What Are the Technical Differences Between XPENG and Tesla in Pure Vision Intelligent Driving?
 05/25 2026
05/25 2026
 389
389
In the technical path of autonomous driving, pure vision has always been a crucial direction. In previous content, we explored the technical confidence behind XPENG's shift to pure vision (Related Reading: What Technology Enabled XPENG to Abandon LiDAR?) and discussed Tesla's FSD V14.3 upgrade (Related Reading: Tesla FSD V14.3: Letting AI Drive Directly?). As pure vision intelligent driving systems, do XPENG and Tesla differ technically?
Is End-to-End the Only Solution?
The challenge for pure vision solutions is reconstructing 3D world information from 2D images to make driving decisions. Traditional approaches divide tasks into independent modules like perception, prediction, planning, and control, with each module passing processed data. This method offers clear structure and ease of debugging but inevitably loses some raw information at each stage and requires engineers to manually code rules for various scenarios—an impossible task given countless abnormal road conditions. With technological advancements, end-to-end solutions have been applied, with both Tesla and XPENG adopting this approach in their pure vision systems.
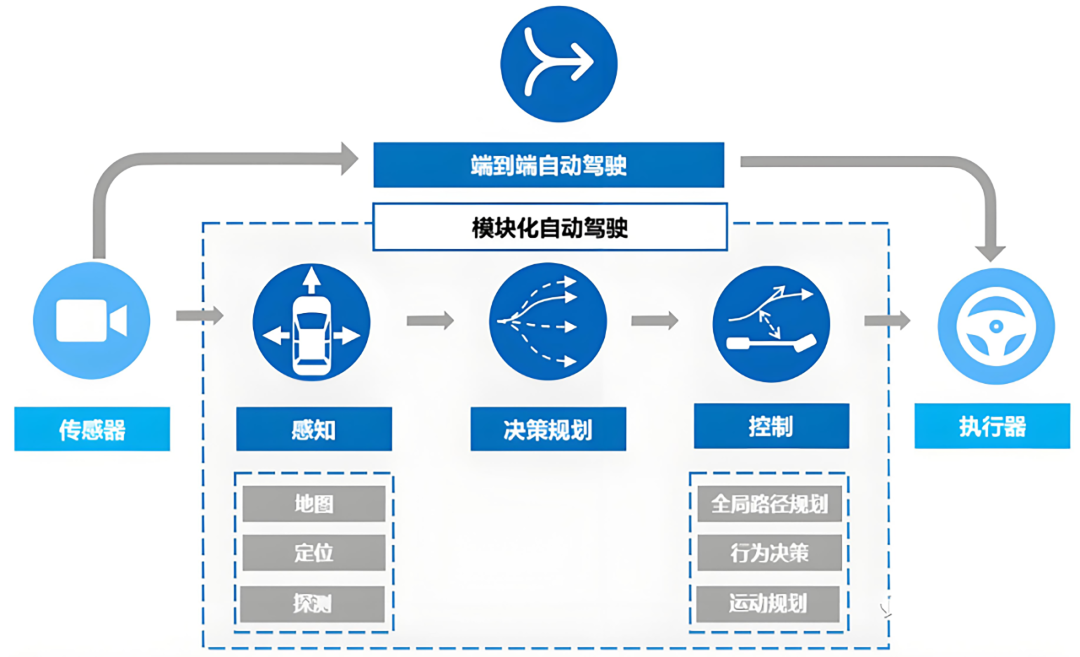
Image Source: Internet
Tesla pioneered simplification with FSD V12, integrating the entire process from perception to control into a unified neural network. From camera input to steering and brake commands, a single model handles everything. This skips all intermediate steps, allowing the model to learn directly from massive driving videos what actions to take for given visual inputs. After V13, Tesla introduced temporal processing capabilities, enabling vehicles to remember surrounding objects' trajectories over the past dozen seconds. Even if pedestrians are temporarily obscured, the system infers their current position and intent based on pre-disappearance speed and direction.
XPENG took a different path, using three independently trained neural networks in its end-to-end solution: XNet for visual perception, XPlanner for trajectory planning, and the large language model XBrain for scene understanding and decision-making. Each has distinct responsibilities and connects via internal interfaces. This design allows independent module optimization, simpler debugging, and enables XBrain to leverage language models' generalization capabilities for uncommon scenarios like tidal lanes, ETC lanes, and road sign text.
