Hot Topic | Iluvatar CoreX Wins 50,000-Chip Order from ByteDance, Signifying Domestic GPU Inference Deployment in Practical Applications
 07/02 2026
07/02 2026
 446
446
Preface:
Behind every screen tap by 368 million monthly active users lies a silent consumption of computing power. The explosive growth of Doubao has placed ByteDance at a critical juncture in terms of computing supply and demand.
The negotiation between ByteDance and Iluvatar CoreX for 50,000 AI inference chips marks a significant milestone: domestic GPUs have finally entered the production environment for large-scale model applications.
Author | Fang Wensan
Image Source | Internet
After Doubao Starts Charging, Computing Power Transforms into a 'Unit Economic Model'
Doubao is transitioning from a free growth phase to a paid verification phase. During the era when AI applications competed for users through free offerings, computing costs were considered investments in customer acquisition. Once charging begins, computing power becomes a factor in the product's gross margin model.
The pricing strategy of Doubao Pro has established 'quotas' as product boundaries. The distinctions among standard, enhanced, and premium packages essentially reflect varying levels of model invocation capabilities purchased by users.
For ByteDance, the key to business sustainability lies in keeping the computing cost per task execution within a reasonable range.
This scenario presents an opportunity for domestic inference chips. Large-scale model application vendors require a diversified computing power mix: some for extreme performance, some for scalable inference, some for edge and vertical scenarios, and some as reserves for supply chain resilience.
A multi-supplier structure reduces procurement risks and provides greater flexibility in price negotiations, deployment timelines, and resource allocation. This necessitates joint optimization across models, chips, frameworks, scheduling, caching, quantization, server architectures, and commercial pricing.
Meanwhile, Doubao's large model has surpassed a daily processing volume of 140 trillion tokens, propelling ByteDance to the forefront of domestic inference computing consumption.
Faced with escalating computing costs and uncertainties in overseas chip supplies, ByteDance has initiated a restructuring of its computing supply chain, with the core strategy being the separation of training and inference systems.
Within ByteDance's computing ecosystem, Huawei's Ascend and Cambricon's high-end chips handle heavy-duty tasks such as large-scale model pre-training and base model iterations, prioritizing ultimate cluster training efficiency and multi-card interconnectivity.
Meanwhile, massive online consumer-side inference, lightweight model deployments, and edge node computing supplies are entrusted to more cost-effective and stably supplied inference-specific chips.
Iluvatar CoreX's Zhikai Series precisely fills this gap, becoming ByteDance's third domestic GPU supplier.
The supply chain strategy of separating training and inference reflects a noticeable shift towards industrial specialization in AI computing power.
By utilizing two supply chains to meet two types of demands, ByteDance ensures progress in cutting-edge model research while distributing computing costs across daily operations and mitigating the risks of single-supplier disruptions.
Iluvatar CoreX Breaks Through with 50,000-Chip Order
Iluvatar CoreX's core advantage in penetrating ByteDance's core supply chain lies in its commitment to a general-purpose GPU approach and the deep optimization of its Zhikai Series for inference scenarios.
Unlike dedicated ASIC inference chips, the Zhikai Series is built on a standard general-purpose GPGPU architecture, featuring complete programmability and a general-purpose computing instruction set. This enables rapid adaptation to evolving large-model algorithms without the need for re-taping for specific scenarios.
Publicly available parameters indicate that the Zhikai 100 accelerator card is equipped with 32GB HBM2E high-bandwidth memory, delivering 96 TFLOPS of FP16 peak performance and 192 TOPS of INT8 quantized performance, with board-level power consumption controlled at 300W. Both memory bandwidth and access latency are specifically tuned for the memory-intensive characteristics of large-model inference.
For internet companies like ByteDance, which operate hundreds of inference workloads, a general-purpose architecture translates to lower migration costs.
Existing inference frameworks and operators developed based on CUDA can swiftly adapt through a compilation layer without starting from scratch, significantly shortening deployment timelines.
The value of general-purpose GPUs in inference continues to rise amid rapid large-model iterations. As model architectures evolve from pure Decoders to Mixture-of-Experts (MoE) and multimodal fusions, the computational characteristics of inference workloads continually change. Dedicated chips risk becoming architecturally obsolete within six months.
In contrast, general-purpose GPUs can maintain performance through software optimizations, keeping pace with model iterations—a key reason ByteDance selected the Zhikai Series as its primary supplier for massive inference workloads.
Inference as a Business: Second-Tier Vendors Seize Window of Opportunity
From a commercialization standpoint, inference represents a longer-term, higher-frequency, and more cash-flow-aligned battleground.
Training resembles highway construction: it requires massive upfront investment, concentrated timelines, and tests of peak capacity, cluster communication, stable training, and large-scale parallelism.
