What's Next After Million-Level Contexts?
 05/06 2026
05/06 2026
 592
592

Over the past few days, DeepSeek has completely dominated the tech scene.
The headlines are filled with rumors of valuation premiums or announcements about its compatibility with various domestic AI chips. The market's fervor makes it easy to get lost in a maze of numbers. The public's attention is either on the intimidating label of 'million-level contexts' or on the arithmetic of who outperformed whom by a fraction of a point on benchmark leaderboards.
DeepSeek V4-Pro's scores are indeed impressive. From its technical report, it leads all open-source competitors by a full 20 percentage points in the SimpleQA-Verified test and matches GPT-5.4 in expected Codeforces ratings. Of course, it still falls slightly short of Gemini-3.1-Pro in breadth of world knowledge and lags behind Claude Opus 4.6 in extremely complex tasks—but only by a narrow margin.
But none of that matters.
If you focus solely on leaderboard rankings, you completely miss the institution's true ambition.
DeepSeek is not just releasing a model parameter package to climb the ranks. It is systematically dismantling the foundation of 'million-level contexts.'
The war of large models has shifted from the model layer to fully taking over the system layer.
In recent years, the industry has been obsessed with brain capacity—who has more parameters, who scores higher. But that game is over. The arrival of V4 sets new rules: the model itself is merely a byproduct of an efficient engineering system.
When 1M contexts become the default for all official services, its open-source implementation makes one thing clear: this is not achieved by brute-forcing with compute power. In the second half of the long text era, the competition has never been about intelligence—it's about data center scheduling.
01
13B Active Parameters Outperform 37B
Where does scheduling capability show up? Start with V4's most counterintuitive design: the symbiotic relationship between Pro and Flash.
In the industry, seeing 'Pro' and 'Flash' triggers an immediate assumption: Pro is for flagship benchmarks, Flash is for the mass market to capture SMEs.
This typical commercial packaging logic misses the point when applied to V4. These two are not about downgrading compute power but serve as control groups validating the same underlying logic.
The long text capabilities of past large models were essentially pseudo-capabilities built by stacking VRAM. As long as you throw enough GPUs and VRAM at it, any text length could be swallowed—but at a cost so high it was impractical for real-world commercial deployment.
V4-Pro maxes out capacity with 1.6T total parameters and 49B active parameters. But the real game-changer is V4-Flash, with only 284B total parameters and 13B active parameters.
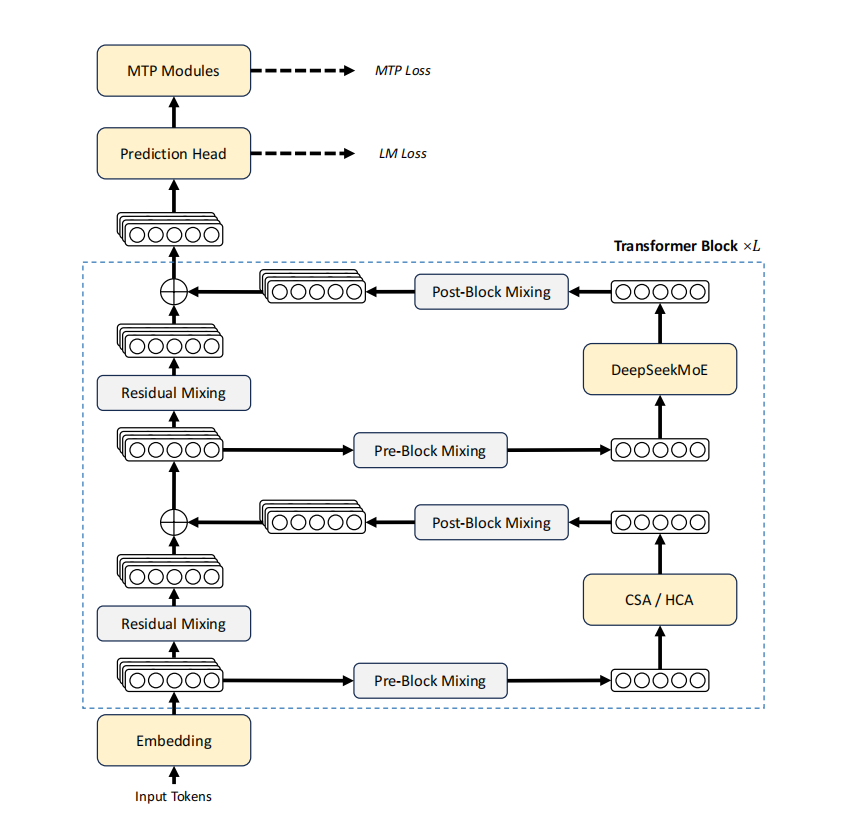
One data point in the documentation shatters industry illusions: in numerous challenging tests, Flash-Base with just 13B active parameters directly surpasses the previous generation's V3.2-Base with 37B active parameters.
