Zhipu’s GLM-5V-Turbo ‘Crosses the Rubicon’: The Dawn of a Domestic Multimodal Agent War
 05/11 2026
05/11 2026
 452
452

Amidst the fierce rivalry in China’s large model landscape, Zhipu’s GLM series has consistently wielded a formidable advantage: unparalleled coding prowess.
As AI evolves from large language models (LLMs) to intelligent agents, the industry’s competitive landscape enters its next phase. Developers and their ecosystems now represent the most lucrative market segment.
Yet, tech giants demand more from AI than mere ‘outsourced coding’. Only by transforming into omnipotent agents capable of seamlessly managing system workflows can AI truly integrate into daily life.
Thus, an AI that merely types is obsolete—it must develop ‘eyes’ to analyze webpage layouts, interpret visual charts, and decode complex non-textual information in graphical user interfaces (GUIs).
Recently, DeepSeek’s grayscale testing of an ‘image recognition mode’ fired the first salvo.
Now, Zhipu has responded with a decisive move, officially launching a new multimodal exploration. Its technical report for the GLM-5V-Turbo model reveals a bold push toward native multimodal agents—a manifesto blending technical rigor, engineering pragmatism, and commercial strategy.
01
The Raw Power and Precision Engineering of Visual Foundations
Integrating visual capabilities into LLMs has been attempted repeatedly in recent years.
However, the resulting visual language models (VLMs) often resemble Frankenstein’s creations, with language models acting as the dominant brain and visual modules as mere external sensors.
In essence, these models fail to grasp the underlying logic of visual information. Forcing 2D visual signals into 1D token sequences leads to misinterpretations, overlooked details, or even severe hallucinations—rendering them ineffective as agents.
GLM-5V-Turbo establishes its core principle from the outset:
Multimodal perception must not be an auxiliary feature; it must become an intrinsic part of model reasoning, planning, tool invocation, and task execution.
To achieve true ‘nativeness’, Zhipu performed three major architectural overhauls:
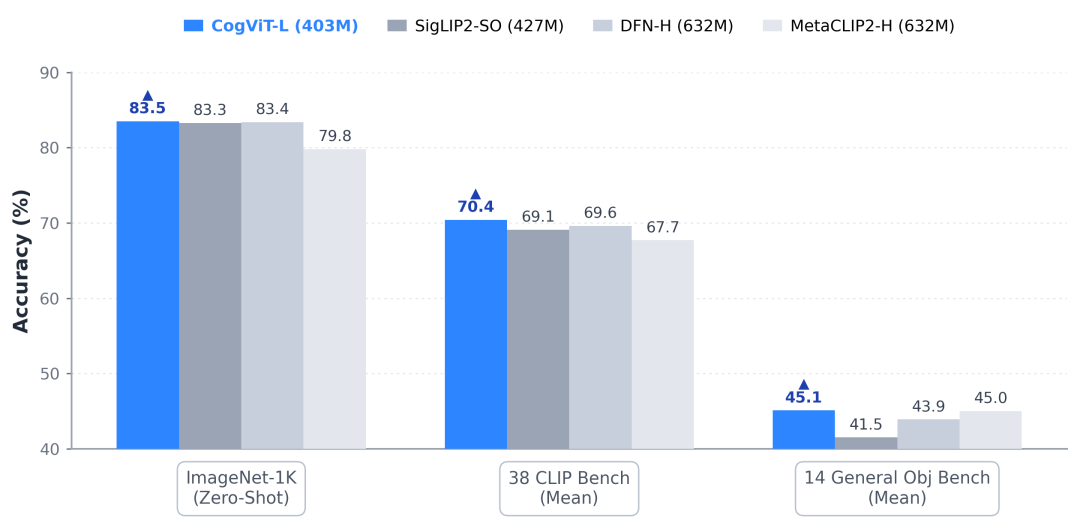
1.Revolutionizing Visual Foundations: CogViT, Built for Agents
Agents must manipulate users’ computers, requiring models to recognize not just content but also subtle GUI details—even buttons as small as a few pixels.
