Challenging NVIDIA's Computational Hegemony? A Toronto Startup 'Etches' Large Models into Chips
 02/27 2026
02/27 2026
 659
659
Is it a Breakthrough or a Futile Attempt?
In Silicon Valley's current grand narrative, computational power is synonymous with authority.
NVIDIA's GPUs seem to be the sole, albeit expensive, ticket to AGI. As the entire industry fervently stacks 'bigger, pricier, and more power-hungry' GPU clusters, a highly disruptive rebellion in underlying technology is quietly unfolding in the shadows.
Recently, Taalas, a Toronto-based startup founded less than three years ago, unveiled a plan (plan) that has turned heads in the semiconductor and AI industries: they have directly 'hardwired' Meta's Llama large model into an ASIC (Application-Specific Integrated Circuit) chip. This is not a routine hardware process upgrade but a violent reconstruction at the physical level.
Led by Ljubisa Bajic, the former co-founder of Tenstorrent, this team of engineers no longer relies on expensive HBM memory and has abandoned liquid cooling: the model no longer runs as software code on general-purpose hardware, nor does it require frequent throughput of hundreds of gigabytes of weight data from high-bandwidth memory (HBM). The massive neural network structure and billions of parameters of Llama are directly solidified into physical circuits, becoming the chip itself—the chip is the model, and the model is the chip.
On this chip, fabricated using TSMC's 6-nanometer process and spanning an area of 815 square millimeters, a single user's inference throughput for Llama 3.1 8B reaches a staggering 17,000 tokens per second. For comparison, this speed is dozens of times faster than NVIDIA's top-tier GPUs and hundreds to thousands of times faster than human reading or thinking speeds. Generating a detailed month-by-month chronicle of World War II takes only 0.138 seconds.
Is this counterintuitive technological approach the ultimate breakthrough to shatter computational bottlenecks, or is it a futile attempt to 'carve a mark on a moving boat' by ignoring the laws of model iteration?
I. The Pendulum of History
The Long-Standing Plague of the 'Memory Wall'
Taalas's radical attempt stems from a hidden ailment in the current AI industry: the memory wall.
Since the birth of computers, the cornerstone of the entire industry has been the 'von Neumann architecture,' which inherently separates computation and storage: when computation is needed, data is fetched from the background to the stage, and then moved back after calculation.
This architecture worked well when models were only a few megabytes or tens of megabytes in size. However, as large language models swell to hundreds of billions or even trillions of parameters, this classic architecture is becoming the biggest stumbling block. When GPUs run large models for inference, they do not spend most of their effort on computation but are forced to become a frantic 'mover'—vast amounts of model weight data shuttle back and forth between memory and compute units, with up to 80% of power consumption and latency wasted on this physical data movement. This has not only created NVIDIA's vast moat but has also directly propelled the skyrocketing prices of HBM memory chips. The AI industry has long suffered from the 'memory wall,' which keeps AI inference costs high and turns data centers into power-hungry behemoths.
Taalas's ASIC approach is essentially a complete evasion of this 'computational tax.' When model weights no longer exist as data in memory but become solidified transistor states, the act of data movement is physically erased.
II. Absolute Speed and the 'Electronic Workhorse'
The Scenario Value of Commercial Deployment
The most direct consequence of Taalas breaking through the memory wall is a terrifying gap in cost and energy efficiency.
