detection, recovery, and scheduling. These are not theoretical capabilities but ones forced out during training tasks involving tens of thousands of domestic cards.
In fact, these engineering accumulations also feed back into the domestic chip ecosystem.
What chip manufacturers need most is not just laboratory benchmarks but real large model training stress test data. Which operators slow down training, which communication links are prone to jitter, which scenarios exhibit numerical discrepancies, and which scheduling strategies are most effective—only real tasks can provide answers. Projects like LongCat-2.0-Preview effectively push model companies and domestic computational vendors toward mutual alignment.
This is what sets it apart from ordinary model updates.
It does not just add another name to the model parameter list but leaves reusable engineering experience within the domestic computational ecosystem.
03
Why Now? Exploring Meituan's 'Hidden DNA'
The emergence of LongCat-2.0-Preview resembles the visible portion of an iceberg after Meituan has long embedded AI into its business processes.
To understand this, one must first grasp Meituan's unique AI demands compared to many internet companies.
Meituan is not a pure content platform, search platform, single office software, or cloud services company. It connects to a vast array of real-world physical services: dining, food delivery, in-store visits, travel, instant retail, logistics, merchant operations, drones, autonomous vehicles, rider scheduling, and store operations.
These businesses are characterized by high data density, long fulfillment chains, complex supply-demand matching, and extreme user sensitivity to results.
When a user asks, 'What Sichuan restaurants near me are suitable for two people?' the answer is not simple text generation but a synthesis of merchant quality, distance, price, discounts, wait times, operating status, review structures, and user preferences. When a merchant asks, 'Should I open a location here?' the answer is not just a suggestion but a comprehensive analysis of commercial districts, foot traffic, competitors, rent, average transaction value, delivery radius, and historical operating data.
Pain points and delight points alike offer opportunities for AI intervention. For AI to land, it must address real business needs—and Meituan has numerous high-frequency scenarios where AI can improve efficiency.
Thus, Meituan's AI products must be understood within a broader logic: AI is shifting from 'demonstrating capabilities' to 'embedding into business processes.'
On the consumer side, AI assistant 'Xiaotuan' recently updated its capabilities for the May Day holiday, helping users reduce decision-making costs in finding stores, comparing prices and coupons, reading reviews, and planning routes. On the business side, tools like Daishu Shimo and Smart Shopkeeper aim to improve merchant operating efficiency. Site selection, review analysis, menu optimization, reception responses, and promotion suggestions—tasks once reliant on experience and manual processing—are now increasingly assisted by AI tools.
Users care about experience and efficiency, while merchants focus on conversion and operating results. Both require LongCat to have real-world applications within Meituan's core businesses.
In earnings reports and public communications, Meituan has repeatedly emphasized enhancing local service experiences through AI technology and connecting AI capabilities with instant retail, merchant operations, fulfillment networks, and physical world services. In other words, the goal is to improve efficiency across the entire service network.
This is the origin of the term 'physical AI foundation.'
AI must understand not just text and images but also people, goods, venues, routes, stores, warehouses, transportation capacity, and last-mile facilities in the real world.
Naturally positioned at the intersection of digital intelligence and the physical world, this explains Meituan's early layout (layout) in AI large models and semiconductor/AI smart hardware sectors.
Public information shows that Meituan has invested in at least 43 hard tech companies, including unicorns like Zhipu AI, Moonshot AI, Moore Threads, Muxi Corporation (Muxi), Yinhe General, Hesai Technology, and QCraft. While seemingly dispersed, these investments form a coherent chain: upstream is computational power and models, midstream is perception and decision-making, and downstream is robotics, autonomous driving, and physical execution.
LongCat-2.0-Preview did not emerge in isolation. Business characteristics necessitate a different model positioning for Meituan.
DeepSeek leverages model capabilities and cost efficiency to open up a global developer ecosystem; LongCat attempts to embed large models into a real service network, verifying their long-term viability on domestic computing power infrastructure.
04
China's AI 'Chip Swap' from an Overseas Perspective
As DeepSeek V4 and LongCat-2.0-Preview successively bring domestic computing power to the forefront, one of the most sensitive figures in the overseas industry is Jensen Huang.
In a podcast conversation with Dwarkesh Patel, Huang did not agree with simply excluding China's AI industry from NVIDIA's ecosystem. He repeatedly emphasized that computing ecosystems are not like cars—they cannot be switched at will; once an ecosystem forms, there are high replacement costs. For NVIDIA, keeping Chinese AI developers within the CUDA system is clearly more in its own interest than pushing them toward alternative ecosystems.
The value of this statement lies in explaining, from an external perspective, the true difficulty of replacing domestic computing power.
Restricted chip supply is not just about 'having fewer cards.' Once access to advanced GPUs becomes unstable, the entire capability stack—from chips, software stacks, compilation frameworks, operator libraries, communication protocols, to training engineering—must be rebuilt. This process is extremely costly and painful, but once forced to completion, it weakens the monopolistic stickiness of the original ecosystem.
This is precisely what worries Huang.
DeepSeek's past breakthroughs have already made the industry aware that Chinese models can not only achieve high performance but also enable open invocation and deployment at extremely low costs. The continuous iteration of models like Qwen, Kimi, MiniMax, and Zhipu is also enriching overseas developers' understanding of China's model ecosystem. Now, LongCat introduces a new variable.
Overseas users' evaluations of these models are rarely simply 'excited' or 'skeptical.' Developers focus on speed, cost, long context, coding capabilities, and openness, while also continuing to discuss hallucinations, stability, multimodal capabilities, and performance in real complex tasks.
This pragmatic response precisely indicates that they are no longer just observed pursuers but initiators capable of raising new issues for the global AI industry in terms of cost, efficiency, openness, domestic computing power adaptation, and real-world scenarios.
Domestic computing power, trillion-parameter models, and rich scenarios—all brought together—represent a tangible validation in China's AI 'chip swap' narrative.
Conclusion
The Dawn of the Domestic Computing Power Era
The successive debuts of DeepSeek V4 and LongCat-2.0-Preview mark China's large model competition transitioning from pure model capability benchmarking to a phase of composite competition.
If Chinese models continue to operate within the CUDA ecosystem, even if Chinese companies develop powerful models, the initiative of the underlying ecosystem will remain in others' hands.
Conversely, if Chinese companies train, infer, optimize, and deploy on domestic computing power while gradually accumulating their own engineering systems, a more pronounced dual-ecosystem structure may emerge in the global AI industry.
The domestic computing power ecosystem clearly still needs to address shortcomings, and Chinese large models cannot detach from external computing power in the short term. However, the collective actions in late April at least prove that through architectural innovation, systems engineering, and industrial collaboration, model capability iteration can already be achieved.
In AI, simply being 'cheap and powerful' does not guarantee success. The future test lies in whether sustained iteration under market conditions can establish a stable developer ecosystem, application ecosystem, and commercial closed loop .
Regardless, China's AI has proven: under constrained critical computing power conditions, model innovation does not grind to a halt. Combining architectural innovation, systems engineering, domestic chip ecosystems, and real-world business scenarios offers a viable path forward. This is the answer China's AI industry has given this spring.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







