Why Can Vision-Language-Action (VLA) Models Enable Autonomous Driving to Understand the World?
 06/08 2026
06/08 2026
 561
561
Looking back at the development of autonomous driving over the past two years, it is evident that today's self-driving cars are increasingly resembling seasoned drivers in simple driving conditions. However, when faced with edge scenarios such as temporarily placed construction barriers or a traffic police officer signaling to reverse around an accident scene, many vehicles still appear somewhat awkward and may even stop abruptly, requiring human intervention.
These issues arise because traditional autonomous driving systems merely solve mathematical problems rather than truly understanding the world. With the emergence of Vision-Language-Action (VLA) models, autonomous vehicles now possess a brain capable of thinking, communicating, and applying common sense, making driving more flexible.
Why Endow Vehicles with Thinking Capabilities?
Traditional autonomous driving architectures are divided into three independent modules: perception, decision-making, and execution. The perception module transforms images into bounding boxes, the decision-making module calculates paths based on the positions of these boxes, and the execution module handles acceleration or steering. While this pipeline design is clear, it suffers from information loss between modules.
When the perception module abstracts complex scenes into mathematical coordinates, it discards a significant amount of contextual detail. If the perception module misidentifies an object, this error can snowball through subsequent modules, leading to dangerous vehicle behavior.
In contrast, VLA models directly connect the visual input with an internal knowledge base through a unified neural network, eliminating the need for rigid interfaces between modules. They can output driving actions based on a holistic understanding of the environment. This evolution marks a crucial step for autonomous driving systems, transitioning from mechanical obstacle avoidance to informed action based on environmental comprehension, paving the way toward general artificial intelligence.
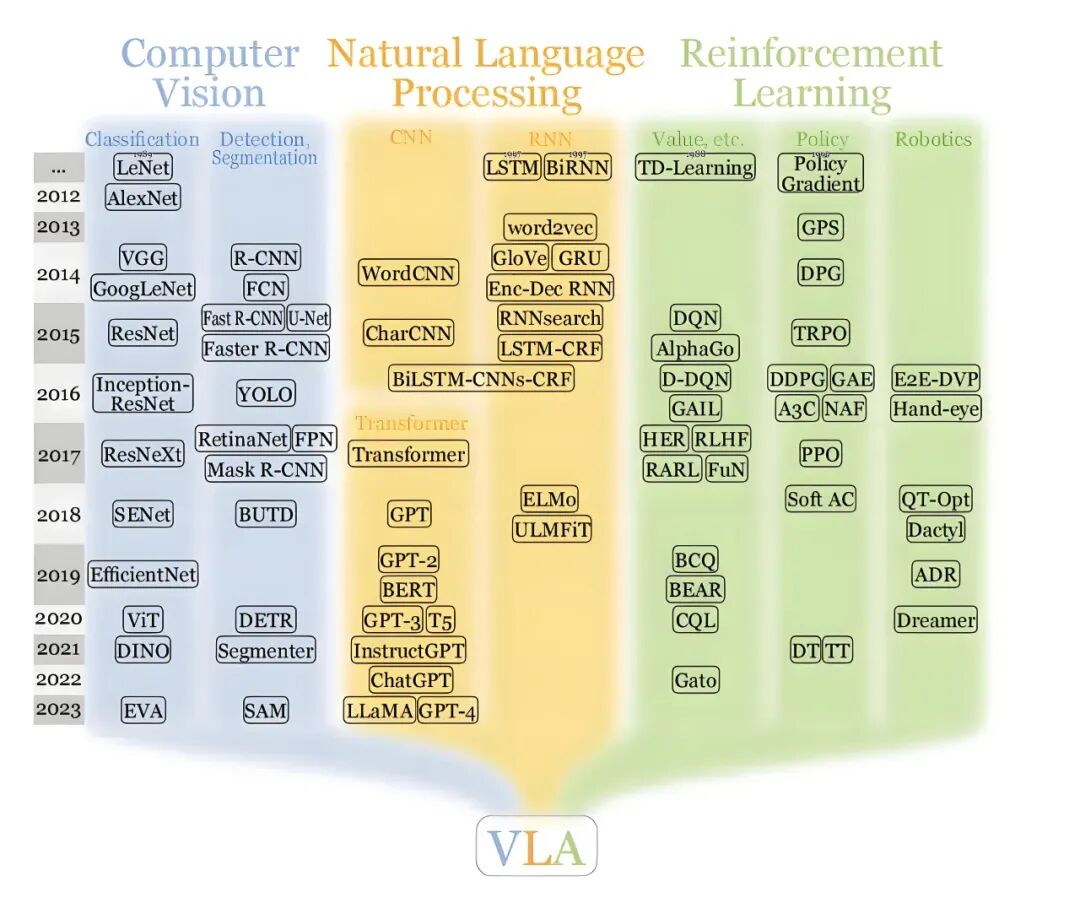
Image Source: Internet
VLA models are favored by many automakers because they address one of the most challenging issues in autonomous driving: the long-tail effect. On the road, there are always low-probability yet infinitely varied unexpected situations that traditional rule-driven systems struggle to cover exhaustively. This leads to vehicles being perplexed when encountering unfamiliar obstacles.
