What technology enabled XPENG to eliminate LiDAR from its intelligent driving systems?
 05/13 2026
05/13 2026
 378
378
In October 2024, XPENG Motors announced a major technological decision at its 1024 Tech Day, stating that future new models would fully eliminate LiDAR and switch entirely to a pure vision-based intelligent driving solution. This transition was subsequently implemented in models such as the XPENG P7+, MONA M03, new G6, G9, and X9. By 2026, XPENG had unified the intelligent driving systems of all its in-sale models under the pure vision approach. Moving from the industry's widespread hardware stacking to actively streamlining systems, where does XPENG's technological confidence come from?
Why does pure vision become even stronger when computing power is sufficient?
The fundamental principles of the pure vision solution dictate that its demand for computing power is far higher than that of LiDAR-based systems. LiDAR directly outputs 3D point cloud data, providing the system with pre-structured spatial information. In contrast, pure vision systems only receive 2D images and must infer the depth, shape, and motion states of the 3D world from them. This process of reconstructing 3D information from 2D data (Related Reading: How to elevate autonomous driving scene understanding from 2D to 3D?) is essentially a massive mathematical problem requiring extremely strong parallel computing capabilities.
In a 2025 interview, He Xiaopeng directly explained the reasons for the technological shift. Previously, the poor performance of pure vision systems was mainly due to insufficient computing power. The visual system lacked both sufficient pixel resolution and adequate frame rates and spatiotemporal logic. With a significant boost in computing power, this issue has been resolved. This was not a gradual improvement but a qualitative leap from infeasibility to feasibility.
Why is computing power so critical? This can be understood through a specific scenario. When a vehicle travels at 60 km/h, it advances approximately 17 meters per second. The pure vision system must complete the following tasks within that second: acquire high-resolution images from multiple cameras, establish temporal correlations across frames, convert 2D pixels into 3D objects and navigable areas, judge the motion intentions of various objects, generate a safe driving trajectory, and then output steering angle, throttle, and brake commands. If this entire process exceeds 100 milliseconds, the vehicle will have moved nearly two meters—a potentially fatal distance in complex driving conditions.
The early advantage of LiDAR systems stemmed from their ability to bypass the step of inferring 3D information from images, directly providing the system with relatively accurate spatial information and reducing reliance on computing power. However, when onboard computing power becomes sufficiently large, the indirect approach of pure vision becomes advantageous because it processes rawer and richer information without the simplifications of LiDAR point clouds, theoretically enabling the recognition of more object types and scenarios.
XPENG's approach to the pure vision solution involves deploying far more onboard computing power than the industry mainstream. Taking the new XPENG P7 as an example, it is equipped with three self-developed Turing AI chips, delivering an effective computing power of 2250 TOPS for the entire vehicle. In this configuration, two chips drive the intelligent driving VLA large model, while the third collaborates with the Qualcomm 8295P chip to drive the cabin large model.
For comparison, most competing models in the same price range currently offer intelligent driving computing power ranging from a few dozen to several hundred TOPS. Even the XPENG MONA M03 Max version, starting at 129,800 RMB, is equipped with a single Turing chip providing 750 TOPS of computing power. For its Robotaxi solution, XPENG deploys four Turing chips, achieving 3000 TOPS of onboard computing power and providing hardware headroom for L4-level capabilities.
What's the difference between developing your own chips and buying off-the-shelf chips?
The computing power gap is just the surface; the deeper reason for XPENG's choice of pure vision lies in the changed nature of the chips. XPENG completed the tape-out of its self-developed Turing AI chip in August 2024 and achieved mass production in the second quarter of 2025. The significance of this chip extends beyond being a faster Orin—it represents a different design philosophy.
NVIDIA's Orin series follows a general-purpose computing approach, essentially serving as an automotive GPU that provides standardized computing power, with automakers deploying their algorithms independently. The advantage of this model lies in its mature ecosystem, comprehensive software support, and adaptability to multiple automakers. However, its disadvantage is that computing power utilization efficiency is constrained by its general-purpose nature, as some computing resources are allocated to tasks not actually needed for intelligent driving.
In contrast, XPENG follows an algorithm-defined chip approach, designing the chip architecture based on its intelligent driving algorithm requirements. The Turing chip adopts DSA (Domain-Specific Architecture), with each computing unit customized around XPENG's end-to-end perception and decision-making models. According to XPENG's internal calculations, the Turing chip's effective computing power is nearly ten times higher than that of the previous-generation Orin chip. XPENG claims its computing power utilization rate can approach 100%, a feat difficult to achieve with general-purpose chips, which often have significant idle computing power when handling non-AI tasks.

