Can Pure Vision Autonomous Driving Systems Detect Highly Transparent Glass Walls?
 02/28 2026
02/28 2026
 588
588
Recently, when discussing whether pure vision autonomous driving systems can recognize 3D objects, some friends inquired about their ability to detect highly transparent glass walls. Today, Intelligent Driving Frontier will briefly delve into this topic with everyone.
Before delving into today's subject, it's important to clarify that the likelihood of encountering a highly transparent glass wall directly in front of a vehicle under normal driving conditions is extremely low. If it does occur, it would be considered a rare edge case. Today's discussion will focus solely on analyzing the technical feasibility of pure vision autonomous driving systems in recognizing highly transparent glass walls.
In urban architectural design, transparent glass walls are prevalent in shopping malls, office buildings, and various public spaces due to their aesthetic appeal and transparency. However, this material, which is visually appealing to humans, poses a significant challenge for autonomous driving perception systems.
For pure vision autonomous driving systems, which rely solely on cameras and exclude LiDAR, accurately detecting highly transparent glass walls is a major test of the underlying computer vision logic.
Physical Barriers and Optical Illusions in Visual Perception
To understand the ability of pure vision systems to detect glass, we must first grasp the physical nature of light-glass interaction. The high transparency of glass is due to its extremely high transmittance of visible light, meaning only a very small portion of light undergoes diffuse reflection and returns to the camera sensor.
Traditional computer vision algorithms interpret an image based on changes in pixel brightness and color. If a region lacks distinct texture, color differences, or edge features, the algorithm perceives it as an open space.
Humans identify glass by observing subtle reflections, fingerprints, oil stains, or even slight refraction displacements of objects behind the glass when shifting their gaze. In contrast, pure vision systems must employ highly complex mathematical models to reconstruct these subtle visual cues.
Glass processes light according to the laws of reflection and refraction. When light transitions from air into a glass medium, the proportion of reflected light is significantly influenced by the angle of incidence, as described by the Fresnel equations. At certain angles, specular reflection becomes pronounced, creating 'virtual images' that can confuse perception systems.
For pure vision autonomous driving systems, these virtual images are highly misleading. The system may misinterpret reflections of shopping mall chandeliers or moving pedestrians on the glass surface as real physical objects ahead, triggering unnecessary emergency braking.
If light completely passes through the glass, traditional monocular or binocular depth estimation techniques will incorrectly assign the depth value to background objects behind the glass, causing the vehicle's calculated 'drivable space' to erroneously include the glass wall itself. This failure in depth perception is a direct cause of potential collision accidents.
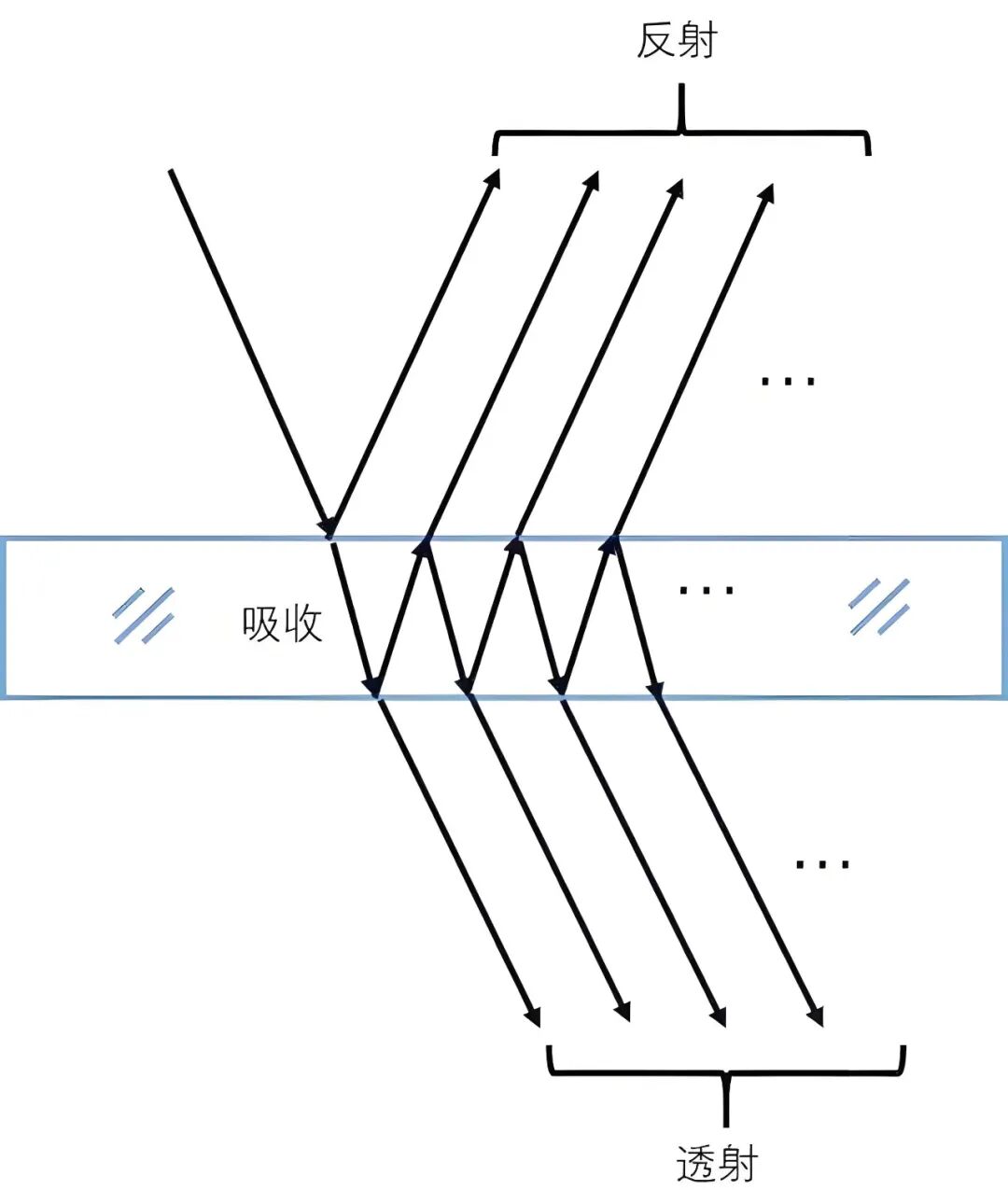
Image source: Internet
In indoor environments with complex artificial lighting, such as shopping malls, the direction and intensity of light vary dramatically, making the reflection patterns on glass surfaces even more unpredictable. Pure vision systems cannot rely solely on traditional feature point matching in these scenarios.
Due to the lack of texture on glass surfaces, feature matching algorithms struggle to find sufficient anchor points in the image to construct a 3D spatial structure. This can lead to significant errors, ranging from centimeters to even decimeters, in judging obstacle distances during low-speed cruising or parking.