By late 2025, XPENG advanced further with its second-generation VLA (Vision-Language-Action) large model, abandoning previous multi-module intermediaries and directly generating driving commands from visual signals, architecturally approaching Tesla's single-stage end-to-end approach. However, their understandings of the core concept—world models—remain different, the next topic for discussion.

Image Source: Internet
Same Term, Two Interpretations
World models represent a key technical direction in current autonomous driving, referring to systems' internal reconstruction of road environments before making driving decisions. Both Tesla and XPENG pursue this but differ significantly in implementation.
Tesla's approach is more implicit. Within FSD, the Occupancy Network divides the 3D space around the vehicle into countless tiny cubes, with the neural network judging whether each cube is occupied, moving, or belongs to a specific object type. This method's core advantage is independence from object recognition—whether facing standard vehicles, overturned trucks, or scattered cargo, all spatial entities are marked.
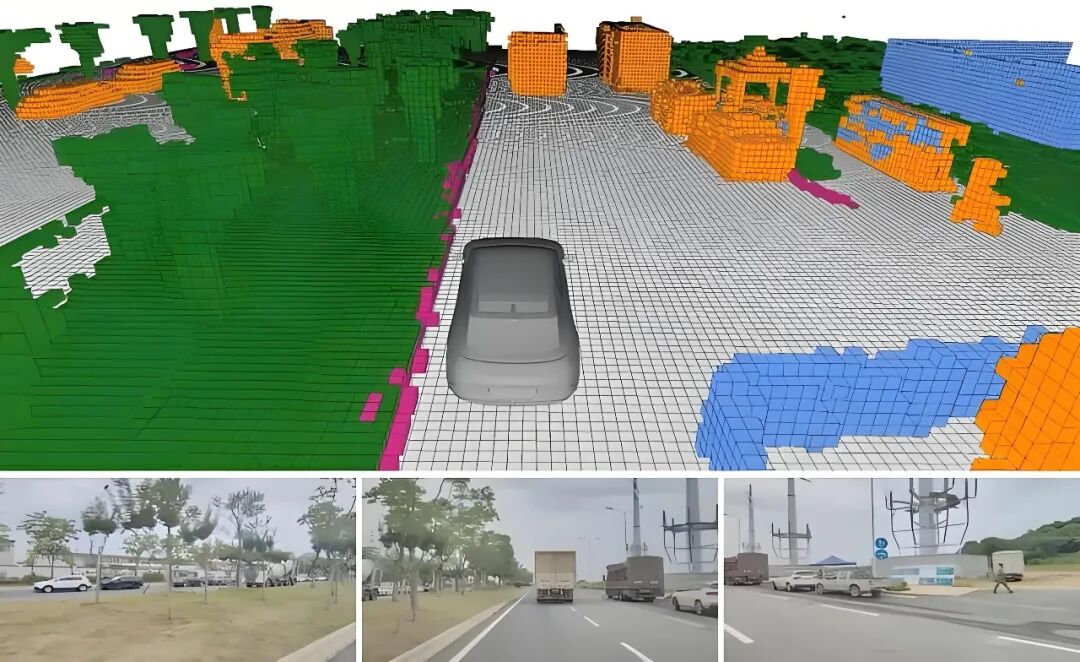
Image Source: Internet
In 2025, Tesla filed a patent for a higher-precision Occupancy Network, refining spatial division from ~30cm grids to ~10cm grids, enabling more accurate reconstruction of ground markings and parking lines in low-speed scenarios like parking lots (Related Reading: Is Finer Perception Network Always Better for Autonomous Driving?). These spatial data directly inform end-to-end model decisions as invisible intermediate states to drivers.
XPENG proposes the concept of a physical world large model. Its second-generation VLA not only outputs driving actions but also explicitly models the environment, generating world model representations. XPENG emphasizes this as a native multimodal large model handling visual, auditory, and textual information simultaneously, applicable across vehicles, robots, and flying cars. With 72 billion parameters, nearly 100 million video clips in training data, and full-chain iteration every five days, combined with its self-developed Turing AI chip and customized compiler, the model achieves 12x inference efficiency improvement on vehicles.