Image Source: Internet
The DSA architecture offers another crucial advantage: power efficiency control. A single Turing chip consumes about 30W, with a three-chip cluster totaling 80-100W. In comparison, a three-Orin-X system consumes about 120W, meaning the Turing chip reduces power consumption by approximately 20% at the same computing power level. For electric vehicles, every watt of power saved by the intelligent driving system directly translates into increased driving range.
Beyond power efficiency, the Turing chip's memory configuration is specifically optimized for end-to-end large models. A single Turing chip is equipped with 64GB of LPDDR5X memory, with a three-chip cluster sharing 216GB of system memory and a bandwidth of 273GB/s. XPENG has confirmed that the Turing chip supports running large models with up to 30 billion parameters locally. This is a critical metric because the parameter count of intelligent driving models has grown dozens of times over the past two years and continues to increase. If the chip does not support sufficiently large local memory, models must be compressed or sliced for operation, which affects inference accuracy.
More interestingly, XPENG's three-chip cluster solution simultaneously handles AI computing for both intelligent driving and the cabin, eliminating the physical isolation between intelligent driving and cabin chips in traditional architectures. Approximately 1800 TOPS are allocated to intelligent driving, while 400 TOPS support the cabin's visual language model. Using the same hardware to drive two systems simplifies the vehicle's electrical architecture and reduces the chip's marginal cost.
Developing self-designed chips requires extremely high investment, often costing hundreds of millions of dollars upfront—a major strategic decision for an automaker with annual deliveries of less than 300,000 units. However, XPENG's logic is that only by equipping all models with this chip can costs be amortized and capabilities strengthened. The Turing chip has already been implemented across models ranging from the 120,000 RMB MONA M03 to the entire lineup. This means XPENG's pure vision solution not only eliminates the hardware cost of LiDAR but also achieves further cost reductions by replacing purchased chips with self-developed ones.
Without LiDAR, how can cameras perform just as well?
While computing power and chips address the "brain" issues, the "eyes" themselves must also be highly capable. One of the biggest challenges for pure vision systems is perception under extreme lighting conditions. In scenarios with strong backlighting, low light, or tunnel entrances/exits, traditional automotive cameras often suffer from overexposure or underexposure, resulting in significant loss of image information. LiDAR, which does not rely on ambient light, indeed has a natural advantage in such scenarios.
XPENG addresses this challenge with its AI Hawk Eye vision solution. The key technological highlight of this system is the adoption of LOFIC architecture cameras (Related Reading: How does LOFIC technology overcome perception bottlenecks in pure vision autonomous driving under complex lighting?). LOFIC, or Lateral Overflow Integration Capacitor, places a high-density capacitor beside each photodiode in the image sensor. When strong light causes the photodiode to generate more electrons than it can hold, the excess electrons flow into the adjacent capacitor instead of being discarded. This significantly increases the camera's dynamic range, allowing it to retain more details in scenes with both strong light and shadows.
This technology was first applied in Honor smartphones, and XPENG is the first to introduce it to the automotive industry. Under complex conditions such as nighttime, strong backlighting, or rainy/snowy weather, this vision solution performs even more clearly than the human eye. Data shows that compared to the previous-generation vision system, the Hawk Eye solution with LOFIC architecture increases real-time perception distance by 125%, recognition speed by 40%, and reduces system latency by 100 milliseconds.
Improvements in perception hardware must be combined with perception algorithms to be effective. At the algorithmic level, XPENG was the first in China to mass-produce an end-to-end intelligent driving large model in 2024. This model consists of three parts: the vision perception neural network XNet, the planning large model XPlanner based on neural networks, and the large language model XBrain.
XNet is the most critical module in the pure vision solution. It integrates dynamic XNet, static XNet, and the pure vision 2K occupancy network, using over 2 million grids to perform highly realistic 3D reconstruction of navigable space in the real world. The occupancy network refers to the system directly dividing 3D space into navigable and non-navigable regions rather than first identifying specific objects before determining navigability. This approach excels at handling novel obstacles not present in training data, as the system only needs to recognize that an object occupies space without identifying what it is (Related Reading: Why does the occupancy network make autonomous driving perception more precise?).
XBrain introduces the reasoning capabilities of large language models, enabling the system to understand abstract information such as tidal lanes, pending turn zones, and road sign text. Traditional solutions rely on high-definition maps to annotate and recognize such complex scenarios. XBrain allows the system to make correct driving decisions based solely on visual signals, even in areas completely lacking high-definition maps.
These three modules work together to form a complete chain from perception to understanding and from understanding to decision-making. In 2026, XPENG further introduced the second-generation VLA large model, which eliminates the intermediate translation steps between vision, language, and action in traditional architectures, enabling direct generation of driving actions from visual signals and reducing decision latency to under 80 milliseconds. In the first month after the second-generation VLA's rollout, the number of human interventions per 100 kilometers decreased by 25.87% month-over-month.