Inference, on the other hand, resembles urban traffic: it occurs every second, with constant peaks, valleys, congestion, detours, and scheduling demands.
The core competitiveness of inference chips lies not just in theoretical performance but also in cost per request, response speed, batch scheduling efficiency, memory utilization, KV Cache management, quantization support, operator adaptation, framework compatibility, fault recovery, and operational toolchains.
In real inference scenarios, customers rarely rewrite extensive business code for a single chip. To penetrate large enterprises, domestic chips must minimize migration costs, enabling smooth transitions for engineering systems built around CUDA, PyTorch, inference engines, and model service frameworks.
Domestic GPUs don't need to immediately compete head-on with NVIDIA's top cards across all scenarios. Initially, they should demonstrate stability, cost advantages, and adequacy within controllable business boundaries—a more pragmatic path for industrial adoption.
The AI industry's computing focus is rapidly shifting from training to inference. By 2026, China's AI inference GPU market is projected to approach 600 billion yuan, with a two-year compound annual growth rate (CAGR) nearing 40%. Inference computing has become the primary driver of AI computing investment.
Unlike the training market, which is dominated by a few leading vendors, the inference market features fragmented scenarios, diverse demands, and higher cost sensitivity, offering more opportunities for second-tier domestic vendors.
China's inference computing market is now stratified: Huawei Ascend dominates high-end training and inference with its complete ecosystem and cluster capabilities; Cambricon has solidified its position in mid-to-high-end inference and industry-specific private deployments through years of technical accumulation.
Meanwhile, general-purpose GPU vendors like Iluvatar CoreX and Moore Threads are targeting the massive general-purpose inference market with more flexible architectures and better cost-performance ratios.
As orders from top internet companies materialize, second-tier vendors' production capacity and technical iteration speeds will enter a virtuous cycle, gradually narrowing gaps between tiers.
New Phase for Domestic GPUs: Coexistence of Multiple Approaches + Ecosystem Competition
Domestic GPUs are unlikely to achieve full substitution through single-point breakthroughs. A more realistic path involves gradually capturing market share in specific scenarios, workloads, and customer segments.
Inference is one of the most promising directions for domestic chips. Training large models imposes extreme demands on chip performance, cluster communication, and software maturity, leaving little room for customer error.
Inference scenarios are more diversified, allowing segmentation by model size, task type, latency requirements, and cost sensitivity. Domestic chips that demonstrate stability, affordability, and adequacy in certain tasks can be integrated into large enterprises' heterogeneous computing pools.
Future large-model infrastructures will unlikely rely on a single chip type. Cloud training, high-concurrency inference, edge AI, enterprise privatization, industry-specific small models, and agent task scheduling will demand different chip forms.
Long-term coexistence of GPUs, ASICs, NPUs, and CPUs with hybrid scheduling will prevail. What domestic GPU companies must truly compete for is securing critical positions in this heterogeneous computing landscape.
Epilogue:
China's path to computing autonomy will only truly solidify after domestic GPUs withstand traffic tests from hundreds of millions of users. The 50,000-chip order marks not an endpoint but the starting point of domestic inference chips' real-world deployment.
Over the next one to two years, more local chips will cross scalability thresholds, building China's computing industry ecosystem through real-world business refinement.
Partial References: 21st Century Business Herald: 'Behind the 50,000 GPU Chip Procurement: Domestic Giant Iluvatar CoreX Emerges,' Yicai: 'ByteDance Increases Procurement of Domestic Chips as Internet Giants Race to Build Computing Moats,' Guosheng Securities: 'Iluvatar CoreX: Steady GPU Generation Evolution, Commercial Landings Gain Momentum,' Changjiang Securities: 'In-Depth Study of Iluvatar CoreX: Timing Favors Domestic GPU Breakthroughs'
-
![]()
MathWorks: Generative AI Holds Great Potential, Yet a Trusted Toolchain is Essential for Flawless Operation
-
![]()
Small Earphones, Big Business
-
![]()
Volkswagen Slashes 100,000 Jobs, Mercedes-Benz Axes Year-End Bonuses: What’s Ailing German Auto Titans?
-
![]()
Doubao Can No Longer Offer Free Services to 345 Million Users: China's Era of Free AI Is Drawing to a Close
-
![]()
How Can Chinese Small Home Appliances Conquer Southeast Asia Through 'Dimensional Competition'?
-
![]()
Why are top intelligent driving players betting on reinforcement learning?
-
![]()
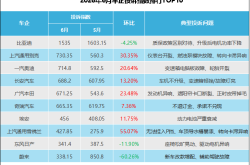
June 2026 Automobile Complaint Index Rankings: Persistent Problems Ignite Grievances Among Long-term Vehicle Owners
-
![]()
Avita Takes Another Stab at HKEX Listing: Facing the Urgency of Sustaining Operations Amid 11.2 Billion Yuan Loss Over Three Years