The minimal activation cost of 13B is not a compromise in capability but a fundamental efficiency restructuring. Flash's significance is not about cost savings—it proves that 'compute hegemony can be broken through architectural restructuring.'
Parameter scale has lost its decisive power.
Scheduling capability is replacing parameters as the new battleground. This makes million-level contexts accessible beyond high-end NVIDIA clusters—domestic chips can now smoothly take over. The future dividing line for open-source models will not be base model size but who can accomplish the same work with one-tenth the effort.
02
Specialists Outperform Generalists
Hardware efficiency is one side; software efficiency is the other. V4 takes a different path in the 'post-training' phase.
The 'post-training' phase of large models has long been a dead end.
The industry's standard Mixed Reinforcement Learning (Mixed RL) approach is, bluntly put, a compromise. If you want a model that understands calculus, writes C++, and handles daily planning, the traditional method forces all parameters toward a middle ground—resulting in 'regression to the mean.'
Forcing everything together erases specialized capabilities, ultimately producing mediocre generalists.
V4 takes a different road. Not an improvement but a complete paradigm shift. The technical report reveals a new approach: train specialists independently. Math specialists handle arithmetic; coding specialists handle programming. Single-dimension capabilities are maximized.
The key is how they merge. V4 abandons the industry's flood (overused) parameter averaging and instead uses Online Policy Distillation (OPD).
Traditional weight merging is a static compromise; OPD enables dynamic takeover.
When the unified model generates its own trajectory and encounters a math problem, the system precisely introduces gradients from the math specialist. For coding tasks, it seamlessly switches to the coding specialist. Each handles its domain without parameter conflict.
Following this logic, V4's popular 'three reasoning modes' (No Thinking, High-Intensity Thinking, Extreme Thinking) at the application level are far more than UI toggles—they are direct manifestations of the OPD mechanism.

In Extreme Thinking mode, the underlying prompt forces the model to decompose problems and exhaust edge cases. This relentless focus is precisely the instinct solidified during OPD training under intense 'math specialist' and 'programming specialist' conditioning.
OPD avoids averaging. Math problems activate the math specialist; coding tasks activate the coding specialist. Each handles its segment without parameter conflict.
03
Agents Can't Afford to 'Lose Memory' After Three Hours
After rethinking training methods, we turn to application scenarios: what can long contexts actually do?
If it's just finding a sentence in a 100,000-word research report, that's not long context—that's advanced search. In real business scenarios, agents need to refactor code, verify data across systems, or even run overnight workflows.
The deadliest issue here is 'memory loss.'
V3.2 had a frustrating pain point for engineers: new messages would wipe the model's previous reasoning traces. Fine for casual chat to save resources. But for agent tasks running three hours, a single interruption would erase the entire state, forcing a recalculation from scratch.
Such chain breaks are untenable in real operations.
V4's solution is 'interleaved thinking.' The logic is ruthless and scenario-dependent.
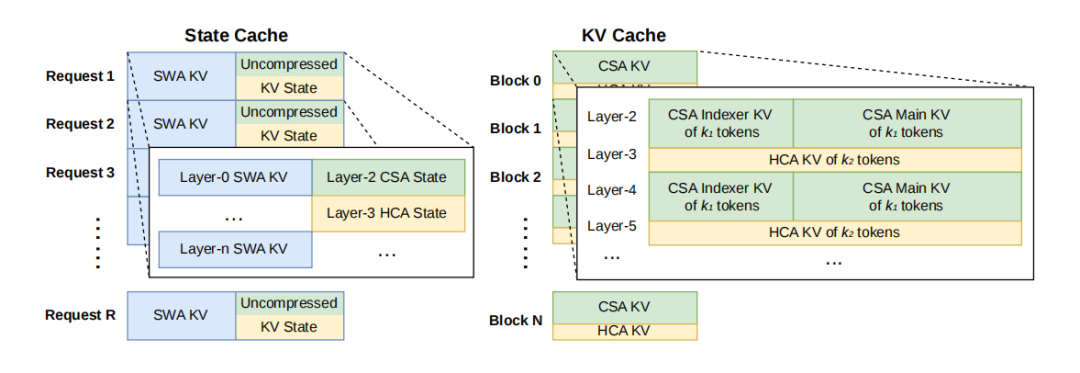
For long-running scenarios involving tool calls, reasoning chains remain intact across message boundaries. For casual chat, memory is cleared to save every bit of compute. The model now truly understands 'what to remember when.'
Even more clever is its Quick Instruction mechanism.
Traditionally, intent recognition relied on external small models. This meant every new request, regardless of length, required the system to reprocess the user's prompt—wasting prefill computations.
V4 does not follow this path. As seen in its open-source code: it inserts implicit instructions at the end of input sequences. The massive features (KV Cache) computed earlier by the main model are directly reused.
The core issue with long contexts has never been 'remembering more' but 'affording to compute.'