Simply put, Tesla's world model resembles neural network internal states—intermediate decision products—while XPENG attempts to make world models a reusable universal foundational capability.
Seeing Farther vs. Seeing Finer
Perception forms the foundation of pure vision solutions. Both XPENG and Tesla adopt BEV (Bird's Eye View) + Transformer architectures (Related Reading: What Exactly Are BEV + Transformer in Autonomous Driving?), fusing multi-camera inputs into a top-down 3D spatial understanding before decision-making. However, they differ in implementation details.
Tesla consistently uses eight cameras for 360° coverage, with 36Hz full-resolution input on AI4 hardware. The Occupancy Network's voxel judgments eliminate reliance on predefined whitelists for obstacle identification, offering strong generality.
XPENG specifically enhances perception precision. Its AI Hawk Eye vision system employs Lofic technology cameras for clearer imaging in low-light and backlight scenarios (Related Reading: How Does LOFIC Technology Overcome Perception Bottlenecks in Complex Lighting for Pure Vision Autonomous Driving?). Its mass-produced 2K pure vision Occupancy Network reconstructs 3D space with over 2 million grids, achieving 5cm³/voxel modeling precision. Compared to Tesla's current ~30cm voxel resolution, XPENG offers finer perception details, distinguishing road cracks from potholes.
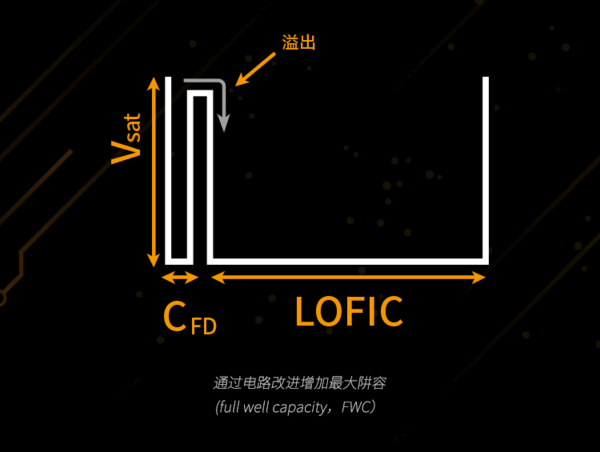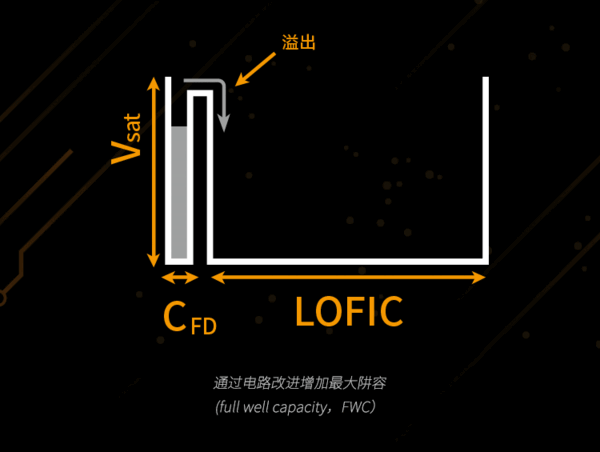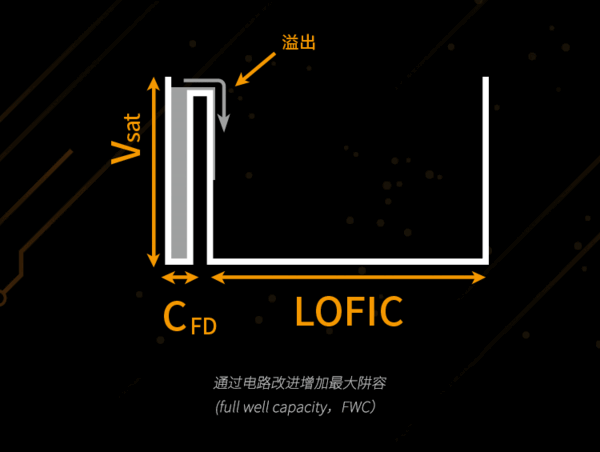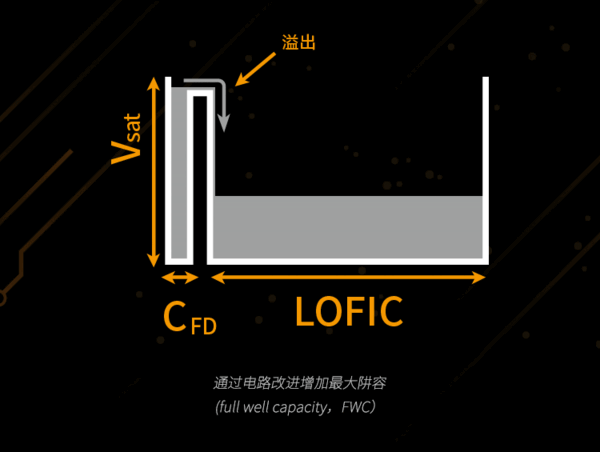
Image Source: Internet
Additionally, XPENG's XNet architecture integrates dynamic BEV, static BEV, and Occupancy Network systems, handling moving object prediction, static environment structural understanding, and spatial occupancy judgment within a unified framework. In contrast, Tesla's dynamic object prediction and static occupancy judgments derive from different output dimensions within the Occupancy Network—not three separate networks—but functionally correspond.

Two Data-Driven Strategies
Data and computing power are lifelines for pure vision solutions, with all technical architectural differences ultimately reflected in data effectiveness.
Tesla's strength lies in data scale. By late 2024, FSD had accumulated over 2 billion kilometers of driving data, far exceeding comparable systems. Its global fleet encounters diverse traffic environments and edge scenarios.