Image Source: Internet
Why are data and training systems more important than hardware stacking?
While computing power, chips, and perception hardware determine whether a system can function, the upper limit of an intelligent driving system depends on the scale and quality of its training data. The pure vision solution relies far more on data than LiDAR-based systems. While LiDAR can at least rely on hardware to provide fallback performance in extreme cases, pure vision depends entirely on algorithms learning from data to understand the world.
XPENG has built a complete training and data system spanning from cloud to vehicle, known as the Cloud Model Factory. This system covers the entire workflow of pre-training and post-training for foundation models, model distillation, vehicle-end model training, and deployment. The cloud training infrastructure consists of a compute cluster with tens of thousands of cards, delivering 10 EFLOPS of computing power reserve and maintaining cluster utilization above 90% year-round, with an average iteration cycle of five days across the entire link .
What does a five-day iteration cycle mean? Under traditional intelligent driving development models, after algorithm teams modify a model, it typically takes weeks or even months to complete a full round of training, testing, and validation. A five-day iteration cycle means XPENG's models can absorb new driving scenario data at a much faster pace, continuously improving performance. For frequently used routes, the system can even achieve personalized optimization for thousands of users.
XPENG's world foundation model under training has 72 billion parameters. This is a multimodal large model with a language model as its backbone network, possessing visual understanding, chain-of-thought reasoning, and action generation capabilities. Through reinforcement learning training, this foundation model can continuously self-evolve, aiming to handle full-scenario autonomous driving problems, including long-tail scenarios never encountered in training data.
A 72-billion-parameter foundation model obviously cannot be directly deployed on vehicle-end systems. Even though the Turing chip's memory configuration supports running 30-billion-parameter models locally, it cannot accommodate such a massive model. XPENG's solution is cloud distillation: training an extremely capable ultra-large model in the cloud and then compressing it into a smaller model suitable for vehicle-end computing resources through distillation techniques before deploying it to vehicles.
Distillation is not simply about reducing parameters but involves a sophisticated training process aimed at preserving as much of the large cloud model's capabilities as possible in the smaller vehicle-end model. If the cloud foundation model is likened to an experienced professor, the distilled vehicle-end model resembles a strictly trained driver capable of independently handling various road conditions. This architecture maintains a lightweight vehicle-end model while continuously approaching the performance ceiling of the cloud model.
In simulation, XPENG has developed the world model X-World, a controllable multi-view generative model built on video diffusion generation technology. Given historical video streams and driving actions, it can generate corresponding future multi-camera video streams. Simply put, it is a physical world simulator capable of imagining road changes seconds into the future, widely used in the research, development, and validation of the second-generation VLA for environmental simulation and model evaluation. To improve simulation efficiency, XPENG released the X-Cache technology in April 2026, boosting the world model's inference speed by approximately 2.7 times.
With cloud training and simulation validation in place, the remaining question is data sourcing. Where does the data come from? From vehicles driving at scale. By the time the second-generation VLA was released, XPENG's intelligent driving system had been trained on video data equivalent to over 1 billion kilometers. In May 2026, one month after the second-generation VLA's rollout, the proportion of intelligent driving miles among users exceeded 50% for the first time, meaning over half of all miles driven by XPENG owners were completed by the intelligent driving system.
This figure also means XPENG collects massive amounts of high-quality data from actual driving every day, which continuously feeds back into model training and iteration. More data leads to stronger models; stronger models encourage greater user reliance on intelligent driving; greater usage generates even more data. This positive feedback loop forms the fundamental strategic logic behind XPENG's shift to pure vision.
-- END --
-
![]()
Auto China 2026: Chinese Brands Lead the Green and Smart Future | Cover Story: In China, for the World – Auto China 2026 Special Report (Part 3)
-
![]()
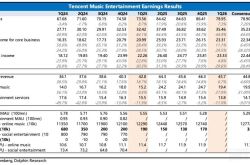
Can Tencent Music Win This Defensive Battle by Integrating Himalaya?
-
![]()
Volvo Asia Pacific: No More 'Successor' Era!
-
![]()
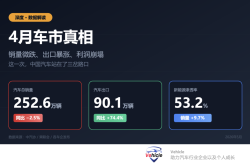
China's Auto Market in April: A 2.5% Sales Decline, a 74% Export Surge, and Profit Margins Below 3.5%
-
![]()
Toyota's Era of Sky-High Profits Draws to a Close
-
![]()
Can Trump Pave the Way for Chinese Automobiles in the US Market with Musk’s China Visit?
-
![]()
Can the New Unisplendour Group Break Away from Being a 'Huawei Alternative' After Resolving Its Hundred-Billion-Yuan Debt?
-
![]()
What technology enabled XPENG to eliminate LiDAR from its intelligent driving systems?