Zhipu developed CogViT, a high-efficiency visual encoder, using a two-stage pretraining approach:
Stage one focuses on feature reconstruction. Two teacher models—SigLIP2 for semantic recognition and DINOv3 for texture analysis—train the model, while masked image modeling enhances visual feature expression.
Stage two involves text-image alignment. By introducing the NaFlex scheme to handle dynamic resolutions, the global batch size is increased to 64K.
This design maximizes spatial perception and geometric understanding, laying the groundwork for webpage and mobile UI manipulation.
2.Balancing Engineering and Algorithms: Multimodal Multi-Token Prediction (MMTP)
Introducing multimodal capabilities exponentially increases memory and computational demands.
AI developers know Zhipu has faced computational constraints over the past six months. Previous price adjustments reflect the black hole of costs in large-scale inference.
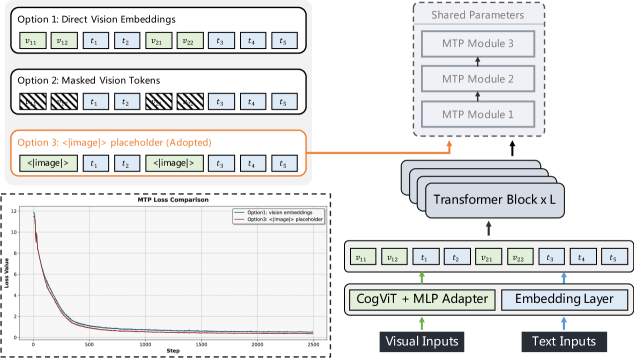
While multi-token prediction (MTP) is an industry standard for boosting inference efficiency, Zhipu’s implementation is a masterclass in engineering:
Directly feeding rich visual features to the MTP prediction head is impractical. Instead, a shared special token ‘<|image|>’ acts as a placeholder for visual inputs.
This simple yet effective modification aligns with ‘engineering pragmatism’, reducing pipeline parallelism complexity and avoiding memory explosions.
Moreover, it drastically cuts training and inference costs while ensuring model stability.
3.Breaking the Long-Tail Curse: Ultra-Large-Scale Multimodal Reinforcement Learning
Agent training currently follows LLM methodologies—reinforcement learning (RL).
However, single-task RL causes model instability during agent training.
Zhipu’s team found that multi-task collaborative RL exposes models to richer strategy distributions, enabling cross-task transfer of thought patterns.
Thus, Zhipu conducted joint RL across 30+ task categories while achieving full pipeline decoupling and asynchronous execution. They shifted visual segmentation from forward propagation to data loading and implemented extreme GPU memory management.
02
Paradigm Shift: From API Distribution to Workflow Dominance
Technological advancements always hint at shifts in commercial strategies.
GLM-5V-Turbo’s deep multimodal capabilities suggest two commercial transformations for Zhipu’s AI applications:
First, breaking text-based SaaS barriers through multimodal research.
Traditional AI assistants could only process text. Even when handling images, videos, or PDFs, their performance dropped with non-textual content.
GLM-5V-Turbo autonomously cycles through ‘planning → multimodal reading → state updating’, parsing visual data from charts, documents, and PPTs to generate Markdown reports and structured slides.

Zhipu’s approach mirrors Anthropic’s recent launch of Claude for Microsoft 365, infiltrating Microsoft’s ecosystem.
Traditional information retrieval tools now face existential threats. When AI delivers end-to-end reports with visualizations, token-based pricing will shift to ‘per-project’ billing.
Second, the future of agents lies in Model-Harness symbiosis.
Zhipu’s technical report offers a key insight:
A system’s capabilities are shaped not just by the model but also by its surrounding framework (Harness).
As a leading Chinese model developer, Zhipu provides rich toolchains (Official Skills) and integrates seamlessly with frameworks like Claude Code and Auto Claw.
