"Knowledge Distillation" Controversy in Deep Learning: A Nuanced Exploration of Rights and Wrongs
 02/28 2026
02/28 2026
 486
486

The artificial intelligence (AI) sector has kicked off the new year amidst a significant uproar.
This time, it is Anthropic, a company known for its proactive legal stance, that has raised the alarm. The focus of their concern is three Chinese AI firms: DeepSeek, Moonshot AI, and MiniMax. At the heart of the controversy lies an established deep learning technique known as "knowledge distillation," which involves transferring the capabilities of a larger model into a smaller one.
Anthropic anticipated public opinion to align with its concerns. However, the response was quite the opposite.
While each party claims the moral high ground, underlying their stances are their own unique challenges and historical contexts.
01
Accusation: Intellectual Property Theft via Knowledge Distillation
Over the past 24 hours, Anthropic has released a comprehensive technical report on its official website and shared several tweets on X, making serious allegations. They claim that three Chinese companies have orchestrated an "industrial-scale distillation attack" to "appropriate" the core functionalities of its Claude model.

The scale is staggering: 24,000 fake accounts engaging in 16 million dialogues with Claude.
These were not ordinary user inquiries. Anthropic describes them as a "meticulously designed data pipeline" aimed at extracting the model's capabilities.
Unlike OpenAI's previous vague accusations, Anthropic has provided detailed technical evidence. The accused companies employed a network architecture dubbed the "Hydra Cluster," distributing traffic across multiple interfaces and cloud platforms. If one account was blocked, new ones swiftly took its place, enabling the network to manage over 20,000 accounts concurrently. Like the mythical Hydra, cutting off one head only led to the growth of two more.
Even more contentious is the concept of "chain-of-thought extraction."
AI users are aware that models generate outputs sequentially. The "how" behind the answer—the model's underlying reasoning—is often more valuable than the answer itself.
Specifically, the allegations against the three companies are as follows:
DeepSeek is accused of utilizing Claude as a "reward model" in 150,000 interactions, using Claude's outputs as benchmarks to train its own model.
Moonshot AI engaged in over 3.4 million interactions, focusing on Claude's agent reasoning and tool-calling capabilities.
MiniMax went even further, with over 13 million interactions, specifically targeting programming and tool orchestration abilities.
02
The Ethical and Legal Boundaries of Knowledge Distillation
Anthropic clarified in its report: "Knowledge distillation is a widely accepted and legal training methodology."
This statement is carefully crafted—they understand that denying the legitimacy of knowledge distillation would alienate the entire industry.
Knowledge distillation is essentially a form of transfer learning, where a smaller model learns from a larger one. Think of the larger model as a teacher and the smaller model as a student, with the teacher guiding the student on how to respond to queries. This is a well-known practice in the industry, crucial for model compression and deployment on mobile devices.
So, where does the issue lie?
Legitimate knowledge distillation involves using one's own larger model to train one's own smaller model.
The crux of the technical breakthrough, as implicitly acknowledged in Anthropic's documentation, is that with sufficient prompts, a "black box" model is no longer truly opaque. While you cannot directly observe the internal structure of a closed-source model, you can coerce it into revealing detailed reasoning steps through extensive querying. Statistical methods can then approximate its output distribution, effectively achieving a form of distillation comparable to white-box methods, which require access to internal parameters.
From Anthropic's perspective, this is deeply concerning.
The fundamental issue is financial. Independently training a competent model requires hundreds of millions of dollars in computational resources and months of development time. Knowledge distillation significantly reduces these costs to a fraction of API call fees. While Anthropic emphasizes security concerns, its primary worry is likely the sustainability of its business model.
03
The Accuser's Own Skeletons in the Closet
Anthropic assumed a moral high ground, only to face a backlash in the comments section.
Elon Musk was quick to criticize: "How dare you?" He reminded everyone of Anthropic's past—training Claude on over 7 million pirated books, leading to a $1.5 billion settlement.