To compensate for this limitation, the technical approach must shift from 'object detection' to 'environment understanding.' By analyzing associated structures around the glass wall, such as floor seams, ceiling edges, and wall surface continuity, the system can indirectly infer the presence of a transparent plane.
Evolution from Feature Recognition to Spatial Occupancy Networks
Early autonomous driving algorithms primarily relied on object detection models, which identified specific objects (such as cars, pedestrians, and traffic signs) in images and assigned them 3D bounding boxes.
However, glass walls, as non-standardized architectural elements with variable forms and lacking fixed classification features, pose a challenge for this 'box-based' detection logic when dealing with transparent obstacles.
The emergence of occupancy networks has shifted the focus of pure vision autonomous driving towards a more fundamental spatial representation.
Occupancy networks divide the 3D space around a vehicle into billions of tiny voxels. Instead of attempting to define 'this is a glass wall,' the system predicts whether each voxel is occupied by matter or empty.
This shift from 'object-centric' to 'space-centric' thinking provides a novel approach to recognizing transparent objects. Even if the glass itself is invisible, if light passing through the region exhibits unnatural refraction patterns or if cross-validation from multiple camera perspectives reveals physical exclusivity in the 3D coordinate system, the occupancy network will probabilistically increase the occupancy weight of that voxel.
In pure vision architectures, Transformer models play a pivotal role. Since glass recognition heavily relies on global context, the attention mechanism of Transformers allows the system to simultaneously observe every pixel in the image and establish long-range associations.
For instance, when the system observes that the tile texture on the ground exhibits mirror symmetry along a vertical line or that the ceiling lines bend slightly due to refraction in mid-air, the Transformer can aggregate these subtle, scattered anomalies across the image and deduce the presence of a planar transparent medium ahead.
To achieve high-precision recognition, occupancy networks from companies like Tesla have achieved sub-voxel-level refinement. When processing narrow spaces like parking lots or shopping malls, the system can dynamically increase the default voxel resolution from 33 centimeters to 10 centimeters or even lower.
This level of detail enables the algorithm to capture information about the thin frames or sticker thicknesses at the edges of glass. In this way, glass walls that were visually 'invisible' are reconstructed as a set of physically meaningful spatial barriers in the system's digital model.
This probabilistic modeling approach, while computationally more demanding than traditional algorithms, endows pure vision systems with the ability to handle 'long-tail scenarios' (extremely rare cases), enabling vehicles to make correct obstacle avoidance maneuvers based on physical space occupation logic when encountering unfamiliar glass designs.
This technological evolution also brings a profound change: the management of 'uncertainty.' When perceiving glass, autonomous driving systems often receive conflicting signals, such as geometric ranging indicating an open path ahead while semantic reasoning suggests the presence of glass.
Current pure vision frameworks have introduced probabilistic distribution predictions. Instead of providing a definitive 'yes or no,' the system outputs a distribution model containing mean and variance.
If the variance is too high, it indicates that the system lacks confidence in its judgment of that region. In such cases, the decision-making layer will trigger a conservative strategy, reducing speed or prompting the driver to take over.