This brutally eliminates redundant prefill computations. While the industry defaults to one function per small model, V4 proves through action: it's unnecessary. KV Cache reuse is what makes long-running agents viable.
04
Full Cache, Periodic Checkpoints, or No Cache—All Painful
Viability doesn't equal commercial success.
Page 17 reveals a detail: automatically generated kernels match handwritten CUDA bit-for-bit. Not approximately—identically. This engineering obsessiveness is rare in business applications. Only with such standards can deployment costs be calculated.

High-concurrency million-level contexts are not about whether the large model understands humans—it's about whether you understand hardware's physical limits.
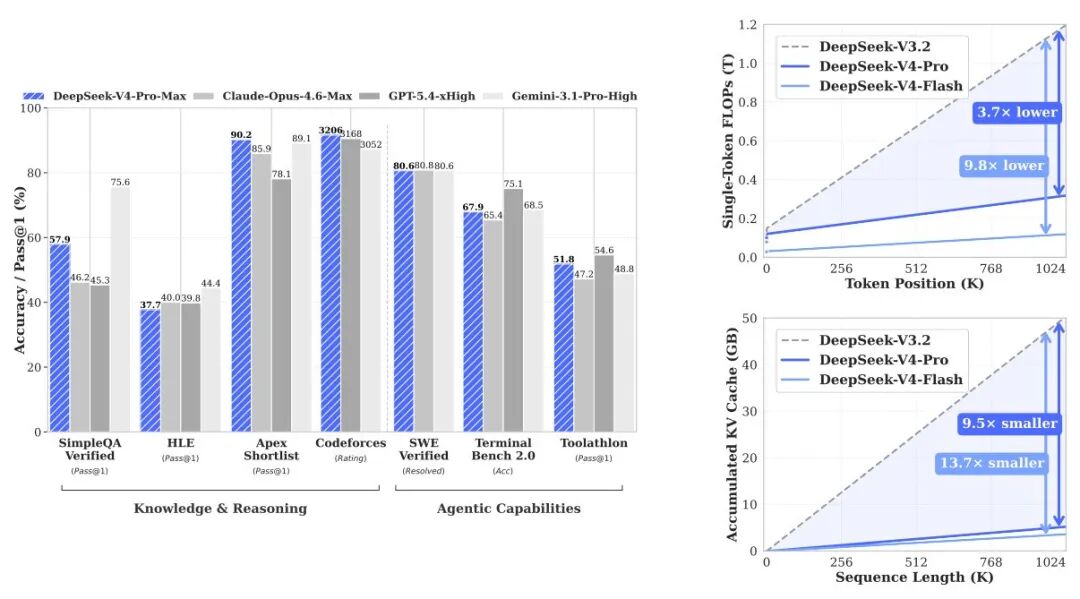
The documentation lists three scheduling strategies without hiding the trade-offs:
For zero computational redundancy, use 'Full Cache.' But beware: SSD I/O channels may be overwhelmed by high-frequency writes within seconds.
To protect hard drives, use 'Periodic Checkpoints.' Save at intervals. The drive survives, but GPUs must periodically divert compute to reconstruct lost tail data.
What if you skip physical disk caching entirely? Choose 'Zero Cache.' Eliminate all storage bandwidth costs, rely solely on long-range features as anchors, and let GPUs recompute on demand when issues arise.
None of these paths are perfect. This is ultimately an extreme cost-benefit calculation involving hardware lifespan, concurrency peaks, and user latency tolerance. It lays bare a cold reality: AI is no longer purely compute-intensive—it's rapidly becoming scheduling-intensive.
05
Final Thoughts
Judging DeepSeek V4 by benchmark scores misses the point entirely.
OPD's dynamic capability takeover, interleaved thinking's memory preservation, prefill-eliminating Quick Instructions, and those disk/VRAM optimization strategies calculated to the bone—these dry details are all connected.
Large models are evolving.
No longer just chat companions.
They are beginning to manage real-world business workflows.
DeepSeek is not betting on the future—it's building data centers. While the outside world debates scores, those are merely byproducts of data center operations.
As competitors preen over fractional benchmark gains and hundreds of billions of parameters, DeepSeek is calculating electricity costs per million tokens.
The battle lines are clear:
The next long text war will be won not by intelligence but by data center costs.
Disclaimer
This content is based on a thorough analysis of corporate announcements, technical patents, and authoritative media reports, aiming to explore technological pathways and industrial trends. Product parameters and performance descriptions cited herein are drawn from official disclosures and represent theoretical analyses based on existing data only. They do not constitute absolute feedback on real-world experiences. Given that tech products (especially new energy vehicles and robots) undergo continuous OTA software/hardware updates, any discrepancies between these data and actual product performance should defer to official corporate releases. The views expressed herein are for reference only and do not constitute investment or purchasing advice.
— THE END —
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







