6x Ultra-Rapid Generation of Endless Portrait Videos! Fudan & Microsoft's Latest FlashPortrait: Empowering You to Be the Person Behind the Digital Mask
 12/25 2025
12/25 2025
 556
556
Interpretation: The Future of AI-Generated Content 
Key Highlights
- Introduced an adaptive latent prediction acceleration mechanism based on sliding windows. This method requires no additional training, is activated only during inference, and achieves a 6x acceleration while maintaining identity consistency in portrait animations of infinite length. It marks the first study to delve into video diffusion models for accelerating the generation of identity-preserving portrait animations of infinite length.
- Devised a novel normalized facial expression module to align the distribution centers of diffusion latent variables and facial features, bolstering identity stability during the denoising process.
- Experimental results on multiple benchmark datasets showcase that our model outperforms current state-of-the-art methods.
In domains such as filmmaking, virtual assistants, and live-streaming e-commerce, portrait animation technology relentlessly pursues the ultimate goal of "infinite duration, high fidelity, and identity stability." With the advent of diffusion models, audio-driven or video-driven portrait generation technologies have made significant strides. However, existing solutions grapple with irreconcilable core contradictions: either limited generation duration (leading to body distortion and identity drift beyond 20 seconds) or sluggish inference speed (taking several minutes to generate a 20-second video), severely hindering industrial deployment. Current diffusion model-based portrait animation technologies exhibit three major flaws under the demands of long duration, high-speed inference, and high consistency:
- Lack of identity consistency: Excessive discrepancies in the distribution centers of diffusion latent variables and facial expression features result in issues such as facial distortion, color drift, and blurred identity characteristics in generated videos.
- Slow inference speed: Traditional diffusion models necessitate completing the full denoising process frame by frame, often consuming tens of minutes to generate a 20-second video, making it challenging to meet real-time application scenarios.
- Abrupt long video transitions: When employing segment cutting and stitching or simple sliding-window strategies, transitions between video segments are abrupt, lacking smoothness and coherence. Existing acceleration schemes (e.g., cache reuse, knowledge distillation) are either applicable only to minor motion scenes or entail significant computational costs, and fail to address identity drift in long videos.
Thus, developing a portrait animation framework that harmonizes speed, duration, and consistency has become an urgent industrial imperative.