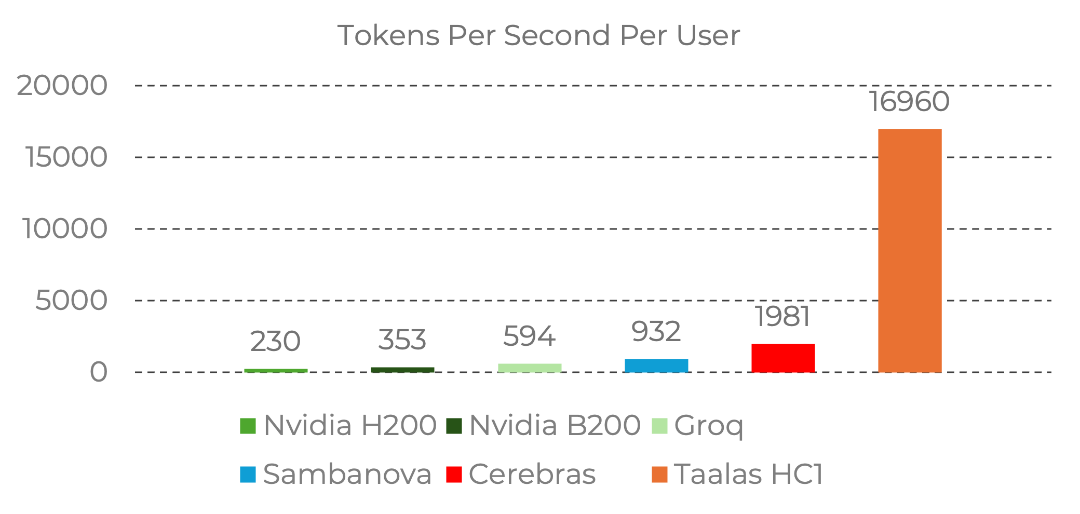
Traditional GPU data centers are veritable 'power hogs,' often requiring liquid cooling. In contrast, Taalas's HC1 chip consumes only about 250W per chip. Even when deploying 10 chips, the total power consumption is just 2.5 kilowatts, allowing stable operation with conventional air cooling. According to Taalas's official and industry estimates, the inference cost per million tokens is only around $0.0075, one-twentieth or even lower than traditional GPU solutions. In today's industry, where 'speed is king' and 'cost reduction and efficiency enhancement' are ironclad laws, the impact of this data needs no further elaboration.
From an engineering perspective, this is clearly an astonishing leap in efficiency; yet, in today's era of rapid model iteration, a chip that cannot be updated or run other models sounds like a joke. However, if we step outside the grand narrative of 'creating an omniscient AGI' and look at the vast array of commercial vertical scenarios, we may find that this 'solidification' is not a flaw but rather the optimal solution for certain scenarios.
In the real commercial world, not all scenarios require a GPT5 or even newer model that understands quantum mechanics and can write Shakespearean sonnets. Most scenarios need an extremely stable, cheap, blazingly fast, and tireless 'electronic workhorse.'
Imagine millisecond-level visual defect recognition on industrial assembly lines, an absolutely zero-latency voice hub in smart cars, or hundreds of millions of home companion robots or children's toys... In these scenarios, companies do not care whether you can compatible (be compatible with) the latest large model frameworks; what they care about is: Can you accomplish this specific task at lightning speed for a few cents?
Taalas's HC1 is precisely designed to solve this 'large-scale single task.' When applied to voice assistants at 17,000 tokens per second, AI responses will be faster than human neural reflexes, and the spinning 'waiting for LLM to think' animation will become a thing of the past. A large model that once required hundreds of watts and had to be plugged into a liquid-cooled server may soon fit into a robot vacuum, a smartphone, or even a pair of lightweight AI glasses with just a few watts of power. True 'AI in everything' will only be possible after computational power and power consumption are drastically compressed.
III. The Hidden Concerns of a Futile Attempt
Wisdom 'Frozen' in Chips
Nevertheless, given the rapid evolution of current AI algorithms, the other side of Taalas's risky approach cannot be ignored. Solidifying fluid software code into cold physical circuits means sacrificing flexibility. There are two extremely sharp real-world mismatches here.
The first is the mismatch in iteration cycles. Today, open-source large models evolve on a 'monthly' or even 'weekly' basis. However, an advanced-node chip typically takes 18 to 24 months from architectural design to tapeout and final mass production. By the time it rolls off the production line, the Llama model it has 'frozen' may already be a outdated 'relic' in the ever-changing world of algorithms.
The second is the mismatch in fault tolerance. If a large model develops severe hallucinations or security vulnerabilities, it can be quickly fixed through fine-tuning or OTA patch deployment. However, how do you patch a chip with physical circuits already etched? Once a model solidify (solidified) in a chip has a fatal flaw, the entire batch of expensive chips will likely become silicon waste.