This 'self-awareness' of the system's own perceptual limitations is a key indicator of the maturity of pure vision solutions.
Collaborative Reasoning of Motion Parallax and Semantic Context
When dealing with stationary transparent glass, single-frame images provide insufficient information for pure vision systems. To simulate human behavior of moving their heads to confirm glass positions, autonomous driving systems incorporate motion parallax and structure-from-motion techniques.
As the vehicle moves, the cameras capture a continuous stream of images. According to geometric optics, objects closer to the camera displace faster in the image than distant background objects.
For glass walls, although the main body is transparent, surface reflections, dust, or fingerprints produce unique displacement patterns as the vehicle moves.
By analyzing the displacement differences between these reflective points and background objects, the algorithm can calculate the depth of the glass plane. This method, known as 'parallax analysis,' is fundamental for pure vision systems to acquire distance information without relying on LiDAR.
When processing glass walls with frames, structure-from-motion techniques can track the trajectories of frame feature points across multiple frames and reverse-engineer the camera's motion trajectory and the obstacle's 3D coordinates. This process involves extensive matrix operations aimed at finding an optimal spatial model that explains all pixel displacements.
Semantic context is another powerful reasoning tool for recognizing highly transparent glass walls. For example, in shopping mall environments, the presence of glass walls follows certain architectural patterns.
Glass doors are typically embedded between solid walls, or storefront windows are located at the junctions of marble floors. Through deep learning training, the perception system can acquire these 'environmental common sense.' Semantic segmentation models classify pixels in the image into categories such as 'floor,' 'wall,' 'ceiling,' and 'potential transparent obstacle.'
If the system detects an interruption in the continuity of the floor at a certain point or regular distortion in the reflection of ceiling lights on the glass surface, the semantic model will label that region as 'high probability glass.'
This reasoning logic can even extend to analyzing 'absences.' If the vehicle's forward-facing camera detects rich background details along a certain path, but the side-facing cameras detect discontinuous image patches at the same location (due to refraction or reflection), the system will infer the presence of a transparent interfering source at the intersection of viewpoints. This cross-view collaborative verification significantly enhances the robustness of pure vision systems in complex indoor environments.
Perceptual Boundaries and Safety Redundancy Driven by Data
The upper limit of pure vision autonomous driving solutions heavily depends on the scale and diversity of their training data. For glass recognition, a task highly dependent on 'experience,' if the neural network has never encountered transparent objects under specific lighting or angles during training, it is highly prone to missed detections in real-world deployment.
To address this, some technical solutions attempt to use physically based rendering (PBR) to generate highly realistic synthetic data.
These simulated data can model not only perfect glass but also special transparent materials with cracks, stains, condensation, or varying refractive indices.
By generating tens of millions of video clips containing glass scenarios in simulators, models can learn extremely subtle optical features on glass surfaces under different natural and artificial lighting conditions.
This 'digital twin' training approach compensates for the scarcity of real-world data due to the vast variety of glass types and high collection costs.
Currently, publicly available datasets specifically targeting transparent objects, such as Trans10K and ClearGrasp, are driving improvements in algorithm accuracy.
The Trans10K dataset contains over 10,000 real-world images of transparent objects, with fine-grained annotations for 'things' (such as glasses and bottles) and 'stuff' (such as glass walls and windows).
The application of these datasets enables visual algorithms to achieve precise pixel-level segmentation of glass by learning the Fresnel effects at object edges and background distortions, with continuous optimization of metrics such as mIoU (mean Intersection over Union).
Final Thoughts
With the introduction of end-to-end (End-to-End) large models, autonomous driving will no longer break down glass recognition into separate steps like detection, tracking, and prediction. Instead, it will directly map raw pixels into driving actions.
In this mode, the system can develop a deeper understanding of causal relationships in the physical world, recognizing that an area that appears open actually has impassable physical resistance. This enhancement in cognition marks the transition of autonomous driving perception technology from mere mathematical simulation to more advanced AI reasoning.
-- END --
-
On the Eve of Its IPO, Avatr Finds Itself Embroiled in a 'Farce of Controversy and Belittlement'
-
![]()
Yutong Optics' Japanese Subsidiary Unveiled in Tokyo, Shifting Strategic Focus to Technology-Driven Growth
-
![]()
Half-Year Revenue Outstrips Last Year’s Total! Zhongrun Optics Forecasts 80.2% H1 Revenue Growth
-
![]()
Why Does AI Competition Start with Computing Power?
-
![]()
Apple AI Finally Makes Its Debut in China, Yet iPhone's 'AI Autonomy' Faces Uncertainty
-
![]()
Apple AI and QianWen Make Up Lessons: Alibaba Has Its Own 'Doubao Phone'
-
![]()
QianWen Joins Apple, Signal for Large Models to ‘Fade into the Background’
-
![]()
The ‘Anchor’ Strategy of Google Hidden Behind the Bleeding Financial Report