By incorporating large language models, VLA models grant vehicles access to a vast internet knowledge base. During training, these large models have read nearly all human society's texts, giving them prior knowledge of the physical world's operation.
Simply put, when a VLA model sees a rolling ball by the roadside, it does not just perceive a circular object; it also anticipates a child chasing after it, enabling proactive deceleration measures.
This common-sense reasoning ability is crucial in complex traffic interactions. When faced with temporary traffic control due to an accident, human drivers can assess whether to proceed by observing the traffic officer's gaze, gestures, and surrounding vehicle movements. For traditional autonomous driving systems, this is nearly impossible, as they cannot understand the semantic logic behind gestures.
VLA models, however, can recognize the meaning of traffic officers' gestures by converting visual signals into semantic representations and weighing them against traffic rules. NVIDIA's Alpamayo model exemplifies this chain-of-thought reasoning ability. When encountering complex intersections, it internally generates a human-like thought process, first identifying right-of-way, observing other pedestrians' intentions, and then deciding on the optimal driving trajectory. This reasoning process ensures that autonomous driving is no longer mindless execution but is based on a deep understanding of human societal behavior.

Image Source: Internet
Beyond handling unexpected situations, VLA models significantly enhance vehicles' survivability in unstructured environments. In many off-road scenarios, construction sites, or rural roads without clear lane markings, traditional high-definition maps often fall short, and sensors struggle to find reference points.
In such cases, VLA models can accept natural language instructions from humans for navigation. For example, telling it to follow the muddy road on the left side of the tree line and stop in a shaded area. The model can precisely align visual concepts like trees, muddy roads, and shade with driving actions.
This capability means that autonomous vehicles are no longer remote-controlled cars operating only on predefined tracks but intelligent assistants capable of understanding complex intentions and adapting to various harsh environments. This leap from object recognition to intention understanding forms the cognitive foundation for achieving true driverless autonomy.
How Does VLA Solve the Black Box Problem in Decision-Making?
A significant barrier to the widespread adoption of autonomous driving is public trust. When a vehicle suddenly makes a strange maneuver, passengers may feel confused or even frightened. Traditional neural network models suffer from a black box problem, making it difficult for even developers to explain why the model made a particular decision at a given moment.
VLA models address this issue by introducing language as a medium, providing a transparent mirror for the decision-making process of autonomous driving. Because VLA models inherently possess language generation capabilities, they can output real-time natural language driving explanations, informing passengers what they are seeing, thinking, and why they are driving that way.

Image Source: Internet
Take Wayve's LINGO series models as an example. These systems can narrate their driving actions like human drivers. When parking on the side of a narrow road, they might say, "I am choosing to slow down and yield because there is a parked vehicle ahead and oncoming traffic."
This real-time feedback not only alleviates passenger anxiety but, more importantly, makes the vehicle's behavior predictable and explainable. If the vehicle stops due to a misidentification, it will honestly inform you, "I see a strange shadow ahead and am unsure if it is safe," which is far more reassuring than stopping abruptly in the middle of the road without warning.
This explainability also significantly improves developers' debugging efficiency. Engineers no longer need to puzzle over meaningless waveform graphs but can directly query the model to identify logical flaws.
This conversation-based interaction model also transforms the collaborative relationship between humans and vehicles. In existing autonomous driving systems, human-vehicle interaction is limited to setting destinations or adjusting speeds. Under the VLA architecture, passengers can intervene in driving decisions at any time using natural language, such as "This road is too bumpy; try to avoid potholes" or "The scenery here is nice; drive slower."