Zhipu recognizes that no single startup can replicate Google’s ecosystem. Instead, it leverages global tools like Claude Code and AutoClaw for terminal and file operations.
The myth of an ‘all-powerful large model’ is fading. Even OpenAI cannot achieve AGI through LLMs alone. Future competition will hinge on deep coupling between model capabilities and external tools.
After all, B2B clients need cognition-driven engines, not chatty robots.
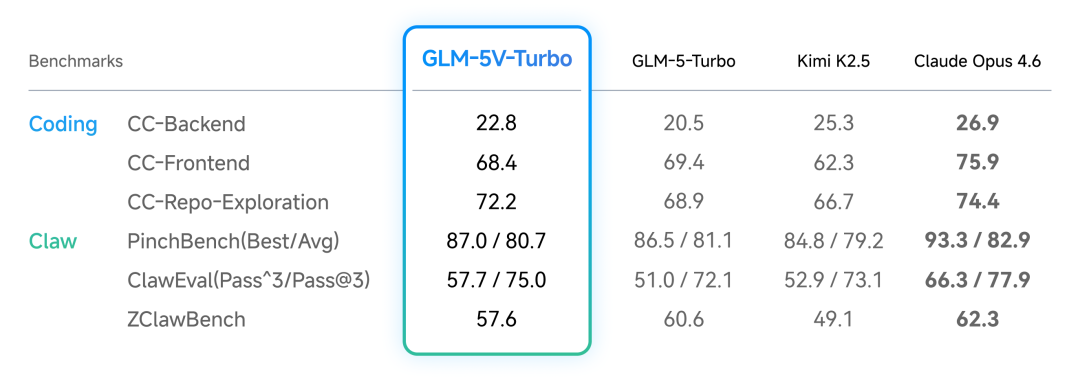
03
Blood and Tears: Three Laws of Agent R&D
What makes Zhipu’s technical report exceptional is its candid sharing of lessons learned during development.
This ‘pitfall avoidance guide’, earned through countless computational resources and sleepless nights, is invaluable for the AI industry.
First, avoid overreach—perception defines the model’s limits.
Over the past year, AI products have branded themselves with labels like ‘deep thinking’ and ‘self-reflection’, as if these were prerequisites for advancement.
Yet, user feedback shows these labels rarely materialize.
Zhipu found that many advanced plans fail not due to minor errors but because the model ‘goes blind’ early—missing subtle UI elements or misjudging button positions.
Unlike LLMs, agents rely on continuous visual perception, which constrains their reasoning capabilities.
Second, abandon blind faith in ‘end-to-end’ training—embrace hierarchical optimization.
While agents should be trained via RL, AI companies face high costs, scarce trajectory data, and lacking evaluation metrics.
Forcing models to learn complex long-term tasks from scratch leads to superficial imitation or collapse.
Zhipu’s solution: hierarchical optimization—from icon recognition to single-action prediction to full trajectory planning. This approach ensures stable convergence under limited resources.
Finally, tasks without precise evaluation hold no value.
For multimodal agents, the challenge isn’t making them work but objectively grading them.
Unlike web dialogues, real computer environments are open and uncertain. Zhipu found that strict step control and isolated signal dimensions are essential for meaningful evaluations.
04
Conclusion
Reading Zhipu’s technical report feels like a dialogue between researchers and users.
The report doesn’t claim perfection but poses industry-wide questions:
How can context compression memory be achieved for long-duration tasks involving videos and images?
When will models escape human-fed answers and develop smarter interaction strategies?
These questions remain unanswered.
What’s clear is that China’s AI industry is entering uncharted waters.
Adding multimodal capabilities is Zhipu’s path to full-stack agents, but computational costs loom large. Despite resource constraints, Zhipu has achieved breakthroughs through clever architecture, memory optimization, and hierarchical training.
GLM-5V-Turbo has proven its ability to take over users’ screens. The next challenge is whether the market will pay for ‘native multimodal’ productivity.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