In training strategy, Tesla made significant adjustments recently, building a cloud-based world model to mass-generate synthetic driving data, which it mixes with a proportion of real-world data to train new FSD models. This approach rapidly covers rare long-tail scenarios like extreme weather and uncommon accident patterns, also supporting distributed computing platforms integrating training and inference for future AI5/AI6 chips.

Image Source: Internet
XPENG has accumulated relatively less mileage but iterates rapidly, relying on video training data equivalent to over 1 billion kilometers, enabling its end-to-end model to iterate about every two days. The second-generation VLA processes ~50PB of visual data, handling ~5.3 billion bytes of information per second.
Notably, XPENG's model focuses on Chinese road scenarios, with deeper training coverage for complex conditions like mixed pedestrian-vehicle traffic, non-motorized vehicle weaving, and narrow streets. Real-world testing shows the second-generation VLA demonstrates localized advantages in stability and handling for uniquely Chinese scenarios like narrow roads and complex interactions.
In contrast, although Tesla has established a data center in Shanghai, its core algorithms remain North America-led, with slower actual iteration speeds in China compared to North American versions. It still shows adaptability issues for scenarios like food delivery rider weaving and complex mixed lanes.
Final Thoughts
To summarize the differences between these two pure vision solutions: Tesla employs a highly integrated neural network, using massive global data and minimalist architecture to let models learn driving autonomously, with world models embedded in neural network weights. XPENG evolves from modularization toward a more unified architecture, achieving finer perception precision and deeply optimizing for complex Chinese road scenarios while attempting to build world models as a reusable universal capability layer. These two routes converge technically at the foundation but remain architecturally distinctive.
-- END --
-
![]()
Inside Look at 'RedSkill': Is Xiaohongshu Emerging as the Premier AI App Store?
-
![]()
The Ultimate Showdown in Handheld Smart Imaging: DJI's Ecosystem Moat and Insta360's Risk of Falling Behind
-
![]()
Organizational Groundwork in the AI Age: Time for Enterprises to Reassess DingTalk, Feishu, and WeCom
-
![]()
Ningde Is Being ‘Urged’ by Automakers to Invest in DeepSeek
-
![]()
In-Depth Analysis of the EU's Industrial Accelerator Act: Rewriting the 'Game Rules' for China's Auto Industry Going Global
-
![]()
The Pivotal Gamble of Li Auto L9: Is It Merely a Car or a Futuristic Robot?
-
![]()
What are the ways AI Coding is reshaping the software industry?
-
![]()
What Are the Technical Differences Between XPENG and Tesla in Pure Vision Intelligent Driving?