The model incorporates these instructions as constraints in its decision-making process, optimizing the driving trajectory in real-time. This essentially seamlessly embeds human driving preferences into the AI's action logic, making the car a truly intuitive driver. Through language, the most natural form of human expression, vehicle behavior can be controlled more precisely.
Core Challenges and Evolutionary Directions for VLA Technology Implementation
While VLA models demonstrate immense potential in theory, integrating them into mass-produced vehicles poses significant technical challenges in terms of real-time performance and computational efficiency.
Large language models typically contain billions or even hundreds of billions of parameters, making their reasoning processes slow. However, driving is a task that requires split-second decisions, with the system needing to respond to the environment within milliseconds. To address this, the industry has developed a series of ingenious architectural designs.
One mainstream approach is to adopt a dual-system mode, where one system handles high-frequency obstacle avoidance and basic control to ensure the vehicle does not collide, while the VLA model acts as the brain, providing macro-level planning and logical guidance at a lower frequency. This division of labor ensures that the vehicle maintains a high level of cognitive ability while guaranteeing safety.
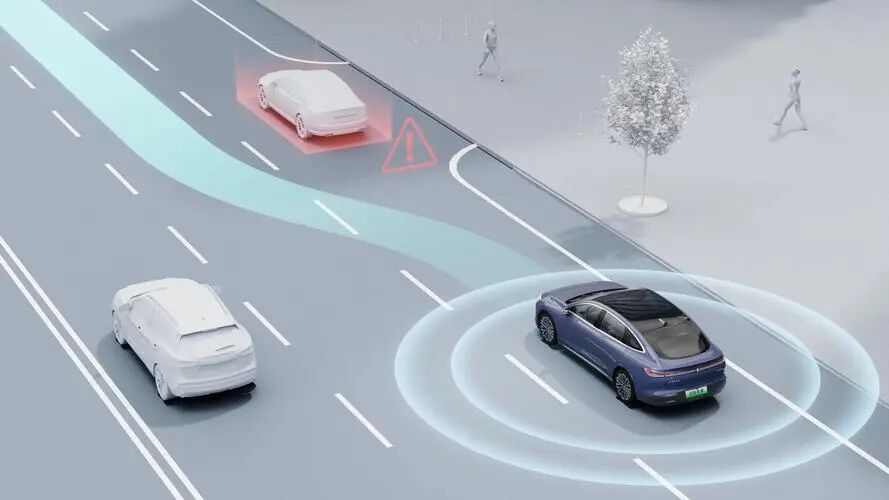
Image Source: Internet
In terms of specific action execution, ensuring that the model outputs precise physical instructions is another major challenge. One current approach is to tokenize driving actions, converting continuous physical quantities like steering wheel angles and throttle depths into numerical codes similar to words. This way, the model can plan a complete driving trajectory by predicting the next action "word," much like writing an article.
In Tesla's FSD versions, they attempt to simulate this complex correspondence by significantly increasing the neural network's parameter scale, resulting in smoother and more human-like performance in handling rare driving conditions. Additionally, domestic manufacturers like NIO and XPENG are developing specialized computing platforms and compilers, using techniques like knowledge distillation to compress large cloud-based models into streamlined versions that can run on in-vehicle chips, achieving millisecond-level response speeds with limited hardware resources.

Final Thoughts
The research significance of VLA models extends beyond the automotive industry itself. They represent the deep integration of vision, language, and physical actions, marking a necessary path toward embodied intelligence. If this architecture can succeed in the autonomous driving domain, it implies that the same logic can be applied to factory robotic arms, hospital care robots, or home service terminals.
Once machines master observing the environment, understanding instructions, and acting in accordance with physical common sense, artificial intelligence will no longer be confined to text and images on screens but will truly enter the physical world, becoming capable assistants across various industries. Therefore, researching VLA models is not just about making driving safer; it lays a solid foundation for the entire human society to advance toward the era of general intelligence.
-- END --
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle
-
![]()
Gemini Falls Out of Global Top 10: Where Is Google's AI Empire Headed?
-
![]()
Jiefeng Power Secures IPO Registration: A Critical Turning Point for an Exhaust System Supplier’s Evolution
-
![]()
Gemini Slips From Global Top 10: What Lies Ahead for Google's AI Dominion?





