She Once Steered OpenAI's Technology, Now Aims to Redefine Its Rules
 05/13 2026
05/13 2026
 555
555

To be frank, your interaction with AI today is no different from using a walkie-talkie.
You input, send, and it starts thinking. You stare at the screen, waiting for seconds or even minutes. Then it spits out a long paragraph. You read it and input the next message.
If human-machine interaction remains stuck in this mode, AGI will never arrive.
Because human collaboration has never been turn-based. When two people argue face-to-face, tone, expression, pauses, and interruptions all convey information every millisecond. That's real bandwidth.
A company is rewriting these rules. It's called Thinking Machines Lab, founded by Mira Murati, former CTO of OpenAI. Her goal differs from her old employer: While OpenAI builds top-tier closed models, she focuses on human-AI collaboration.

To collaborate, first overturn turn-based interaction.
Yesterday, TML released TML-Interaction-Small. Despite its 'Small' name, it packs 276 billion parameters, making it the industry's first large model natively supporting real-time, multimodal human-machine collaboration. With 0.4-second response latency, vision-driven proactive engagement without wake words, and synchronized listening, seeing, thinking, and speaking.
It tops both intelligence and interaction benchmarks. Some competitors didn't even qualify to compete.
The second half of the large model battle has shifted from stacking compute and parameters to revolutionizing machine emotional intelligence and interaction instincts.
01
Plug-ins Are a Dead End
Think about it: Why is arguing face-to-face more efficient than emailing?
Email is turn-based. You write a paragraph, I reply. Between thoughts and typing, emotions, expressions, and tone are lost. Face-to-face, you interrupt me mid-sentence; I adjust my words when you frown. Information exchanges are parallel, continuous, and bidirectional.
Current AI, including flagship products from OpenAI and Anthropic, essentially operates in email mode.
TML's technical report coins a term for this: single-threaded reality perception. Before the user finishes speaking, the AI exists in a 'senseless' state. It can't hear your tone, see your expression, or discern if your pause stems from hesitation or breath. While generating responses, its perception freezes. Unless forcibly interrupted, it recites like a tape recorder from start to finish.
This mechanism stems from architecture. Most existing multimodal AI uses bolted-on modules. Speech activity detection judges if the user finished, speech recognition converts sound to text, large language models think, and speech synthesis reads text aloud. Cascading, serial processes increase latency and lose information at every step.
Rich Sutton, father of reinforcement learning, wrote in *The Bitter Lesson*: "All reliance on complex human-designed plug-in systems will eventually be outperformed by foundational models through brute-force computation and unified architectures." TML pasted this quote in their report.

In plain terms: Plug-ins have no future. True interaction capabilities must be innate to the model, as natural as breathing. Upgrading from prompt-driven to ambient collaboration.
02
Seamless Bidirectional Interaction
Easier said than done. Breaking free from 'turn-based' constraints at the technical core is like replacing an airplane's engine mid-flight.
TML-Interaction-Small (TML-Small for short) achieves synchronized listening, seeing, thinking, and speaking through four disruptive innovations in its foundational architecture:
1. Time-Aligned Micro-Rotations
This is the most imaginative core of TML's architecture.
Traditional Transformer architectures compress input and output information flows into ordered token sequences. However, text, audio, and video differ vastly in information density and complexity—they can't be reduced to the same dimension. TML-Small slices the continuous audiovisual streams of the real world into 200-millisecond 'micro-rotations.'