Taalas has also proposed defense strategies against these fatal commercial risks. First is the retention of fine-tuning capabilities. While the HC1 locks down the base weights, it still supports low-rank adaptation (LoRA) fine-tuning. This means companies can attach small 'knowledge patches' externally to the physical large model to adjust performance for specific tasks. Second is rapid physical iteration. Taalas's CEO revealed that changing the model does not require redesigning the entire underlying silicon but only modifying the top two metal layers of the chip. This manufacturing process innovation compresses the hardwareization cycle of new models to an astonishing two months, enabling minor model iterations.
Even so, this remains a high-stakes gamble against time. In this game, Taalas is attempting to use the ultimate static nature of hardware to capture the ultimate dynamic nature of AI algorithms, inevitably carrying a tragicomic 'carving a mark on a moving boat' undertone.
IV. The Butterfly Effect
Who is Trembling, Who is Rejoicing?
Despite its obvious limitations, the emergence of Taalas's 'model-as-chip' approach has still torn a crack in NVIDIA's absolute monopoly.
NVIDIA's position owes much to its CUDA software ecosystem. Developers worldwide write programs in CUDA, turning hardware barriers into an impenetrable software ecosystem barrier. But what if the end of AI no longer requires software?
Taalas's approach means that in the inference market, which accounts for over 90% of future AI computational power, CUDA's moat is completely bypassed. Model training still relies on NVIDIA's GPUs, but in end-side and professional inference data centers where applications ultimately land, ASIC-specific chips are sparking a 'de-NVIDIAization' uprising.
Moreover, as generative AI accelerates into commercial deployment, companies like Groq, Cerebras, and Etched are also exploring different avenues in Lightning-fast response (ultra-fast response), massive throughput, and specific algorithm acceleration, all potentially nibbling away at the inference market and shaking NVIDIA's once-impregnable empire.
At the same time, the storage giants' revelry may also cool down. Currently, HBM chips are the super money printers of the storage industry. However, if model weights are internalized into circuits, reliance on massive memory will drastically decrease. Once compute-storage separation architectures become widespread, storage manufacturers' expectations of windfall profits in the AI era will be greatly squeezed.
For this reason, Taalas etching large models into silicon is by no means the endpoint of AI computational power. In the near future, we may witness a clear divergence in the computational power market:
The cloud and training grounds will remain the domain of NVIDIA GPUs and general-purpose accelerators, used to explore the intellectual boundaries of AGI and handle the most complex and variable unknown tasks.
The end-side and assembly lines will be the vast ocean of 'physically hardened' chips like Taalas's. They will be as cheap as sand, as agile as light, and penetrate every streetlight, every home appliance, and every industrial robot.
Even further ahead, when quantum computing truly becomes practical or brain-inspired computing achieves breakthroughs, all our efforts today to break through the von Neumann architecture may become courageous yet slightly clumsy attempts in the annals of technology.
Conclusion
From 'Omnipotent Brain' to 'Hardware Instinct'
The evolution of computing architectures has never been a unidirectional straight line but a spiral ascent of polyphony. From early specialized punch card machines to general-purpose CPUs, to GPUs designed specifically for graphics processing, and now to AI ASICs, the history of computing has been a constant oscillation between 'general-purpose flexibility' and 'specialized ultimate efficiency.'
Taalas's exploration may seem radical today, even facing the dilemma of being 'outdated upon factory release,' but it poses a profoundly philosophical industry question:
What is the ultimate evolutionary form of AI?
Must it always remain a 'general-purpose software brain' as malleable as water?
Or, like biological evolution over billions of years, will AI internalize its most fundamental and mature intelligence (such as basic visual recognition, language logic parsing) into 'silicon-based hardware instincts' that require no thought and operate at extremely low power?
Looking back at the history of technology, any great paradigm shift often emerges amid controversy and high-stakes gambles.
Perhaps the future AI computing foundation will not be an either-or proposition. The cloud will remain a powerhouse of general-purpose GPU clusters, while at the edge of the Internet of Everything, countless low-power AI chips with 'instincts' solidified will proliferate.
When large models are no longer the exclusive flowers of the cloud but become as cheap and ubiquitous as resistors and capacitors, the true explosion of AI will finally begin.
END
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