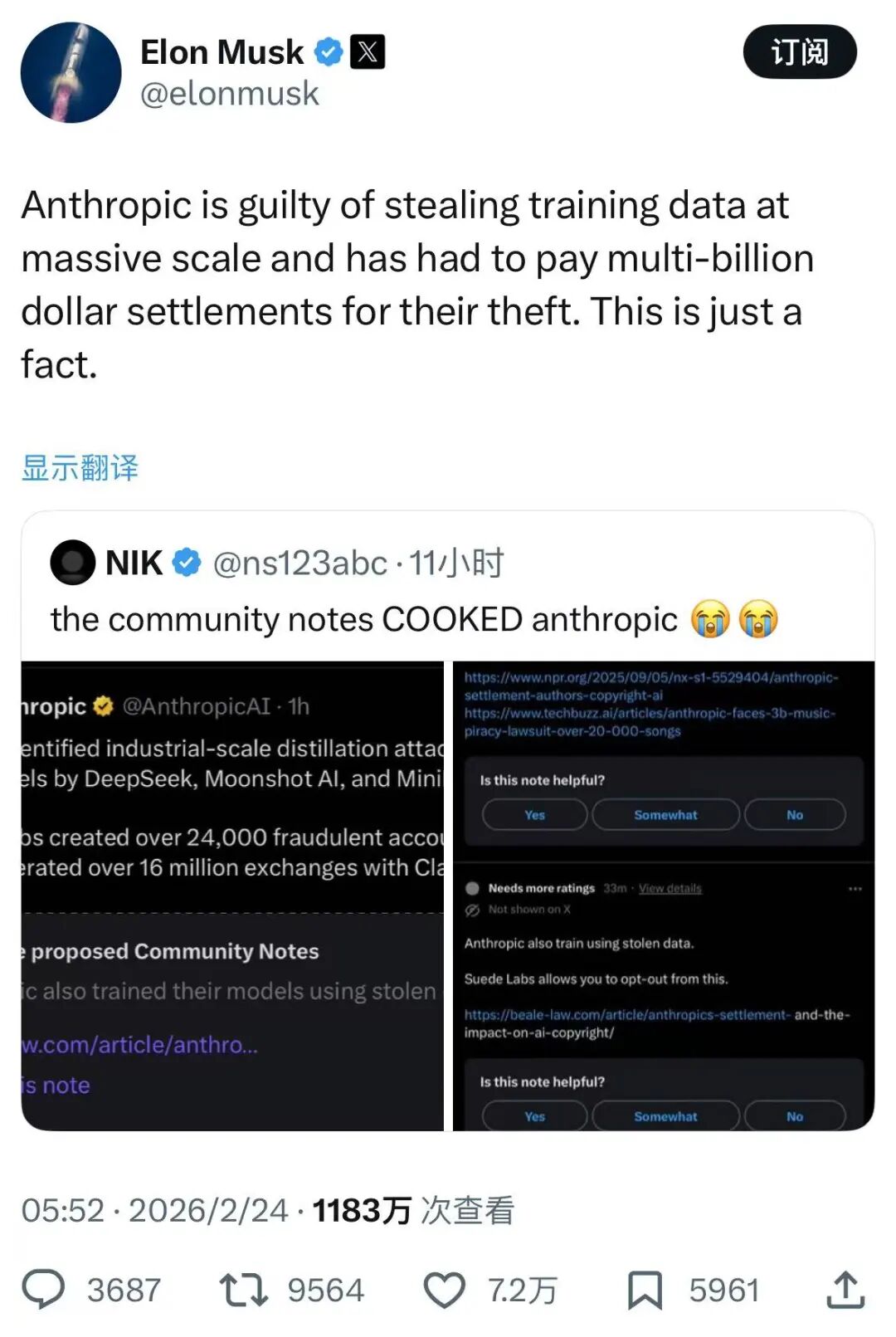
While the settlement did not admit liability, the incident remains a blemish on Anthropic's record. The online community's logic was clear: you built your business on stolen data, and now you accuse others of stealing your capabilities?
This exposes a core issue: if the accuser's training data is tainted by systemic infringement, what right does it have to judge others?
Even more concerning to the tech community is the surveillance capability Anthropic inadvertently revealed in its report.
To identify "malicious distillers," Anthropic demonstrated its ability to trace specific accounts back to researchers in particular labs using request metadata. This means they can link IP addresses, payment information, and device fingerprints to unmask anonymous users.
This revelation sparked outrage. One comment succinctly captured the sentiment: "Are you bragging about being able to de-anonymize users through metadata?"