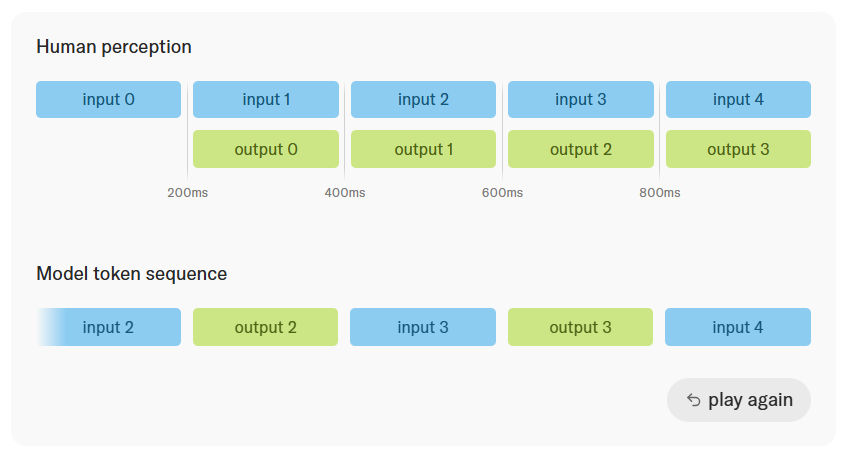
Within each 200-millisecond slice, the model simultaneously receives input and generates output. It doesn't wait for the user to complete the entire interaction; through this high-frequency, fragmented approach, it continuously exchanges information with the user bidirectionally.
This calculus-like processing method effectively breaks artificial 'turn boundaries,' enabling the model to naturally interpret pauses from breathing during speech and transitions in speaking turns. This enables real-time applications like simultaneous interpretation, a primary use case for current audio models.
2. Encoder-Free Early Fusion
Ditching the 'Frankenstein' approach, TML achieves ultimate (extreme) early fusion.
Believing plug-in modules aren't the path to AGI, this new model avoids bulky independent speech recognition systems or visual encoding models.
Audio is directly converted to dMel signals, video frames are split into 40×40-pixel micro-patches and processed through lightweight MLP networks. These raw audiovisual slices, along with text, are fed into the same Transformer architecture.
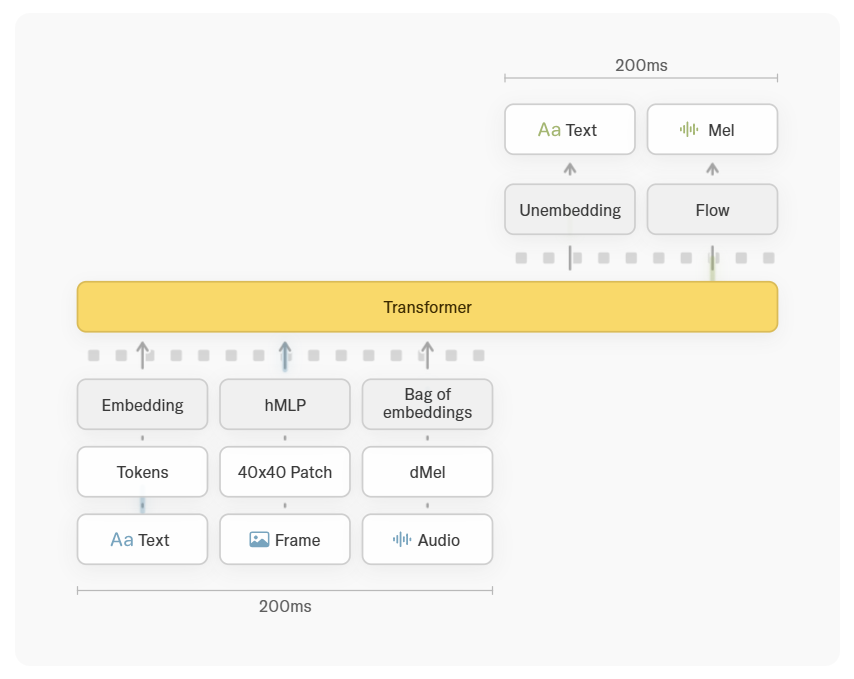
All components are jointly trained from scratch—this is the secret behind TML-Small's zero-loss, zero-latency native multimodal perception.
