AWS S3 Vectors Now Fully Operational: Achieving Query Latency Under 100 Milliseconds
 01/06 2026
01/06 2026
 604
604
AWS has recently made an official announcement regarding the complete rollout of its cloud object storage service, S3 Vectors.
This service is designed to inherently support the storage and querying of vector data. With its official launch, the capacity of a single index has been significantly boosted, now being 40 times larger, enabling it to store up to 2 billion vectors. Moreover, it guarantees query latency of less than 100 milliseconds.
The service underwent a preview phase earlier this year in July. AWS reported that during this preview, users generated over 250,000 vector indices and processed in excess of 40 billion vectors. It's worth noting that the single-index capacity was capped at 50 million vectors during the preview. AWS Chief Developer Sebastian Stromacq remarked:
"Now, a single index can handle the storage and retrieval of up to 2 billion vectors... This allows users to consolidate all their vector datasets into one index, eliminating the need to manage multiple smaller indices through sharding or complex federated query logic."
Furthermore, the service has seen enhancements in query performance. Low-frequency queries can now yield results within 1 second, while high-frequency queries maintain latency below 100 milliseconds. This is particularly beneficial for interactive applications, such as conversational AI.
According to official data, a single query can retrieve up to 100 results at most, significantly improving the contextual quality of retrieval-augmented generation (RAG) applications. Regarding write performance, the service supports up to 1,000 PUT operations per second for single-vector updates, facilitating small-batch, high-throughput writes and enabling real-time retrieval of new data from multiple concurrent sources.
AWS has also announced the full launch of two key integrations following their preview periods. Users can now leverage S3 Vectors as the vector storage engine for Amazon Bedrock's knowledge base. Additionally, its integration with Amazon OpenSearch has officially gone live, allowing users to utilize S3 Vectors as the underlying vector storage layer while conducting searches and analyses with OpenSearch.
Developer Jalaj Nautiyal commented on LinkedIn, stating, "S3 Vectors has transitioned vector search from a 'compute-first' approach to a 'storage-first' solution. This 'serverless' shift means users no longer need to manage clusters, containers, or shards. They can manage vectors like ordinary S3 objects, easily achieving storage for billions of vectors."
In terms of cost, it is anticipated to reduce the total cost of ownership by up to 90%. Users will only need to pay for S3 storage fees (which are relatively low) and query fees, without incurring costs for idle computing resources.
He further emphasized that for 80% of internal RAG applications and autonomous agent scenarios, there may be no need to seek out top-tier vector databases. A reliable and infinitely scalable 'trunk' will suffice—S3 is emerging as such an option.
Currently, S3 Vectors is accessible in 14 AWS regions (up from 5 during the preview phase). Service pricing is determined based on three factors:
Upload pricing: Charged based on the logical GB volume of vectors uploaded by users (each vector encompasses logical vector data, metadata, and key-value pairs).
Storage cost: Depends on the total logical storage volume of each index.
Query fees: Include the cost per API call and a per TB data query fee based on the index size (excluding non-filterable metadata).
As the cornerstone of AWS's data ecosystem, S3 Vectors has achieved seamless integration with both the Amazon Bedrock knowledge base and Amazon OpenSearch services. This implies that users can directly reap the benefits of managed vector storage when constructing RAG applications.
When establishing a knowledge base in Amazon Bedrock, S3 Vectors can be chosen as the vector storage option. This integration presents four major advantages:
Cost savings for RAG applications utilizing large vector datasets.
Effortless integration with Amazon Bedrock's fully managed RAG workflow.
Automated vector management handled by Amazon Bedrock services.
Sub-second query latency for knowledge base retrieval operations.
Amazon Bedrock's knowledge base offers a fully managed end-to-end RAG workflow. When creating a knowledge base with S3 Vectors, Amazon Bedrock automatically retrieves data from S3 data sources, converts the content into text chunks, generates embeddings, and stores them in a vector index. Subsequently, the knowledge base can be queried, and responses can be generated based on the chunks retrieved from the source data.
References:
https://docs.amazonaws.cn/en/AmazonS3/latest/userguide/s3-vectors-bedrock-kb.html
https://www.infoq.com/articles/xb5VDXD96B8sdi8dcqp0/
-
Toyota May Surpass GM to Top US Sales Rankings
-
![]()
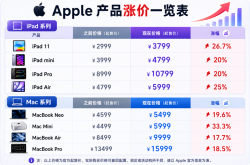
Breaking News! Apple Implements Sharp Price Hikes in the Dead of Night, Scalpers Go on a Stockpiling Spree, iPhone 18 in Jeopardy
-
![]()
Upgraded Wenxin and Paid Doubao: AI Bids Farewell to the 'Traffic-Only' Era
-
![]()
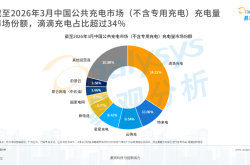
Users Vote with Their Feet, Propelling Didi Charging to Industry Leadership
-
Why Are Chinese Tech Companies Frequently Embroiled in Patent Litigation? Here’s the Real Story!
-
![]()
[Exclusive] Numerous BMW i3 and i4 EV Owners Receive Battery Replacement Alerts, Some After Just 8,000 Kilometers. BMW Attributes It to a System Glitch.
-
![]()
Nandu Puts ‘Gaokao Direct Train’, ‘Sunshine Gaokao Volunteer Filling Guide’, ‘Reliable AI’, ‘Xing Volunteer’, ‘Jiashu AI Volunteer’, and ‘Diebian Volunteer’ to the Test
-
![]()
Limits Can't Stop It! China's Electric Vehicle Supply Chain Infiltrates Indian Market: Pressure Mounts on Japanese Automakers