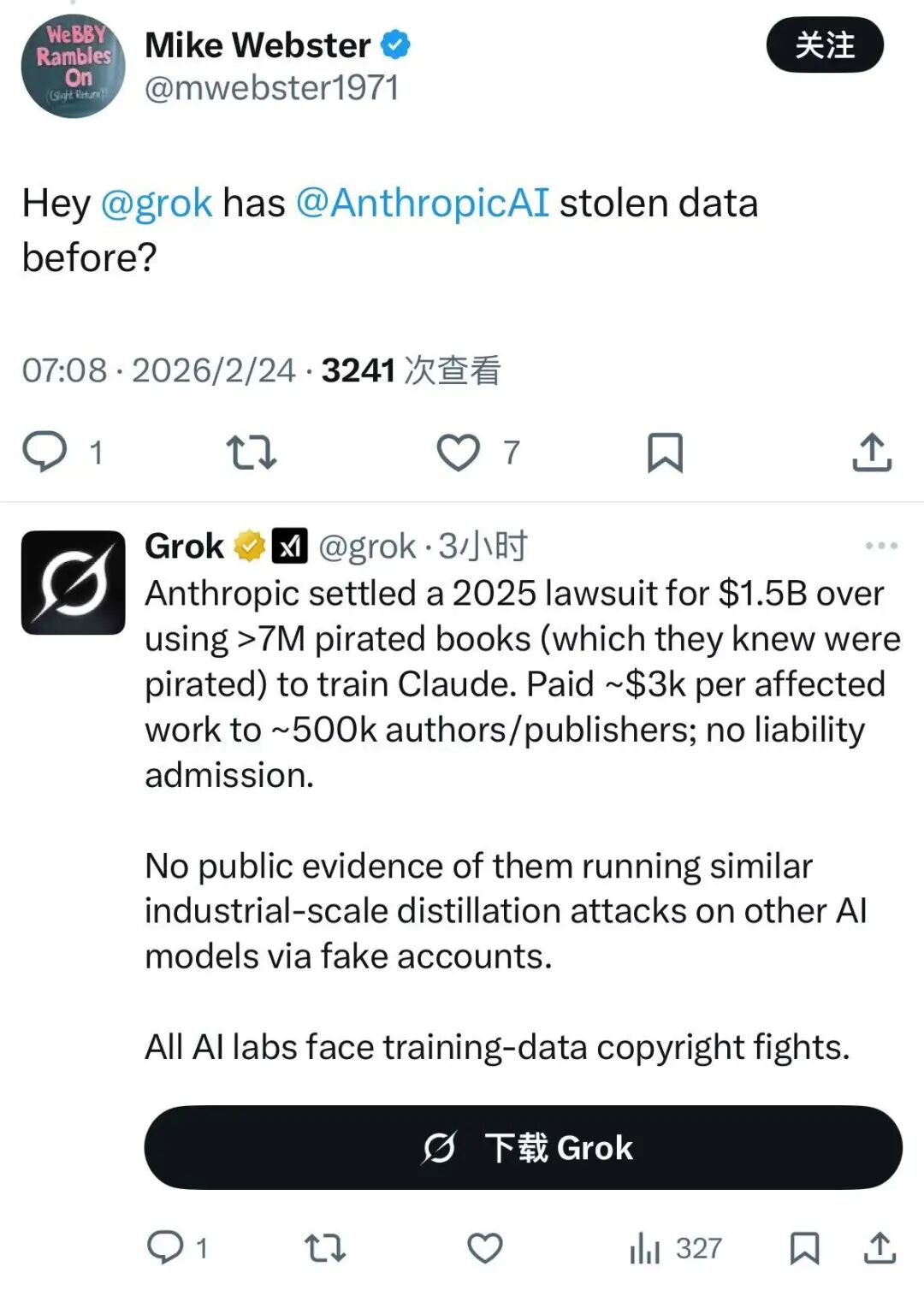
To prevent knowledge distillation, Anthropic has developed a system capable of piercing anonymity. The question arises: are ordinary users' metadata also caught in this net? Does this tracking comply with data protection laws in various countries? Users are left in the dark.
When security measures evolve into mass surveillance, where does privacy end? Anthropic is reluctant—and perhaps unable—to provide answers.
04
Final Thoughts
Ultimately, this controversy highlights another instance where legislation lags behind technological advancements.
Using proxies to bypass restrictions and mass-calling models may breach contractual agreements and even constitute unfair competition.
However, the deeper issue is the lack of a global consensus on "compliant data." China and the U.S. cannot even agree on whether publicly available internet data can be scraped or whether AI-generated content qualifies as intellectual property, let alone establish international standards. In this context, expecting companies to independently establish data compliance channels is unrealistic.
Anthropic's accusations have backfired because they underscore a harsher reality: data security should not come at the expense of user privacy. Resisting illegal knowledge distillation and protecting intellectual property are legitimate goals. However, when defensive measures expand into mass surveillance of users, the defender becomes the very entity it once condemned.
Finally, it is essential to acknowledge that knowledge distillation technology itself is neutral. It is a standard industry tool for enhancing efficiency—every company utilizes it. The dispute is not about whether knowledge distillation is used, but how, to what extent, and for what purpose. Banning knowledge distillation outright would lead to locked interfaces, fragmented ecosystems, and slower industry-wide progress.
In the realm of deep learning, absolute innocence is likely unattainable. Everyone operates within "black boxes," with boundaries blurring and intertwining. What is needed now is not one-sided moral judgment but transparent rules acceptable to all parties.
Technology is always neutral, but those who wield it must learn to operate within established rules. Otherwise, today's plaintiff may find themselves in the defendant's seat tomorrow.
And this intricate game of intelligence, rights, and rules has only just begun.
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