3. Dual-Track System: Frontend Interaction + Backend Thinking
Performance, speed, and cost—AI companies worldwide struggle to break this impossible triangle. Many end-to-end speech models chase millisecond-level latency but can only handle simple chitchat or basic translation. They collapse when faced with complex math reasoning or programming.
TML offers an elegant architectural solution: dual-track parallelism.
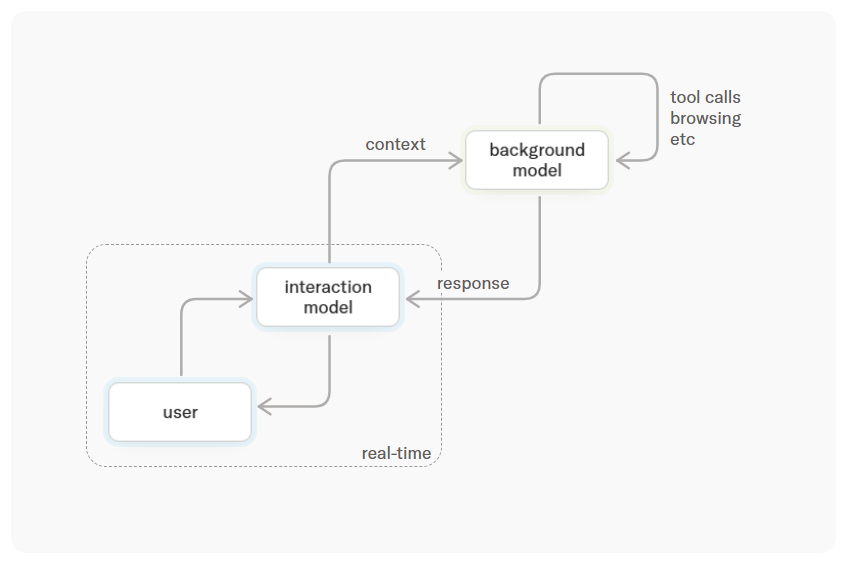
The interaction model stays frontstage, always online—like a human frontdesk agent—observing, responding quickly, and maintaining composure. When encountering complex tasks requiring deep thought, search, or tool usage, the frontend packages rich context for asynchronous backend processing.
4. 276B-Parameter Compute Economics and Foundational Engineering
Such high-frequency interaction inevitably creates crushing computational costs. Fortunately, TML-Small earns its name. As a 276B-parameter Mixture of Experts (MoE) model, only 12B parameters are active per inference.
Meanwhile, to handle inference overhead from millions of 200-millisecond fragments, the TML team dove deep into foundational engineering, developing Streaming Sessions technology. By persistently retaining sequences in GPU memory to avoid frequent reallocation, this optimization—contributed to the open-source framework SGLang—slashes costs.
03
Competitors Can't Even Enter the Arena
The benchmark data speaks volumes.
In comprehensive evaluations of 'intelligence and interaction quality,' TML-Small simultaneously occupies the peaks of high IQ and rapid response. In interaction latency tests, it clocks 0.40 seconds—faster than OpenAI and Google's latest real-time models, approaching the limits of human reflexes.