To tackle these challenges, research teams from Fudan University, Microsoft, and Xi'an Jiaotong University proposed the FlashPortrait framework, achieving a 6x inference acceleration for the generation of portrait videos of infinite duration. The code is now open-source, encompassing both inference and training code.
Method Overview
As depicted below, FlashPortrait is developed based on the Wan2.1-14B base model, constructing a comprehensive technical route of "feature alignment-smooth transition-high-speed generation" through three core technical modules.
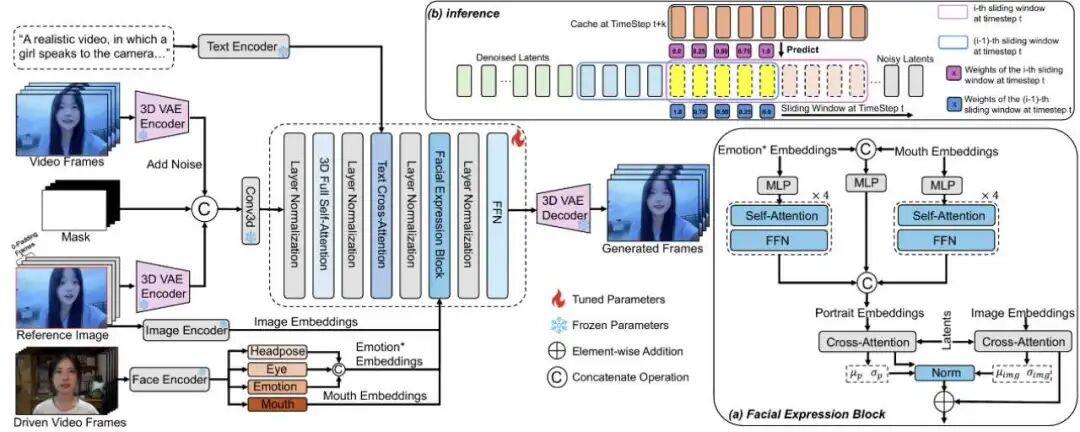
1. Normalized Facial Expression Block (NFEB)
To address identity drift caused by discrepancies in the distribution of diffusion latent variables and facial features, FlashPortrait designs a normalized facial expression module. Leveraging distribution alignment techniques, it achieves precise control over cross-frame identity consistency. Specifically, it initially extracts native facial expression features such as head pose, eye movements, emotional states, and mouth motions from the driving video using a pre-trained facial encoder (PD-FGC). It then enhances the perception of the overall facial layout through a self-attention mechanism and feedforward network (FFN). Subsequently, it calculates the mean and variance of the processed expression features and diffusion latent variables, aligning their distribution centers through normalization to eliminate identity instability caused by distribution differences. The normalized facial features are then fused with the CLIP-encoded features of the reference image through cross-attention and injected into the diffusion model via element-wise addition, ensuring precise preservation of facial details and identity characteristics during generation.
2. Weighted Sliding-Window Strategy (WSWS)
Long videos are segmented into multiple overlapping windows, with the overlap length set to v (v=5), ensuring partial shared frames between adjacent windows. Arithmetic interpolation weights are applied in the overlapping regions to perform weighted fusion of latent variables from adjacent windows. The fused latent variables are then reintroduced into adjacent windows, rendering the window boundaries composed of mixed features. This approach circumvents abrupt transitions at segment junctions and achieves smooth, coherent generation of long videos.
3. Adaptive Latent Prediction Acceleration (ALPA)
To surmount the speed bottleneck of frame-by-frame denoising in traditional diffusion models, FlashPortrait innovatively proposes an adaptive latent prediction acceleration mechanism, achieving a 6x inference speed through higher-order derivative prediction to bypass redundant denoising steps. Initially, it employs Taylor series expansion to approximate future latent variables based on the higher-order differences of historical latent variables, where complex derivative calculations are substituted with finite differences to reduce computational costs. To address issues of large facial motion amplitudes and intense latent variable fluctuations in portrait animation, two dynamic adjustment functions are designed: (1) Latent variable change rate function, which dynamically adjusts the prediction step size based on the ratio of the current time step's latent variable change speed to the average change speed, averting prediction distortion during large motions. (2) Cross-layer derivative weight function, which dynamically adjusts weights based on the derivative magnitude differences across diffusion layers, resolving prediction errors between low-level texture features and high-level structural features. Through this prediction mechanism, the diffusion model only needs to perform complete denoising on a few key time steps to directly predict latent variables for multiple future time steps, ultimately bypassing redundant denoising steps and achieving a 6x inference acceleration.
Generation Result Examples 


Experimental Comparison 

Conclusion
FlashPortrait, equipped with meticulously designed training and inference mechanisms, can generate portrait animations of infinite length with identity-preserving characteristics and achieves up to a 6x acceleration in inference speed. FlashPortrait initially extracts identity-independent facial expression features using existing mature models. To enhance identity stability, the model introduces a normalized facial expression module to optimize expression features. During inference, to ensure smoothness and identity consistency in long videos, FlashPortrait proposes a weighted sliding-window strategy. Within each contextual window, an adaptive latent prediction acceleration mechanism is further introduced to bypass partial denoising steps, achieving a 6x inference acceleration. Experimental results on multiple datasets demonstrate that our model holds significant advantages in synthesizing portrait animations of infinite length with identity preservation, along with a substantially improved inference speed.
References
[1] FlashPortrait: 6 × Faster Infinite Portrait Animation with Adaptive Latent Prediction
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