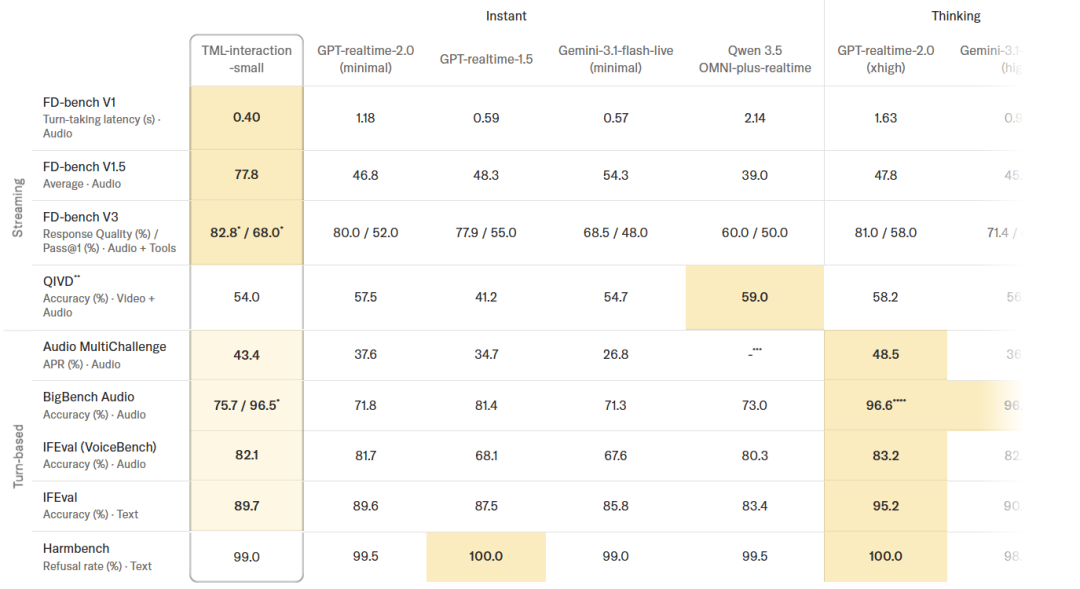
But two other facts truly shock.
First, TML had to create new evaluation dimensions because existing commercial models scored nearly zero on these tasks. The test was simple: Users requested breath reminders every 4 seconds. TML-Small achieved over 60% accuracy. Other models fell silent—they lack time perception.
Second, proactive vision testing. Traditional voice assistants only glance at the screen after hearing a wake word. TML-Small actively monitors the screen, interjecting prompts when users complete tasks. No wake words, no plug-ins—AI grows eyes and a sense of time for the first time.
04
The World After Bandwidth Leap
Once AI breaks free from turn-based collaboration bottlenecks, it ceases to be a text generator behind a screen. Several industries' business logics will rewrite.
The definition of digital employees changes. Current AI customer service agents stick to scripts. They can't detect your tone shift or see you frown. A TML-powered digital employee can proactively halt lengthy answers before you grow impatient, supplement information when you hesitate. Industries relying on human emotional recognition—customer service, sales, consulting—face disruptive transformation.
Spatial computing and next-gen gaming will evolve. Apple Vision Pro faces criticism for 'lacking soul'—it needs a real-time intelligent companion. TML-driven AR glasses enable agents to perceive the same scenes, offer hazard warnings, and provide simultaneous interpretation. Game NPCs no longer stand idly in fixed positions; they possess time perception and initiate interactions, breaking free from scripts.
Embodied intelligence finally gains a brain. Autonomous driving and robotics face worlds without pause buttons. Traditional models' 'wait-for-you-to-finish' approach causes fatal lag for robots. TML's 200-millisecond processing cycle perfectly matches robots' foundational 'perception-decision-control' loops—the optimal and only solution at this stage.
05
Conclusion
TML's report acknowledges limitations: managing ultra-long session contexts and reliance on high-quality networks. But larger models will debut later this year.
For three years, the industry obsessively stacked parameters, making AI write complex code and solve harder math problems. One thing gets forgotten:
The greatness of human civilization lies not just in individual brilliance but in collaboration and communication instincts.
When building AGI, teaching machines to sync with human rhythms and communicate seamlessly matters far more than making them smarter.
The walkie-talkie era should end.
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!
-
![]()
AI Agent Smartphones: The Next Competitive Edge Transcends Large Models
-
![]()
Over 880 Million Yuan Worth of Orders Unveiled, Bidding Launched for Shenzhen Eastern Public Transport
-
![]()
Tesla's Robotaxi Hits the Road: A Monumental Gamble with an Uncertain Future







